
抓取网站数据使用xpath处理,但是出现了乱码的情况,在使用etree函数前打印处理啊是不乱码的。但是,使用etree解析之后获取数据就出现了乱码的情况,这是什么情况? 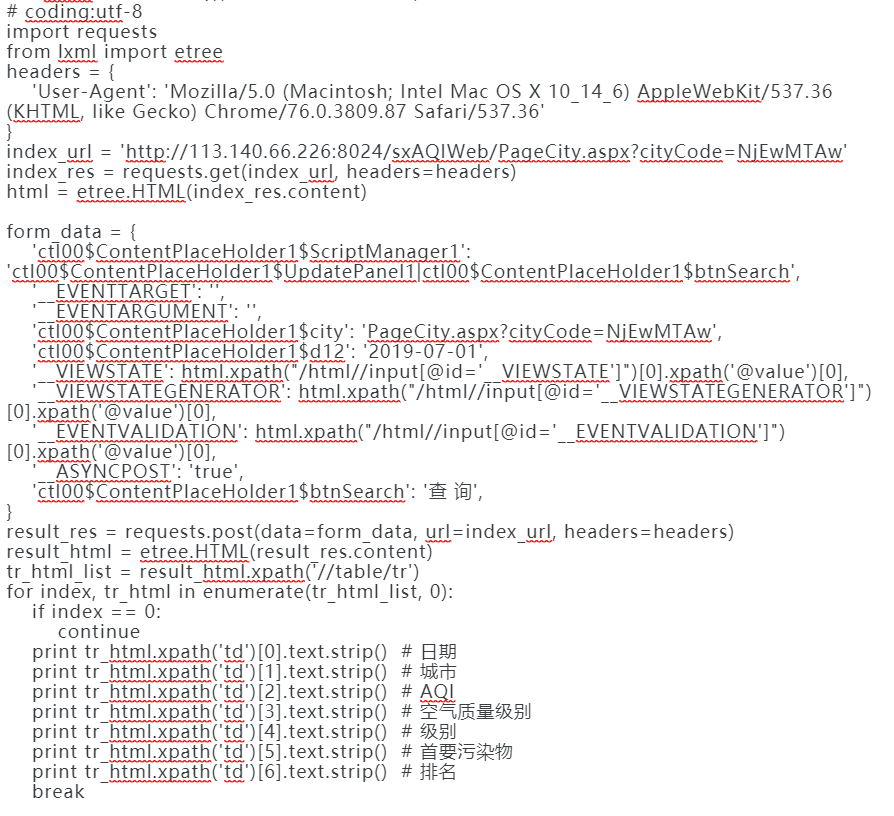
执行结果: 
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
问题描述: 您在使用XPath抓取网站数据时,遇到乱码问题。具体表现为,在使用etree函数进行解析之前,打印的数据正常无乱码,但经过etree解析后获取到的数据出现了乱码现象。
可能原因:
lxml.etree等库解析HTML/XML时,如果未显式指定正确的字符编码,解析器可能会按照默认编码(如UTF-8)处理非UTF-8编码的文本,导致乱码。解决步骤:
确定网页编码:首先,确认网页的实际编码。您可以通过检查网页源代码中的<meta charset="编码">标签来识别网页使用的字符集,或者使用开发者工具查看响应头中的Content-Type字段来获取编码信息。
显式指定编码:在使用etree.fromstring()或etree.parse()方法解析HTML/XML时,显式传递正确的编码参数。例如:
from lxml import etree
# 假设您已知网页编码为'gbk'
html_content = ... # 获取的网页内容
tree = etree.HTML(html_content, encoding='gbk')
统一编码处理:确保整个数据处理流程中,从获取、解析到存储或显示,所有环节都使用同一字符编码(推荐UTF-8),以避免编码转换过程中的乱码问题。
预处理乱码数据:如果已经获取到乱码数据且无法重新解析,尝试对数据进行解码再编码的转换操作,比如从错误的编码转换到正确的编码,但这种方法不一定总是有效,且可能进一步损坏数据。
注意事项:
通过上述步骤,您可以系统地定位并解决因编码不匹配导致的乱码问题。如果问题依旧存在,建议详细检查数据流中每个环节的编码设置,并考虑是否有其他外部因素影响。
