
 达达创立于2014年5月,业务覆盖全国37个城市,拥有130万注册众包配送员,日均配送百万单,是全国领先的最后三公里物流配送平台。 达达的业务模式与滴滴以及Uber很相似,以众包的方式利用社会闲散人力资源,解决O2O最后三公里即时性配送难题(2016年4月,达达已经与京东到家合并)。 达达的业务组成简单直接——商家下单、配送员接单和配送,也正因为理解起来简单,使得达达的业务量在短时间能实现爆发式增长。而支撑业务快速增长的背后,正是达达技术团队持续不断的快速技术迭代的结果,本文正好借此机会,总结并分享了这一系列技术演进的第一手实践资料,希望能给同样奋斗在互联网创业一线的你带来启发。 (本文同步发布于:
http://www.52im.net/thread-2141-1-1.html)
达达创立于2014年5月,业务覆盖全国37个城市,拥有130万注册众包配送员,日均配送百万单,是全国领先的最后三公里物流配送平台。 达达的业务模式与滴滴以及Uber很相似,以众包的方式利用社会闲散人力资源,解决O2O最后三公里即时性配送难题(2016年4月,达达已经与京东到家合并)。 达达的业务组成简单直接——商家下单、配送员接单和配送,也正因为理解起来简单,使得达达的业务量在短时间能实现爆发式增长。而支撑业务快速增长的背后,正是达达技术团队持续不断的快速技术迭代的结果,本文正好借此机会,总结并分享了这一系列技术演进的第一手实践资料,希望能给同样奋斗在互联网创业一线的你带来启发。 (本文同步发布于:
http://www.52im.net/thread-2141-1-1.html)
《 新手入门:零基础理解大型分布式架构的演进历史、技术原理、最佳实践》 《 腾讯资深架构师干货总结:一文读懂大型分布式系统设计的方方面面》 《 快速理解高性能HTTP服务端的负载均衡技术原理》 《 知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路》 《 阿里技术分享:深度揭秘阿里数据库技术方案的10年变迁史》 《 阿里技术分享:阿里自研金融级数据库OceanBase的艰辛成长之路》
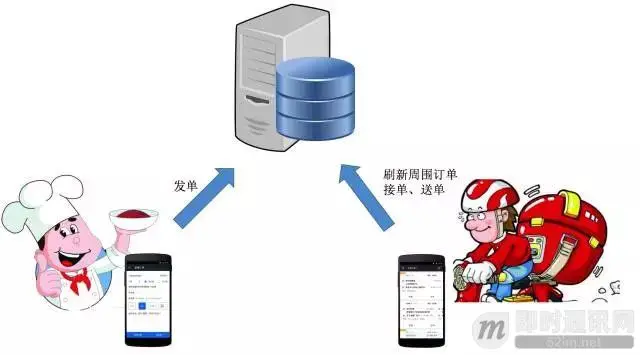 达达的业务规模增长极大,在1年左右的时间从零增长到每天近百万单,给后端带来极大的访问压力。压力主要分为两类:读压力、写压力。读压力来源于配送员在APP中抢单,高频刷新查询周围的订单,每天访问量几亿次,高峰期QPS高达数千次/秒。写压力来源于商家发单、达达接单、取货、完成等操作。达达业务读的压力远大于写压力,读请求量约是写请求量的30倍以上。
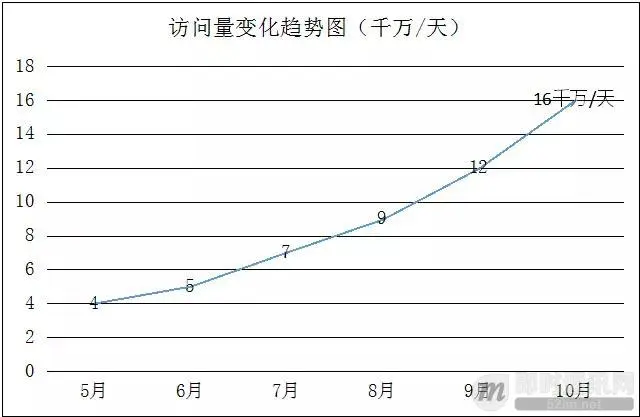
下图是达达在成长初期,每天的访问量变化趋图,可见增长极快:
达达的业务规模增长极大,在1年左右的时间从零增长到每天近百万单,给后端带来极大的访问压力。压力主要分为两类:读压力、写压力。读压力来源于配送员在APP中抢单,高频刷新查询周围的订单,每天访问量几亿次,高峰期QPS高达数千次/秒。写压力来源于商家发单、达达接单、取货、完成等操作。达达业务读的压力远大于写压力,读请求量约是写请求量的30倍以上。
下图是达达在成长初期,每天的访问量变化趋图,可见增长极快:
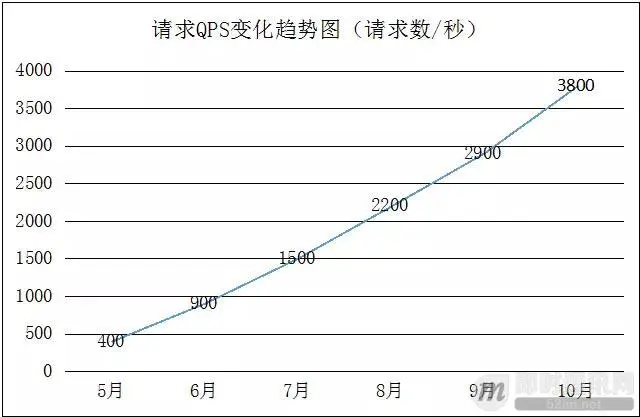
 下图是达达在成长初期,高峰期请求QPS的变化趋势图,可见增长极快:
下图是达达在成长初期,高峰期请求QPS的变化趋势图,可见增长极快:
 极速增长的业务,对技术的要求越来越高,我们必须在架构上做好充分的准备,才能迎接业务的挑战。接下来,我们一起看看达达的后台架构是如何演化的。
小知识:
什么是QPS、TPS?
极速增长的业务,对技术的要求越来越高,我们必须在架构上做好充分的准备,才能迎接业务的挑战。接下来,我们一起看看达达的后台架构是如何演化的。
小知识:
什么是QPS、TPS?
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。 TPS:是TransactionsPerSecond的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。

 实现读写分离后,数据库的压力减少了许多,CPU使用率和IO使用率都降到了5%内,Slow Query也趋近于0。
主从同步、读写分离给我们主要带来如下两个好处:
1)减轻了主库(写)压力:达达的业务主要来源于读操作,做读写分离后,读压力转移到了从库,主库的压力减小了数十倍;
2)从库(读)可水平扩展(加从库机器):因系统压力主要是读请求,而从库又可水平扩展,当从库压力太时,可直接添加从库机器,缓解读请求压力。
如下是优化后数据库QPS的变化图:
实现读写分离后,数据库的压力减少了许多,CPU使用率和IO使用率都降到了5%内,Slow Query也趋近于0。
主从同步、读写分离给我们主要带来如下两个好处:
1)减轻了主库(写)压力:达达的业务主要来源于读操作,做读写分离后,读压力转移到了从库,主库的压力减小了数十倍;
2)从库(读)可水平扩展(加从库机器):因系统压力主要是读请求,而从库又可水平扩展,当从库压力太时,可直接添加从库机器,缓解读请求压力。
如下是优化后数据库QPS的变化图:
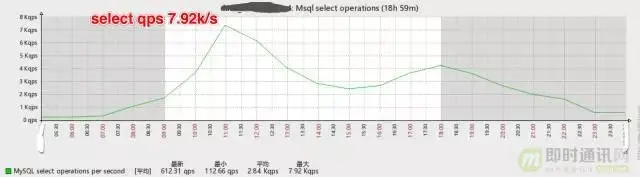 ▲ 读写分离前主库的select QPS
▲ 读写分离前主库的select QPS
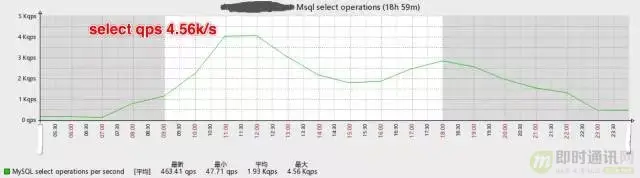 ▲ 读写分离后主库的select QPS
▲ 读写分离后主库的select QPS
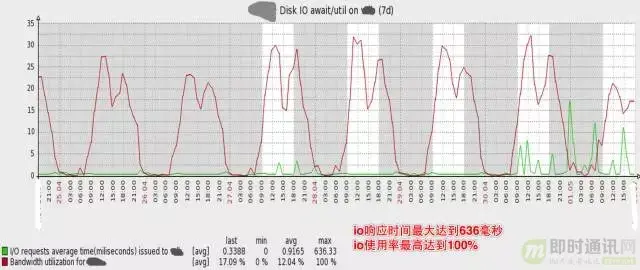 ▲ 可见磁盘IO使用率已经非常高,高峰期IO响应时间最大达到636毫秒,IO使用率最高达到100% 同时,业务越来越复杂,多个应用系统使用同一个数据库,其中一个很小的非核心功能出现Slow query,常常影响主库上的其它核心业务功能。 我们有一个应用系统在MySQL中记录日志,日志量非常大,近1亿行记录,而这张表的ID是UUID,某一天高峰期,整个系统突然变慢,进而引发了宕机。监控发现,这张表insert极慢,拖慢了整个MySQL Master,进而拖跨了整个系统。(当然在MySQL中记日志不是一种好的设计,因此我们开发了大数据日志系统。另一方面,UUID做主键是个糟糕的选择,在下文的水平分库中,针对ID的生成,有更深入的讲述)。
▲ 可见磁盘IO使用率已经非常高,高峰期IO响应时间最大达到636毫秒,IO使用率最高达到100% 同时,业务越来越复杂,多个应用系统使用同一个数据库,其中一个很小的非核心功能出现Slow query,常常影响主库上的其它核心业务功能。 我们有一个应用系统在MySQL中记录日志,日志量非常大,近1亿行记录,而这张表的ID是UUID,某一天高峰期,整个系统突然变慢,进而引发了宕机。监控发现,这张表insert极慢,拖慢了整个MySQL Master,进而拖跨了整个系统。(当然在MySQL中记日志不是一种好的设计,因此我们开发了大数据日志系统。另一方面,UUID做主键是个糟糕的选择,在下文的水平分库中,针对ID的生成,有更深入的讲述)。
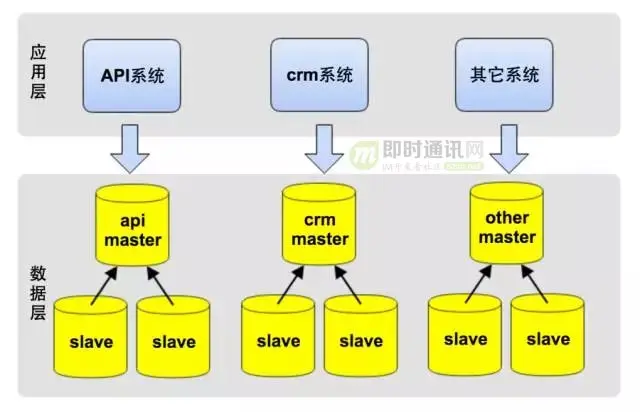 下图是垂直拆分后,数据库主库的压力,可见磁盘IO使用率已降低了许多,高峰期IO响应时间在2.33毫秒内,IO使用率最高只到22.8%:
下图是垂直拆分后,数据库主库的压力,可见磁盘IO使用率已降低了许多,高峰期IO响应时间在2.33毫秒内,IO使用率最高只到22.8%:
 未来是美好的,道路是曲折的。 垂直分库过程,也遇到不少挑战,
最大的挑战是:不能跨库join,同时需要对现有代码重构。单库时,可以简单的使用join关联表查询;拆库后,拆分后的数据库在不同的实例上,就不能跨库使用join了。 比如在CRM系统中,需要通过商家名查询某个商家的所有订单,在垂直分库前,可以join商家和订单表做查询,如下如示:
未来是美好的,道路是曲折的。 垂直分库过程,也遇到不少挑战,
最大的挑战是:不能跨库join,同时需要对现有代码重构。单库时,可以简单的使用join关联表查询;拆库后,拆分后的数据库在不同的实例上,就不能跨库使用join了。 比如在CRM系统中,需要通过商家名查询某个商家的所有订单,在垂直分库前,可以join商家和订单表做查询,如下如示:
 分库后,则要重构代码,先通过商家名查询商家id,再通过商家Id查询订单表,如下所示:
分库后,则要重构代码,先通过商家名查询商家id,再通过商家Id查询订单表,如下所示:
 垂直分库过程中的经验教训,使我们制定了SQL最佳实践,其中一条便是程序中禁用或少用join,而应该在程序中组装数据,让SQL更简单。一方面为以后进一步垂直拆分业务做准备,另一方面也避免了MySQL中join的性能较低的问题。 经过一个星期紧锣密鼓的底层架构调整,以及业务代码重构,终于完成了数据库的垂直拆分。拆分之后,每个应用程序只访问对应的数据库,一方面将单点数据库拆分成了多个,分摊了主库写压力;另一方面,拆分后的数据库各自独立,实现了业务隔离,不再互相影响。
垂直分库过程中的经验教训,使我们制定了SQL最佳实践,其中一条便是程序中禁用或少用join,而应该在程序中组装数据,让SQL更简单。一方面为以后进一步垂直拆分业务做准备,另一方面也避免了MySQL中join的性能较低的问题。 经过一个星期紧锣密鼓的底层架构调整,以及业务代码重构,终于完成了数据库的垂直拆分。拆分之后,每个应用程序只访问对应的数据库,一方面将单点数据库拆分成了多个,分摊了主库写压力;另一方面,拆分后的数据库各自独立,实现了业务隔离,不再互相影响。
 水平分库面临的第一个问题是,按什么逻辑进行拆分: 1)一种方案是按城市拆分,一个城市的所有数据在一个数据库中; 2)另一种方案是按订单ID平均拆分数据。 按城市拆分的优点是数据聚合度比较高,做聚合查询比较简单,实现也相对简单,缺点是数据分布不均匀,某些城市的数据量极大,产生热点,而这些热点以后可能还要被迫再次拆分。 按订单ID拆分则正相反,优点是数据分布均匀,不会出现一个数据库数据极大或极小的情况,缺点是数据太分散,不利于做聚合查询。比如,按订单ID拆分后,一个商家的订单可能分布在不同的数据库中,查询一个商家的所有订单,可能需要查询多个数据库。针对这种情况,一种解决方案是将需要聚合查询的数据做冗余表,冗余的表不做拆分,同时在业务开发过程中,减少聚合查询。 反复权衡利弊,并参考了Uber等公司的分库方案后,我们最后决定按订单ID做水平分库。
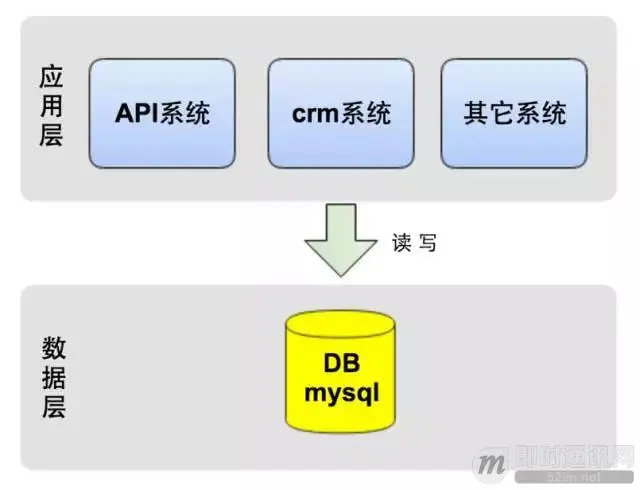
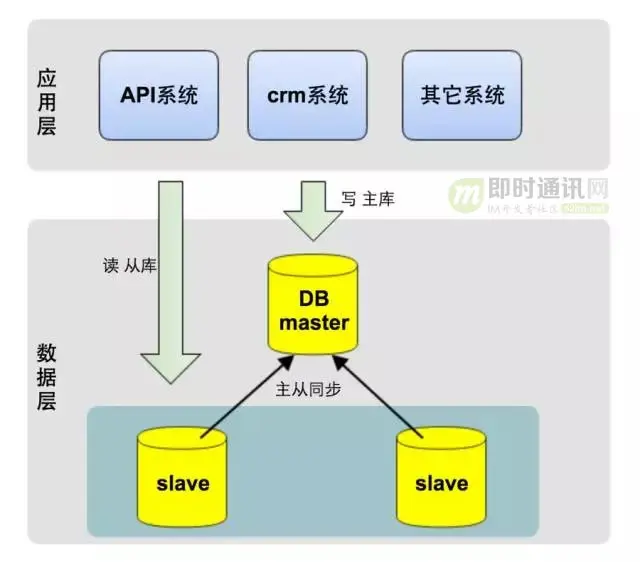
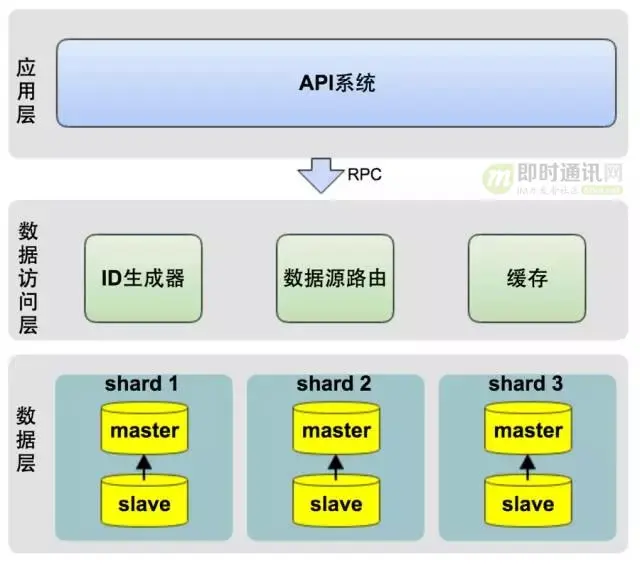
从架构上,我们将系统分为三层: 1)应用层:即各类业务应用系统; 2)数据访问层:统一的数据访问接口,对上层应用层屏蔽读写分库、分库、缓存等技术细节; 3)数据层:对DB数据进行分片,并可动态的添加shard分片。 水平分库的技术关键点在于数据访问层的设计。
数据访问层主要包含三部分: 1)ID生成器:生成每张表的主键; 2)数据源路由:将每次DB操作路由到不同的shard数据源上; 3)缓存: 采用Redis实现数据的缓存,提升性能。
ID生成器是整个水平分库的核心,它决定了如何拆分数据,以及查询存储-检索数据: 1)ID需要跨库全局唯一,否则会引发业务层的冲突; 2)此外,ID必须是数字且升序,这主要是考虑到升序的ID能保证MySQL的性能; 3)同时,ID生成器必须非常稳定,因为任何故障都会影响所有的数据库操作。 我们的ID的生成策略借鉴了Instagram的ID生成算法。
我们具体的ID生成算法方案如下:
水平分库面临的第一个问题是,按什么逻辑进行拆分: 1)一种方案是按城市拆分,一个城市的所有数据在一个数据库中; 2)另一种方案是按订单ID平均拆分数据。 按城市拆分的优点是数据聚合度比较高,做聚合查询比较简单,实现也相对简单,缺点是数据分布不均匀,某些城市的数据量极大,产生热点,而这些热点以后可能还要被迫再次拆分。 按订单ID拆分则正相反,优点是数据分布均匀,不会出现一个数据库数据极大或极小的情况,缺点是数据太分散,不利于做聚合查询。比如,按订单ID拆分后,一个商家的订单可能分布在不同的数据库中,查询一个商家的所有订单,可能需要查询多个数据库。针对这种情况,一种解决方案是将需要聚合查询的数据做冗余表,冗余的表不做拆分,同时在业务开发过程中,减少聚合查询。 反复权衡利弊,并参考了Uber等公司的分库方案后,我们最后决定按订单ID做水平分库。
从架构上,我们将系统分为三层: 1)应用层:即各类业务应用系统; 2)数据访问层:统一的数据访问接口,对上层应用层屏蔽读写分库、分库、缓存等技术细节; 3)数据层:对DB数据进行分片,并可动态的添加shard分片。 水平分库的技术关键点在于数据访问层的设计。
数据访问层主要包含三部分: 1)ID生成器:生成每张表的主键; 2)数据源路由:将每次DB操作路由到不同的shard数据源上; 3)缓存: 采用Redis实现数据的缓存,提升性能。
ID生成器是整个水平分库的核心,它决定了如何拆分数据,以及查询存储-检索数据: 1)ID需要跨库全局唯一,否则会引发业务层的冲突; 2)此外,ID必须是数字且升序,这主要是考虑到升序的ID能保证MySQL的性能; 3)同时,ID生成器必须非常稳定,因为任何故障都会影响所有的数据库操作。 我们的ID的生成策略借鉴了Instagram的ID生成算法。
我们具体的ID生成算法方案如下:
 如上图所示,方案说明如下: 1)整个ID的二进制长度为64位; 2)前36位使用时间戳,以保证ID是升序增加; 3)中间13位是分库标识,用来标识当前这个ID对应的记录在哪个数据库中; 4)后15位为MySQL自增序列,以保证在同一秒内并发时,ID不会重复。每个shard库都有一个自增序列表,生成自增序列时,从自增序列表中获取当前自增序列值,并加1,做为当前ID的后15位。
如上图所示,方案说明如下: 1)整个ID的二进制长度为64位; 2)前36位使用时间戳,以保证ID是升序增加; 3)中间13位是分库标识,用来标识当前这个ID对应的记录在哪个数据库中; 4)后15位为MySQL自增序列,以保证在同一秒内并发时,ID不会重复。每个shard库都有一个自增序列表,生成自增序列时,从自增序列表中获取当前自增序列值,并加1,做为当前ID的后15位。
[1] 有关IM架构设计的文章: 《 浅谈IM系统的架构设计》 《 简述移动端IM开发的那些坑:架构设计、通信协议和客户端》 《 一套海量在线用户的移动端IM架构设计实践分享(含详细图文)》 《 一套原创分布式即时通讯(IM)系统理论架构方案》 《 从零到卓越:京东客服即时通讯系统的技术架构演进历程》 《 蘑菇街即时通讯/IM服务器开发之架构选择》 《 腾讯QQ1.4亿在线用户的技术挑战和架构演进之路PPT》 《 微信后台基于时间序的海量数据冷热分级架构设计实践》 《 微信技术总监谈架构:微信之道——大道至简(演讲全文)》 《 如何解读《微信技术总监谈架构:微信之道——大道至简》》 《 快速裂变:见证微信强大后台架构从0到1的演进历程(一)》 《 17年的实践:腾讯海量产品的技术方法论》 《 移动端IM中大规模群消息的推送如何保证效率、实时性?》 《 现代IM系统中聊天消息的同步和存储方案探讨》 《 IM开发基础知识补课(二):如何设计大量图片文件的服务端存储架构?》 《 IM开发基础知识补课(三):快速理解服务端数据库读写分离原理及实践建议》 《 IM开发基础知识补课(四):正确理解HTTP短连接中的Cookie、Session和Token》 《 WhatsApp技术实践分享:32人工程团队创造的技术神话》 《 微信朋友圈千亿访问量背后的技术挑战和实践总结》 《 王者荣耀2亿用户量的背后:产品定位、技术架构、网络方案等》 《 IM系统的MQ消息中间件选型:Kafka还是RabbitMQ?》 《 腾讯资深架构师干货总结:一文读懂大型分布式系统设计的方方面面》 《 以微博类应用场景为例,总结海量社交系统的架构设计步骤》 《 快速理解高性能HTTP服务端的负载均衡技术原理》 《 子弹短信光鲜的背后:网易云信首席架构师分享亿级IM平台的技术实践》 《 知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路》 《 IM开发基础知识补课(五):通俗易懂,正确理解并用好MQ消息队列》 《 微信技术分享:微信的海量IM聊天消息序列号生成实践(算法原理篇)》 《 微信技术分享:微信的海量IM聊天消息序列号生成实践(容灾方案篇)》 《 新手入门:零基础理解大型分布式架构的演进历史、技术原理、最佳实践》 《 一套高可用、易伸缩、高并发的IM群聊架构方案设计实践》 《 阿里技术分享:深度揭秘阿里数据库技术方案的10年变迁史》 《 阿里技术分享:阿里自研金融级数据库OceanBase的艰辛成长之路》 >> 更多同类文章 …… [2] 更多其它架构设计相关文章: 《 腾讯资深架构师干货总结:一文读懂大型分布式系统设计的方方面面》 《 快速理解高性能HTTP服务端的负载均衡技术原理》 《 子弹短信光鲜的背后:网易云信首席架构师分享亿级IM平台的技术实践》 《 知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路》 《 新手入门:零基础理解大型分布式架构的演进历史、技术原理、最佳实践》 《 阿里技术分享:深度揭秘阿里数据库技术方案的10年变迁史》 《 阿里技术分享:阿里自研金融级数据库OceanBase的艰辛成长之路》 《 达达O2O后台架构演进实践:从0到4000高并发请求背后的努力》 >> 更多同类文章 ……(本文同步发布于: http://www.52im.net/thread-2141-1-1.html)
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
写的不错######问个问题,”动态的添加shard分片“ 这个你们是怎么做的,需要移动数据吗?不移动的话,根据新的hash,可能原来在a库的数据会hash到b库去

