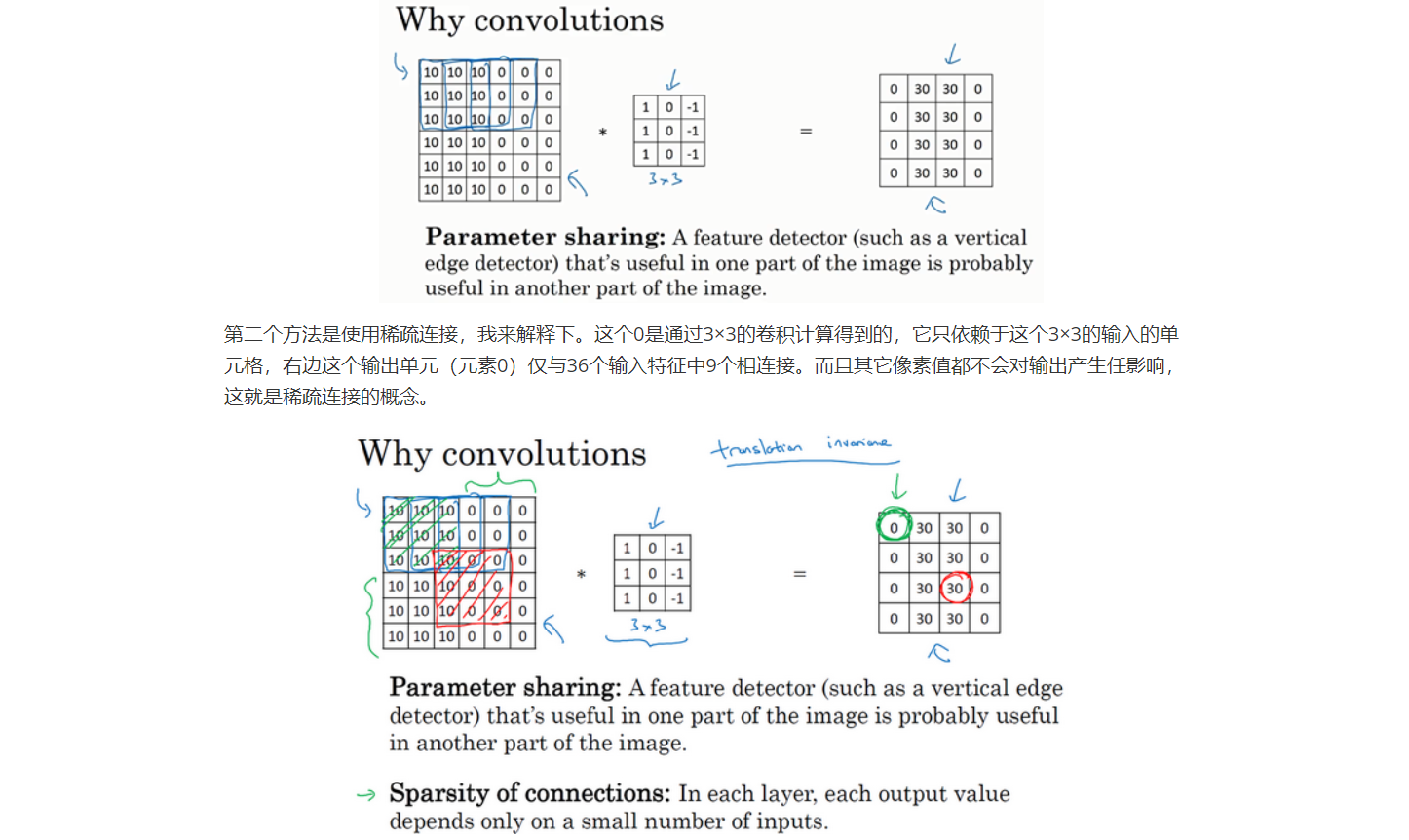
为什么使用卷积?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
假设有一张32×32×3维度的图片,这是上节课的示例,假设用了6个大小为5×5的过滤器,输出维度为28×28×6。32×32×3=3072,28×28×6=4704。我们构建一个神经网络,其中一层含有3072个单元,下一层含有4074个单元,两层中的每个神经元彼此相连,然后计算权重矩阵,它等于4074×3072≈1400万,所以要训练的参数很多。虽然以现在的技术,我们可以用1400多万个参数来训练网络,因为这张32×32×3的图片非常小,训练这么多参数没有问题。如果这是一张1000×1000的图片,权重矩阵会变得非常大。我们看看这个卷积层的参数数量,每个过滤器都是5×5,一个过滤器有25个参数,再加上偏差参数,那么每个过滤器就有26个参数,一共有6个过滤器,所以参数共计156个,参数数量还是很少。
卷积网络映射这么少参数有两个原因:
一是参数共享。观察发现,特征检测如垂直边缘检测如果适用于图片的某个区域,那么它也可能适用于图片的其他区域。也就是说,如果你用一个3×3的过滤器检测垂直边缘,那么图片的左上角区域,以及旁边的各个区域(左边矩阵中蓝色方框标记的部分)都可以使用这个3×3的过滤器。每个特征检测器以及输出都可以在输入图片的不同区域中使用同样的参数,以便提取垂直边缘或其它特征。它不仅适用于边缘特征这样的低阶特征,同样适用于高阶特征,例如提取脸上的眼睛,猫或者其他特征对象。即使减少参数个数,这9个参数同样能计算出16个输出。直观感觉是,一个特征检测器,如垂直边缘检测器用于检测图片左上角区域的特征,这个特征很可能也适用于图片的右下角区域。因此在计算图片左上角和右下角区域时,你不需要添加其它特征检测器。假如有一个这样的数据集,其左上角和右下角可能有不同分布,也有可能稍有不同,但很相似,整张图片共享特征检测器,提取效果也很好。