数据分布不匹配时,偏差与方差的分析
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
我们继续用猫分类器为例,我们说人类在这个任务上能做到几乎完美,所以贝叶斯错误率或者说贝叶斯最优错误率,我们知道这个问题里几乎是0%。所以要进行错误率分析,你通常需要看训练误差,也要看看开发集的误差。比如说,在这个样本中,你的训练集误差是1%,你的开发集误差是10%,如果你的开发集来自和训练集一样的分布,你可能会说,这里存在很大的方差问题,你的算法不能很好的从训练集出发泛化,它处理训练集很好,但处理开发集就突然间效果很差了。
但如果你的训练数据和开发数据来自不同的分布,你就不能再放心下这个结论了。特别是,也许算法在开发集上做得不错,可能因为训练集很容易识别,因为训练集都是高分辨率图片,很清晰的图像,但开发集要难以识别得多。所以也许软件没有方差问题,这只不过反映了开发集包含更难准确分类的图片。所以这个分析的问题在于,当你看训练误差,再看开发误差,有两件事变了。首先算法只见过训练集数据,没见过开发集数据。第二,开发集数据来自不同的分布。而且因为你同时改变了两件事情,很难确认这增加的9%误差率有多少是因为算法没看到开发集中的数据导致的,这是问题方差的部分,有多少是因为开发集数据就是不一样。
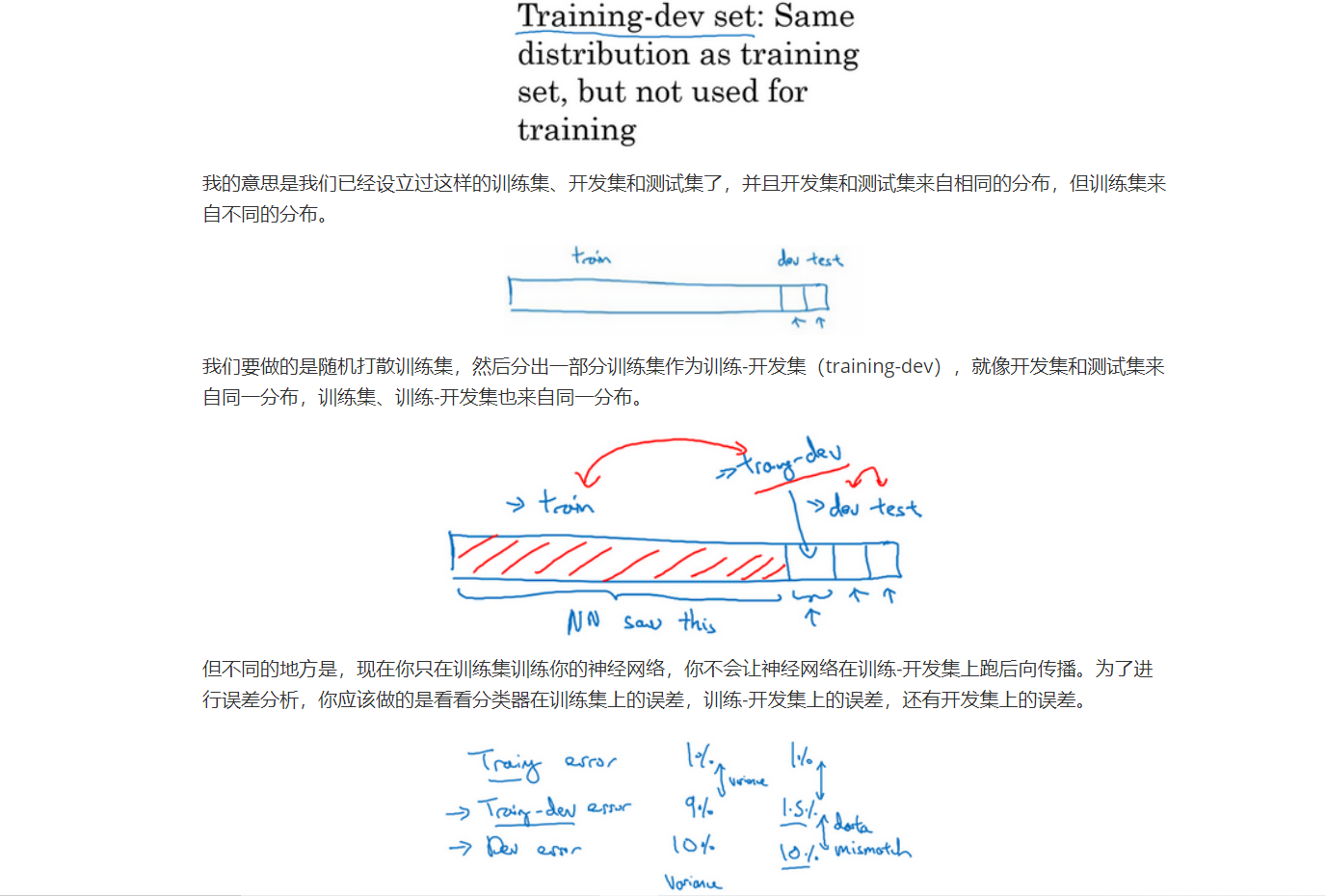
为了弄清楚哪个因素影响更大,如果你完全不懂这两种影响到底是什么,别担心我们马上会再讲一遍。但为了分辨清楚两个因素的影响,定义一组新的数据是有意义的,我们称之为训练-开发集,所以这是一个新的数据子集。我们应该从训练集的分布里挖出来,但你不会用来训练你的网络。