
BlueFS 和 RocksDB是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
BlueStore 通过将元数据保存到 RocksDB 来实现快速的元数据操作;通过下面两点来避免一致性开销:
直接写数据到裸盘,从而只有一次 cache flush;
修改 RocksDB 将 WAL 作为 circular buffer 使用,从而达到元数据写入只有一次 cache flush——这个 feature 已经 upstream 到上游。
BlueFS 实现了像 open、 mkdir、 pwrite这些 RocksDB 所需的基本系统调用。BlueFS 的磁盘布局如下图。 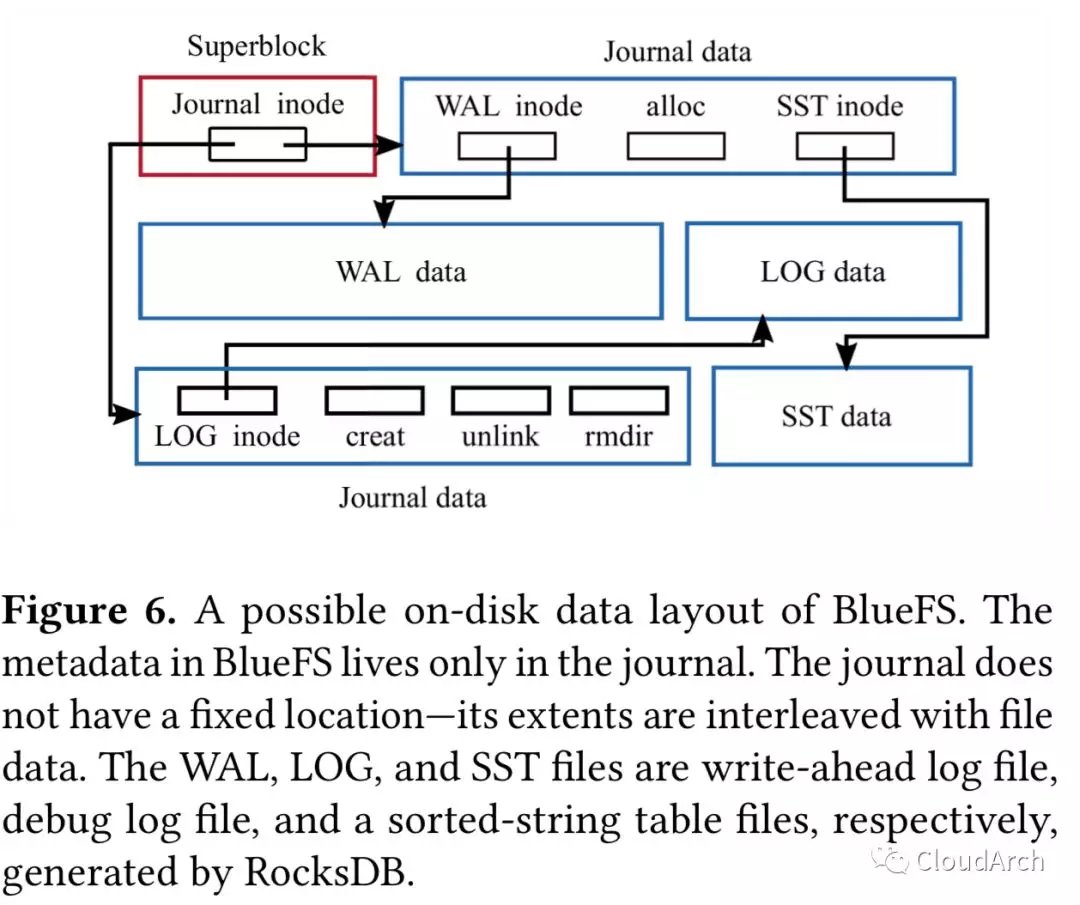
BlueFS 为每一个文件维护一个 inode,其中包含为这个文件分配的 extent 信息。superblock 保存在固定位置,包含 journal 的 inode。journal 有文件系统元数据的唯一副本,mount 时加载到内存。每当有元数据操作例如创建目录、文件和分配 extent 时,journal 和内存里的元数据会被更新。journal 不保存在固定位置,它的 extent 会与文件的 extent 有交错。每当达到一个阈值时,journal 会被压缩并写到新的位置,这个新的位置被记录到 superblock 里。这样设计之所以可行是因为得益于大文件和周期压缩会限制任一时刻 volume 元数据的数量。
关于元数据组织,BlueStore 在 RocksDB 中使用了多个命名空间,每个命名空间用来保存不同类型的元数据。举例来说对象信息都保存在命名空间 O 中(也就是说 RocksDB 中 O 开头的 key 都表示对象的元数据),块分配元数据保存在命名空间 B,集合元数据(collection metadata)保存在命名空间 C。每个集合(collection)映射到一个 PG,并代表 pool namespace 的一个 shard。collection 的名字包含 pool 的标识和collection 里对象名字的统一 prefix。
举个例子,一个 kv:C12.e4-6标识 pool 12 的一个集合,这个集合里的对象的哈希以 e4 的 6 个最高有效位开头(hash values starting with the 6 significant bits of e4)。例如对象 012.e532 就是这个集合的成员(前六位是 111001),而 012.e832 就不是(前六位是 111010)。这种元数据组织方式允许通过只修改有效位数的数量(the number of significant bits)把数百万的对象分割成多个集合。这样比如有加入的 OSD 增加了总容量或者现有 OSD 因为失效从集群移除时,FileStore 在拆分 collection 时就需要昂贵的目录拆分,而 BlueStore 就简单很多。

