
各位大佬,flink任务的并发数调大到160+以后,每隔几十分钟就会出现一次TM节点连接丢失的异常,
各位大佬,flink任务的并发数调大到160+以后,每隔几十分钟就会出现一次TM节点连接丢失的异常,导致任务重启。并发在100时运行比较稳定,哪位大佬可以提供下排查的思路? 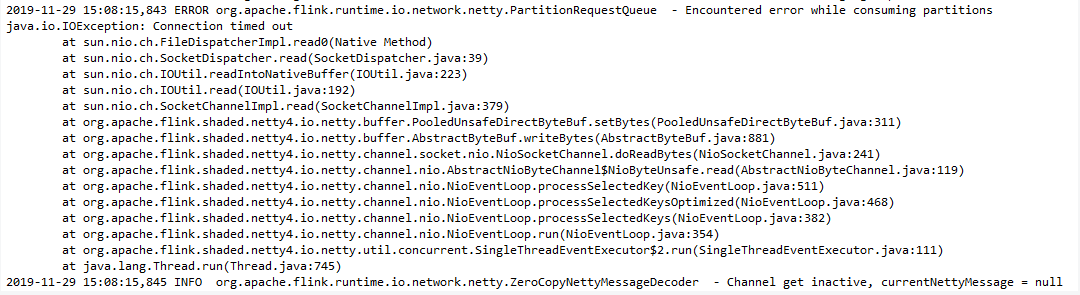 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 点击这里欢迎加入感兴趣的技术领域群。
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 点击这里欢迎加入感兴趣的技术领域群。
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
2
条回答
写回答
-
原因不确定,可能有的原因有:(1)内存用超了OOM挂掉了;(2)内存用多了被yarn的nodemanager给killed了,可以看看nodemanger的日志;(3)内存不太够,在做GC耗时较长卡住了,可以看看TM的gc日志;(4)网络抖动,可以尝试把timeout时间调长,taskmanager.network.netty.client.connectTimeoutSec=1800;(5)其他原因。
2020-03-06 21:06:00赞同 展开评论 -
问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
实时计算 Flink
>
问答
相关问答

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
收录在圈子:

+ 订阅
实时计算 Flink 版(Alibaba Cloud Realtime Compute for Apache Flink,Powered by Ververica)是阿里云基于 Apache Flink 构建的企业级、高性能实时大数据处理系统,由 Apache Flink 创始团队官方出品,拥有全球统一商业化品牌,完全兼容开源 Flink API,提供丰富的企业级增值功能。
相关文章
热门讨论
热门文章
展开全部
还有其他疑问?
咨询AI助理