
上次一天抓10万多次,逼得我把 url 改成js跳转.
这次抓取的更凶狠,
超过50多万次!!!
一秒钟抓取好几次,
我在 robots.txt 里面设置了
Crawl-delay: 5
设置禁止抓取动态页
都不管用.
ip 系列 203.208.60.*
查询是:
•本站主数据:北京市海淀区 北京谷翔信息技术有限公司 电信
•参考数据二:北京市 飞翔人信息技术有限公司
google 美国的ip抓取很少.
有没有遇到和我一样?
这是我原来的robots.txt设置,帮我看看是不是禁止抓取动态页?
User-agent: Baiduspider
Disallow:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
Crawl-delay: 5
Disallow: /*?*
上一个日志统计图:


版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-------------------------

你看看google蜘蛛的频率,差不多30秒到1分钟一次,没你那么夸张
google不可能一秒钟很多次去爬站的
这点google还是懂的

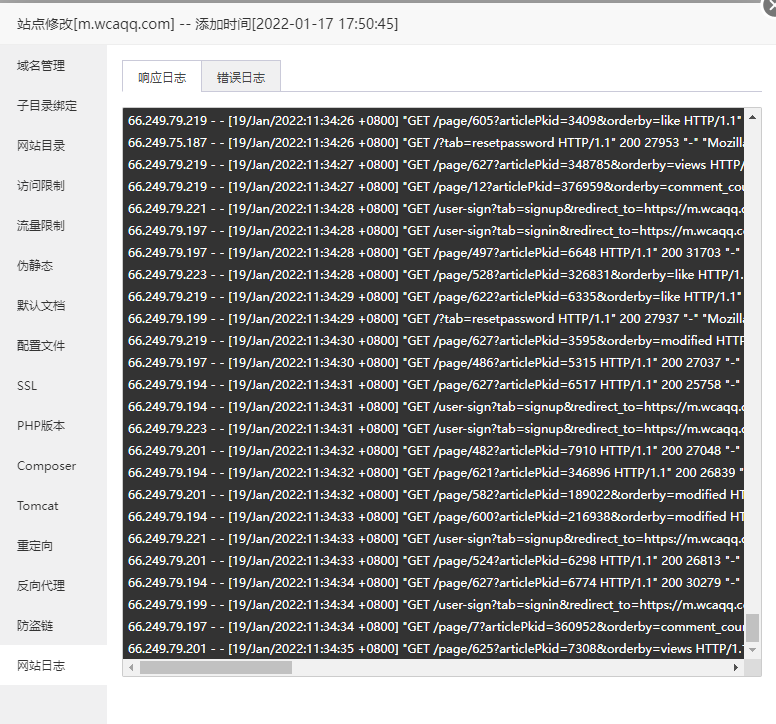 我的也是 ,怎么解决,不听的抓取,网站流量蹭蹭的涨 网址:
我的也是 ,怎么解决,不听的抓取,网站流量蹭蹭的涨 网址: