分析型数据库支持多种接入数据的方式,您可以直接将数据通过insert/delete SQL写入实时表(详见使用手册第四章),或通过Kettle等ETL工具将本地文件写入分析型数据库,或是通过阿里云数据传输从阿里云RDS中实时同步数据变更(见使用手册8.5节),或者建立批量导入表从阿里云MaxCompute(原名ODPS)大批量的导入数据。
如果在建立表时选择数据来源是批量导入,则分析型数据库提供多种数据导入的方式,如通过data pipeline系列命令(详见5.1),等方式。在这里,作为测试使用,我们通过控制台界面进行数据导入。
在操作导入数据之前,我们需要对数据的来源表进行授权,例如数据的来源表在odps上,在公有云上则需要在ODPS上对
garuda_build@aliyun.com 与
garuda_data@aliyun.com 授予describe和select权限(各个专有云授权的账号名参照专有云的相关配置文档,不一定是这个账号)。另外要注意,分析型数据库目前仅允许操作者导入自身为Project Owner的ODPS Project中,或者操作者是ODPS表的Table Creator的数据。
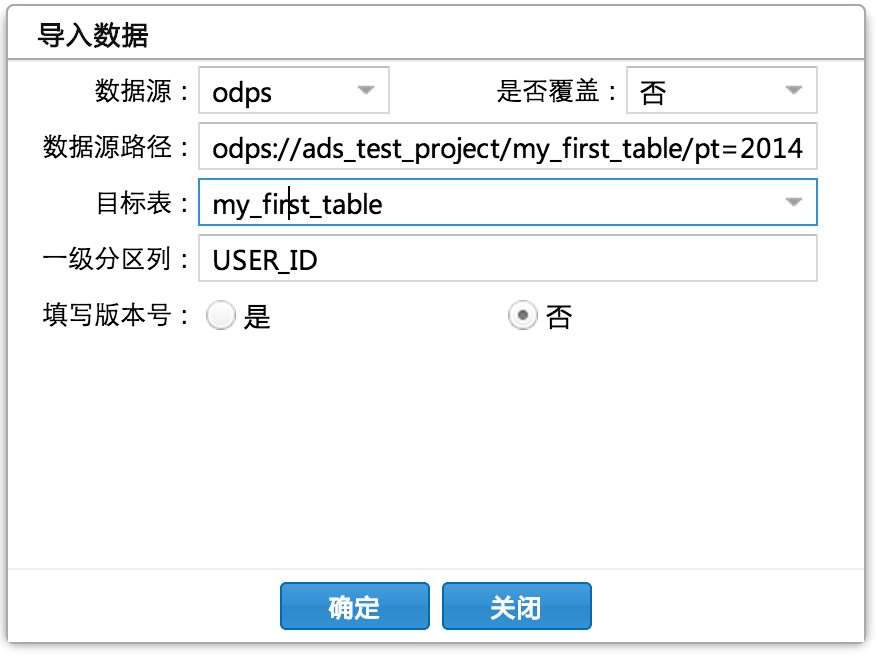
进入DMS页面,选择菜单栏上的导入按钮,弹出导入对话框。这里我们的数据源表在阿里云ODPS上。因此数据导入路径按照 “odps://project_name/table_name/partition_spec” 的格式来填写。关于导入数据的分区信息,在仅有Hash分区的情况下iDB Cloud会帮我们自动识别并填写。填写完毕后,如下图所示,点击“确定”按钮。
之后页面会展示导入状态一览,分析型数据库会对导入任务进行调度,根据当前系统繁忙情况和待导入数据的大小和结构不同,二十分钟至数个小时内数据导入会结束。
如果建表时数据来源选择的是实时写入,那么则可以在建表后直接在SQL窗口中编写SQL:<PRE prettyprinted? linenums>
- insert into my_first_table (user_id,amt,num,cat_id,thedate) values (12345, 80, 900, 1555, 20140101);
实时写入的表刚刚建立后,会有一分钟左右(公共云当前版本:0.9.*版本数据,若使用0.8版本的ADS一般为十五分钟左右)的准备时间,这时候写入的数据需要在准备完成后才能查询,否则查询会报错。在准备完成后,实时进行insert/delete的数据变更一般延迟一分钟内可查。
需要注意的是,分析型数据库进行实时插入和删除时,不支持事务,并且仅遵循最终一致性的设计,所以分析型数据库并不能作为OLTP系统使用。
若表的数据是离线批量导入,但是数据源是RDS等其它的云上系统,那么我们可以通过阿里云的CDP产品进行数据同步,在
http://www.aliyun.com/product/cdp/ 上开通CDP(可能需要申请公测)后,按照如下示例配置同步Job:<PRE prettyprinted? linenums>
- {
- "type": "job",
- "traceId": "rds to ads job test",
- "version": "1.0",
- "configuration": {
- "setting": {
- },
- "reader": {
- "plugin": "mysql",
- "parameter": {
- "instanceName": "你的RDS的实例名",
- "database": "RDS数据库名",
- "table": "RDS表名",
- "splitPk": "任意一个列的名字",
- "username": "RDS用户名",
- "password": "RDS密码",
- "column": ["*"],
- }
- },
- "writer": {
- "plugin": "ads",
- "parameter": {
- "url": "在分析型数据库的控制台中选择数据库时提供的连接信息",
- "schema": "分析型数据库数据库名",
- "table": "分析型数据库表名",
- "username": "你的access key id",
- "password": "你的access key secret",
- "partition": "",
- "lifeCycle": 2,
- "overWrite": true
- }
- }
- }
- }
需要注意的是,在运行这个任务之前,需要在分析型数据库中对
cloud-data-pipeline@aliyun-inner.com 至少授予表的Load Data权限。
若表是实时写入的,但是仍需要通过数据集成CDP从其他数据源导入到分析型数据库中,则>上述reader配置不变,但是writer配置需要变为(以原表列和目标表列相同为例,若不同需要在column选项中配置Mapping):<PRE prettyprinted? linenums>
- "writer": {
- "name": "adswriter",
- "parameter": {
- "writeMode": "insert",
- "url": "在分析型数据库的控制台中选择数据库时提供的连接信息",
- "schema": "分析型数据库数据库名",
- "table": "分析型数据库表名",
- "column": ["*"],
- "username": "你的access key id",
- "password": "你的access key secret",
- "partition": "id,ds=2015"
- }

