
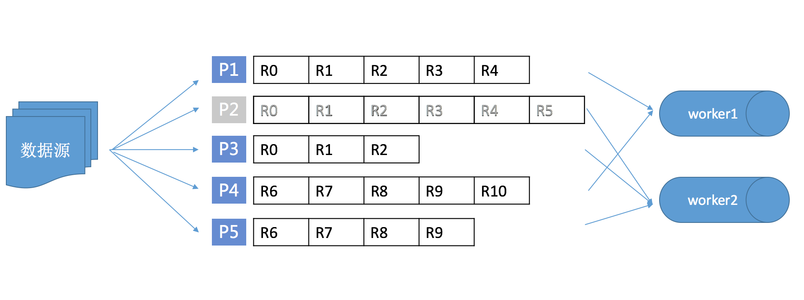
基于 Table Store Stream API 以及 Table Store SDK,您可以使用 API 或者 SDK 读取 Stream 的记录。在实时获取增量数据的时候,需要注意分区的信息不是静态的。分区可能会分裂、合并。当分区发生变化后,需要处理分区之间的依赖关系以确保单主键上数据顺序读取。同时,如果您的数据是由多客户端并发生成,为了提高导出增量数据的效率,也需要有多消费端并行读取各个分区的增量记录。
Stream Client 可以解决 Stream 数据处理时的常见问题,例如,如何做负载均衡,故障恢复,Checkpoint,分区信息同步确保分区信息消费顺序等。使用 Stream Client 后,您只需要关心每条记录的处理逻辑即可。
下面内容将介绍 Stream Client 的原理,以及如何使用 Stream Client 高效打造适合自身业务的数据通道。
Stream Client 原理
本节介绍 Stream Client 的内部逻辑。
为了方便做任务调度,以及记录当前每个分区的读取进度,Stream Client 使用了 Table Store 的一张表来记录这些信息,您可以自行选定表名,但是要确保该表名没有其他业务在使用。
Stream Client 中为每个分区定义了一个租约(lease),每个租约的拥有者叫做 worker。租约用来记录一个分区的增量数据消费者(即 worker)和读取进度信息。当一个新的消费端启动后,worker 会初始化,检查分区和租约信息,为没有相应租约的分区创建租约。当因为分裂或合并产生新的分区时,Stream Client 会在表中插入一条租约记录。新的记录会被某一个 Stream Client 的 worker 抢到并不断处理,如果有新的 worker 加入则可能会做负载均衡,调度至新 worker 处理。
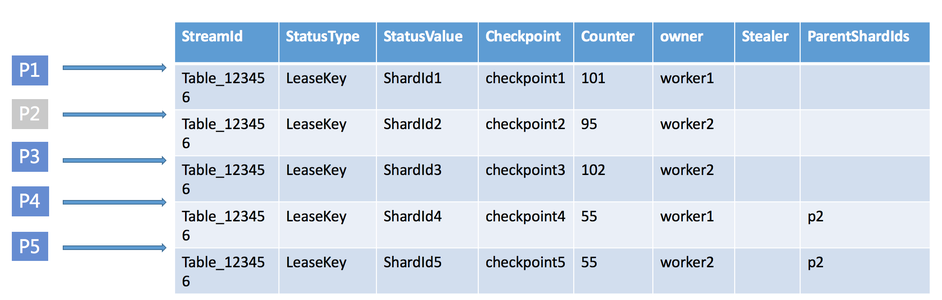
租约记录的 schema 如下所示:
| 参数 | 说明 |
| 主键 StreamId | 当前处理 Stream 的 Id。 |
| 主键 StatusType | 当前 lease 的 Key。 |
| 主键 StatusValue | 当前 lease 对应的分区的 Id。 |
| 属性 Checkpoint | 记录当前分区 Stream 数据消费的位置(用户故障恢复) |
| 属性 LeaseCounter | 表示乐观锁。每个 lease 的 owner 会持续更新这个 counter 值,用来续租表示继续占有当前的 lease。 |
| 属性 LeaseOwner | 拥有当前租约的 worker 名。 |
| 属性 LeaseStealer | 在负载均衡的时候,表示准备挪至哪个 worker。 |
| 属性 ParentShardIds | 当前 shard 的父分区信息。在 worker 消费当前 shard 时,保证父分区的 stream 数据已经被消费。 |
<dependency> <groupId>com.aliyun.openservices</groupId> <artifactId>tablestore-streamclient</artifactId> <version>1.0.0</version></dependency>
[backcolor=transparent]说明:Stream Client 的代码是开源的,您可以 下载源码了解原理,也欢迎您将基于 Stream 的优秀 Sample 代码分享给我们。
public interface IRecordProcessor {
void initialize(InitializationInput initializationInput);
void processRecords(ProcessRecordsInput processRecordsInput);
void shutdown(ShutdownInput shutdownInput);
}
| 参数 | 说明 |
| void initialize(InitializationInput initializationInput); | 用于初始化一个读取任务,表示 stream client 准备开始读取某个 shard 的数据。 |
| void processRecords(ProcessRecordsInput processRecordsInput); | 表示具体读取到数据后用户希望如何处理这批记录。在 ProcessRecordsInput 中有一个 getCheckpointer 函数可以得到一个 IRecordProcessorCheckpointer。这个接口是框架提供给用户用来做 checkpoint 的接口,用户可以自行决定多久做一次 checkpoint。 |
| void shutdown(ShutdownInput shutdownInput); | 表示结束某个 shard 的读区任务。 |
public class StreamSample {
class RecordProcessor implements IRecordProcessor {
private long creationTime = System.currentTimeMillis();
private String workerIdentifier;
public RecordProcessor(String workerIdentifier) {
this.workerIdentifier = workerIdentifier;
}
public void initialize(InitializationInput initializationInput) {
// Trace some info before start the query like stream info etc.
}
public void processRecords(ProcessRecordsInput processRecordsInput) {
List<StreamRecord> records = processRecordsInput.getRecords();
if(records.size() == 0) {
// No more records we can wait for the next query
System.out.println("no more records");
}
for (int i = 0; i < records.size(); i++) {
System.out.println("records:" + records.get(i));
}
// Since we don't persist the stream record we can skip blow step
System.out.println(processRecordsInput.getCheckpointer().getLargestPermittedCheckpointValue());
try {
processRecordsInput.getCheckpointer().checkpoint();
} catch (ShutdownException e) {
e.printStackTrace();
} catch (StreamClientException e) {
e.printStackTrace();
} catch (DependencyException e) {
e.printStackTrace();
}
}
public void shutdown(ShutdownInput shutdownInput) {
// finish the query task and trace the shutdown reason
System.out.println(shutdownInput.getShutdownReason());
}
}
class RecordProcessorFactory implements IRecordProcessorFactory {
private final String workerIdentifier;
public RecordProcessorFactory(String workerIdentifier) {
this.workerIdentifier = workerIdentifier;
}
public IRecordProcessor createProcessor() {
return new StreamSample.RecordProcessor(workerIdentifier);
}
}
public Worker getNewWorker(String workerIdentifier) {
// Please replace with your table info
final String endPoint = "";
final String accessId = "";
final String accessKey = "";
final String instanceName = "";
StreamConfig streamConfig = new StreamConfig();
streamConfig.setOTSClient(new SyncClient(endPoint, accessId, accessKey,
instanceName));
streamConfig.setDataTableName("teststream");
streamConfig.setStatusTableName("statusTable");
Worker worker = new Worker(workerIdentifier, new ClientConfig(), streamConfig,
new StreamSample.RecordProcessorFactory(workerIdentifier), Executors.newCachedThreadPool(), null);
return worker;
}
public static void main(String[] args) throws InterruptedException {
StreamSample test = new StreamSample();
Worker worker1 = test.getNewWorker("worker1");
Thread thread1 = new Thread(worker1);
thread1.start();
}
}
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
