
(本文数据为虚构,仅供实验)
一、背景
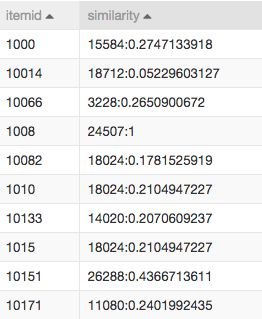
数据挖掘的一个经典案例就是尿布与啤酒的例子。尿布与啤酒看似毫不相关的两种产品,但是当超市将两种产品放到相邻货架销售的时候,会大大提高两者销量。很多时候看似不相关的两种产品,却会存在这某种神秘的隐含关系,获取这种关系将会对提高销售额起到推动作用,然而有时这种关联是很难通过理性的分析得到的。这时候我们需要借助数据挖掘中的常见算法-协同过滤来实现。这种算法可以帮助我们挖掘人与人以及商品与商品的关联关系。
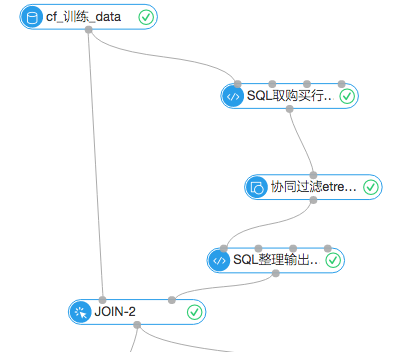
协同过滤算法是一种基于关联规则的算法,以购物行为为例。假设有甲和乙两名用户,有a、b、c三款产品。如果甲和乙都购买了a和b这两种产品,我们可以假定甲和乙有近似的购物品味。当甲购买了产品c而乙还没有购买c的时候,我们就可以把c也推荐给乙。这是一种典型的user-based情况,就是以user的特性做为一种关联。
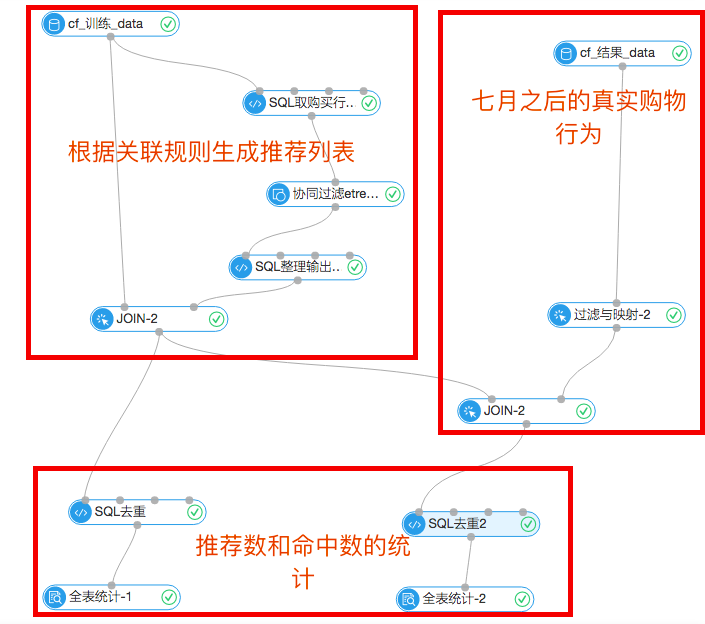
本文的业务场景如下:通过一份7月份前的用户购物行为数据,获取商品的关联关系,对用户7月份之后的购买形成推荐,并评估结果。比如用户甲某在7月份之前买了商品A,商品A与B强相关,我们就在7月份之后推荐了商品B,并探查这次推荐是否命中。
二、数据集介绍
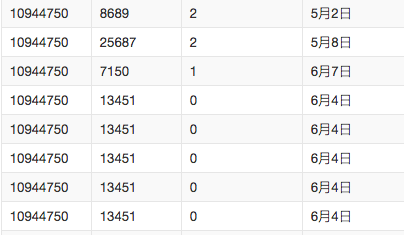
数据源:本数据源为天池大赛提供数据,数据按时间分为两份,分别是7月份之前的购买行为数据和7月份之后的。具体字段如下:
| 字段名 | 含义 | 类型 | 描述 |
| user_id | 用户编号 | string | 购物的用户ID |
| item_id | 物品编号 | string | 被购买物品的编号 |
| active_type | 购物行为 | string | 0表示点击,1表示购买,2表示收藏,3表示购物车 |
| active_date | 购物时间 | string | 购物发生的时间 |

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
