
用户可以通过[backcolor=transparent]数据传输(
https://www.aliyun.com/product/dts)向 HybridDB for MySQL(原名PetaData) 中进行数据的全量和增量迁移。
准备工作

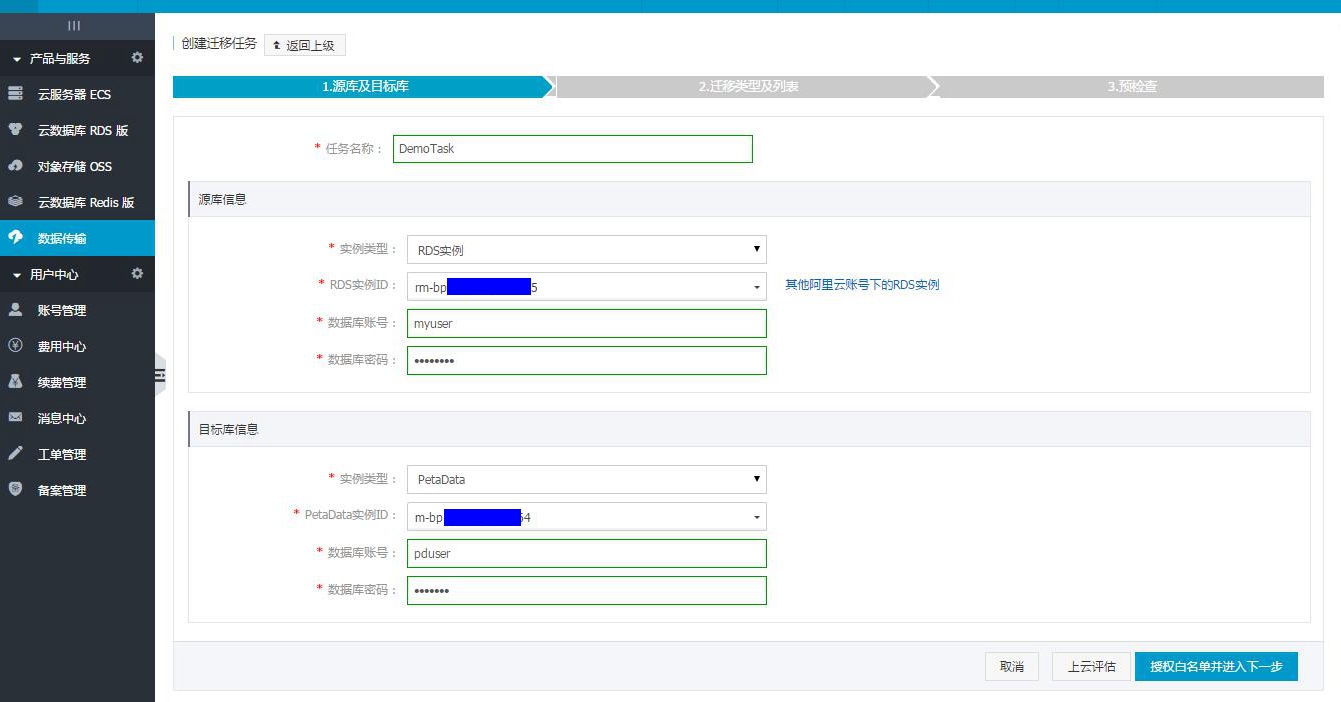

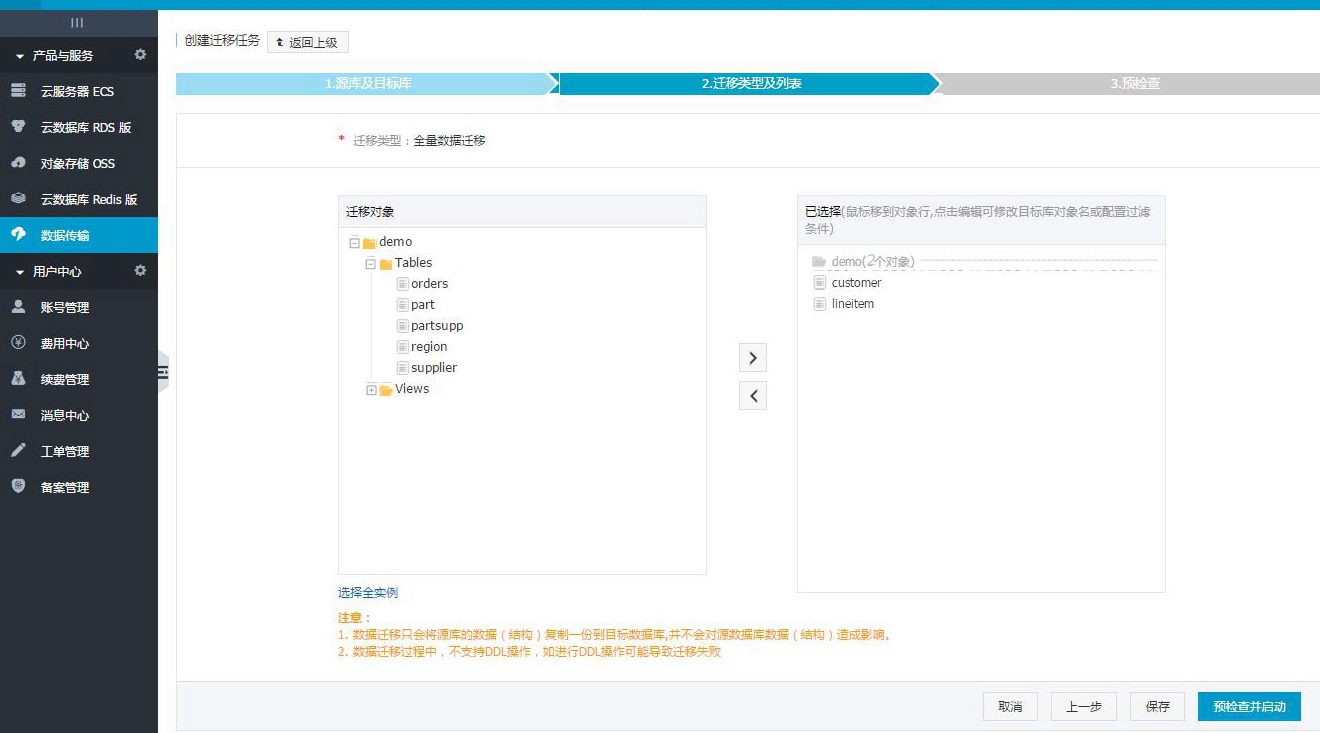
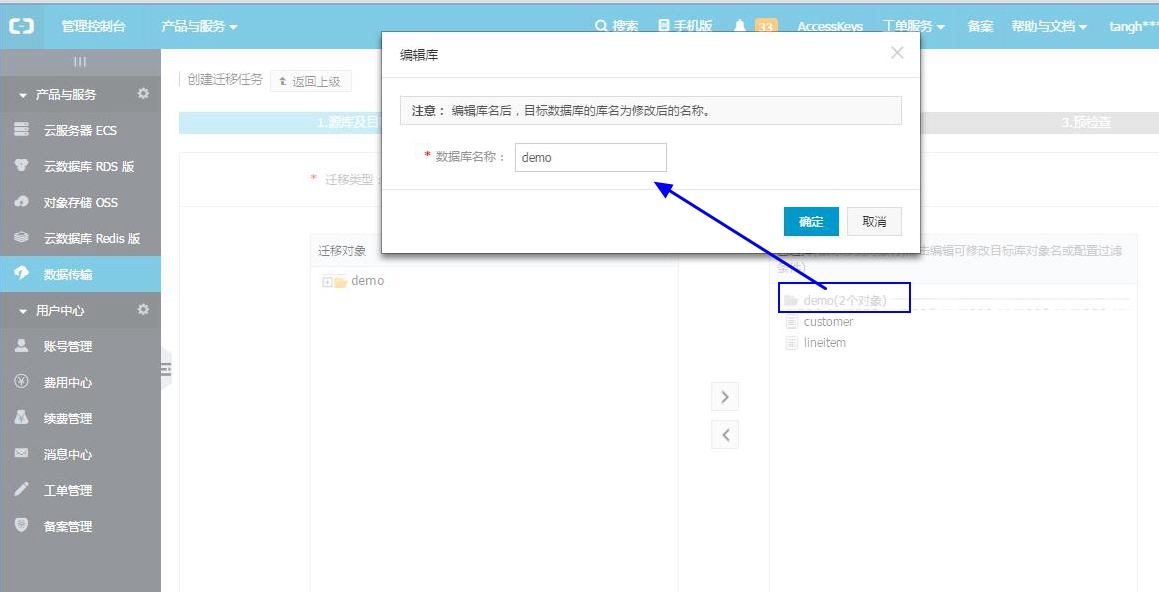
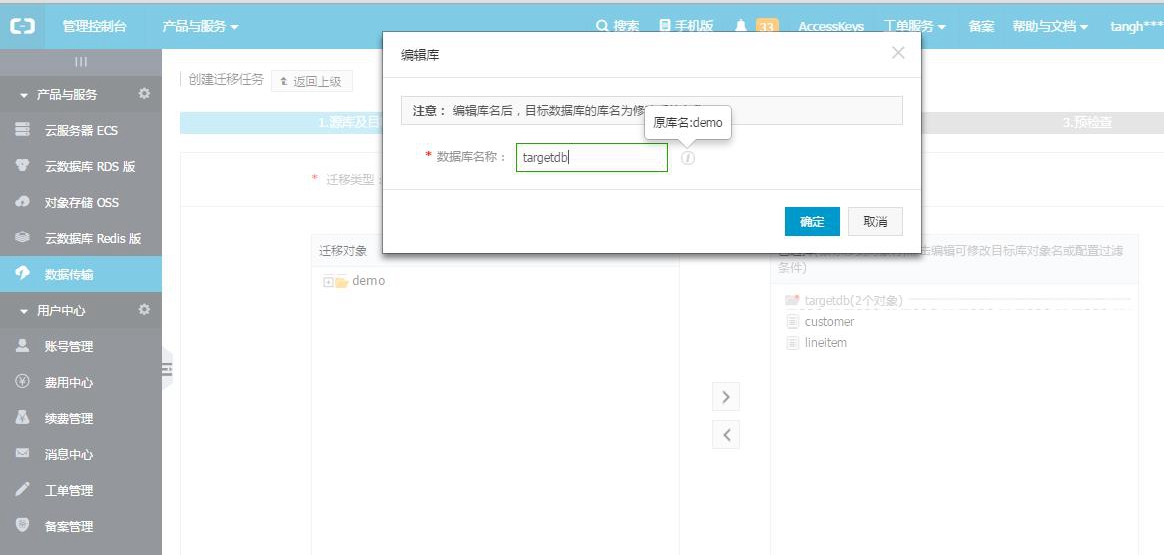
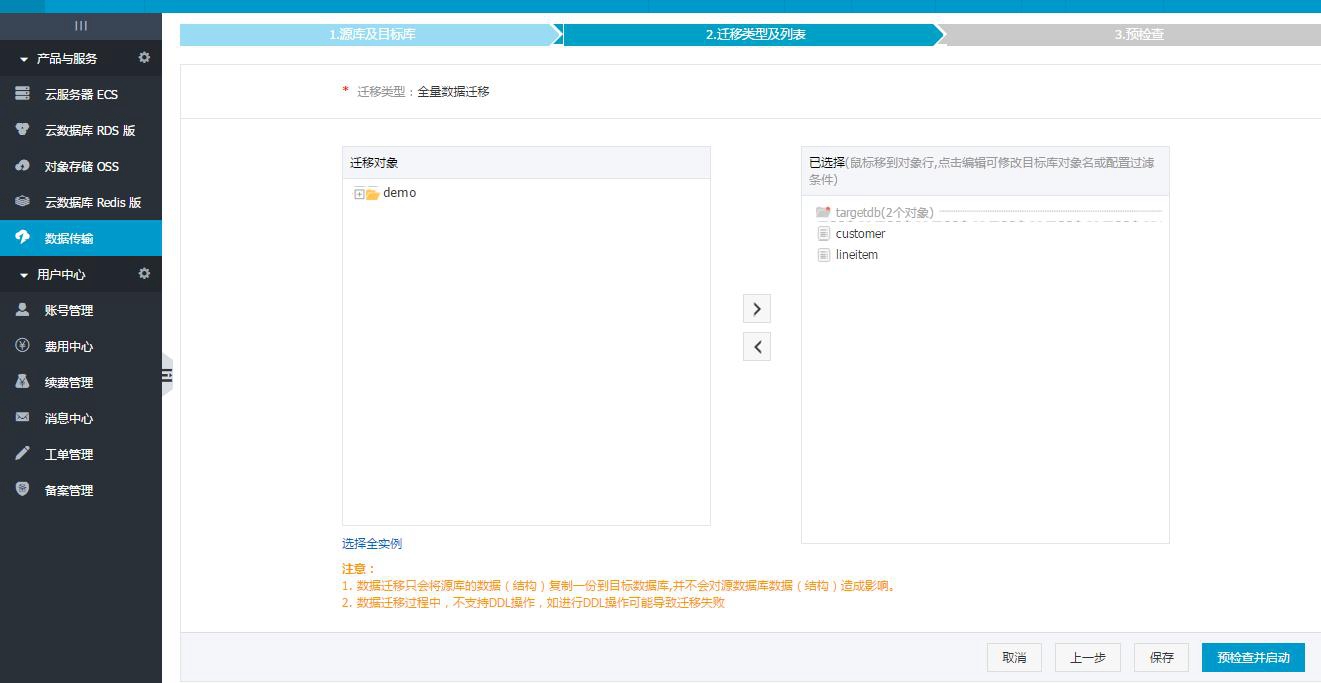 点击进行下一步预检查。
点击进行下一步预检查。
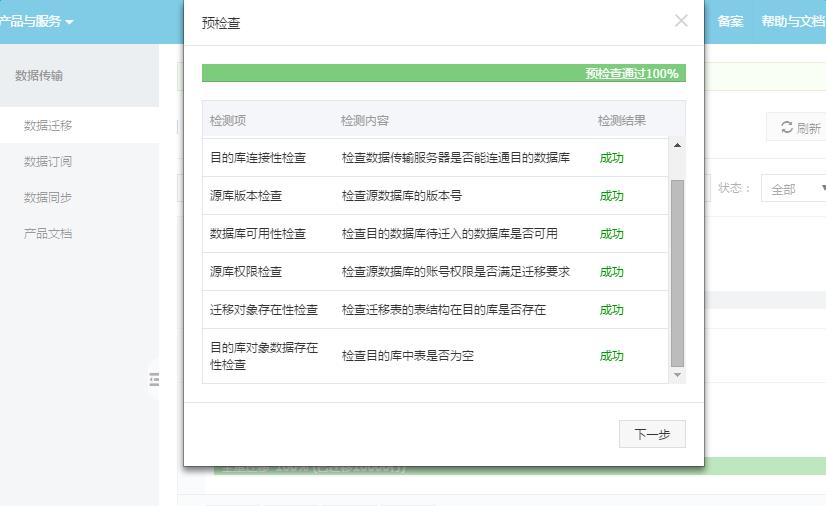
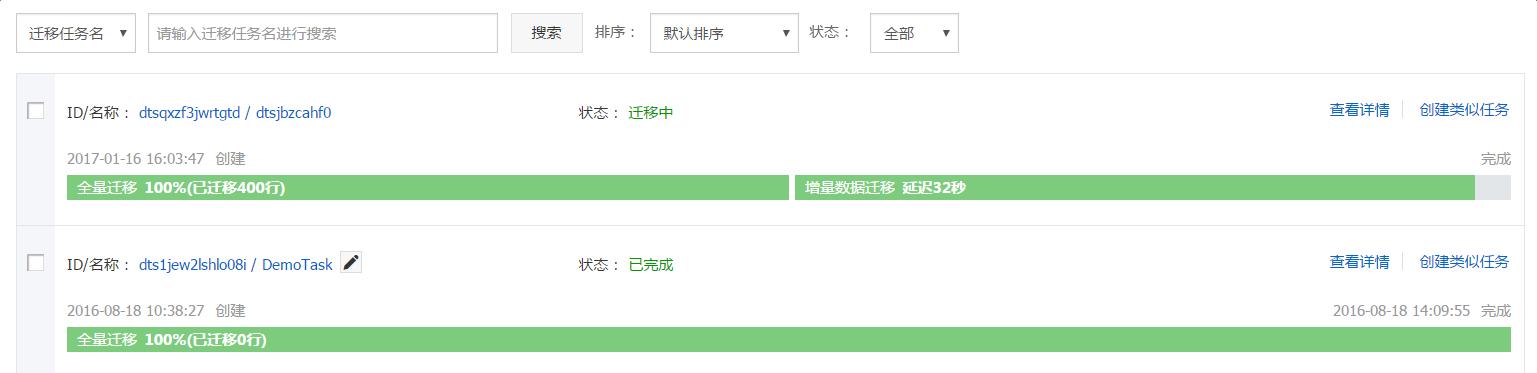
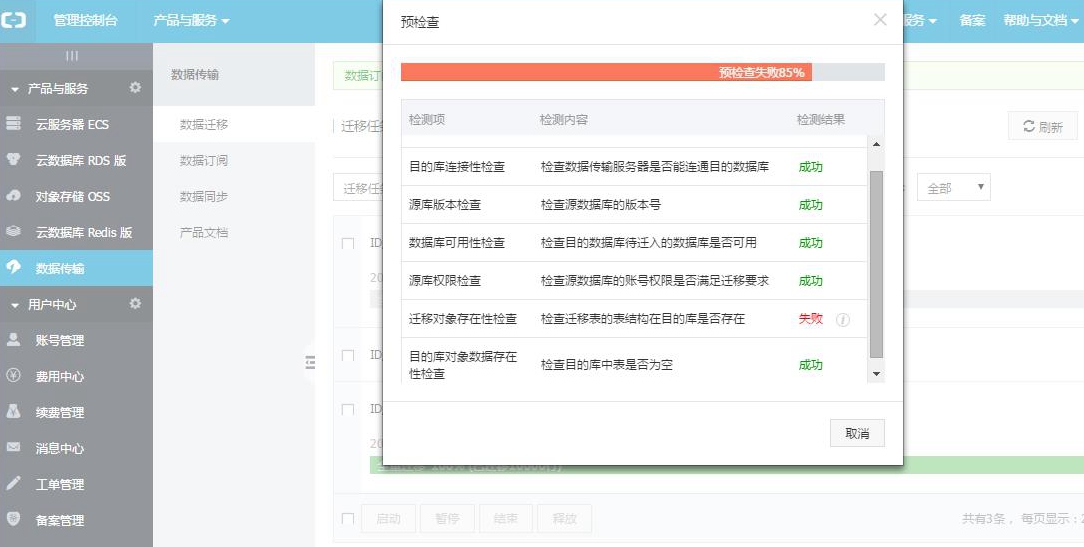 按提示信息纠正后,通过预检查,点击下一步。
按提示信息纠正后,通过预检查,点击下一步。
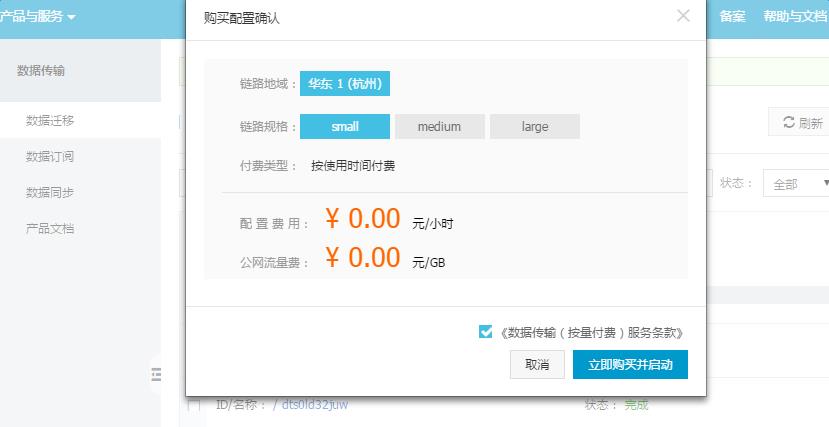
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您已经详细描述了如何使用阿里云数据传输服务(DTS)将数据从RDS for MySQL迁移到HybridDB for MySQL(原名PetaData)的全过程,包括准备工作、创建任务、配置源数据库和目标数据库、预检查以及启动迁移和查看结果。这个流程概括了通过DTS进行数据迁移的关键步骤,确保数据能够安全且高效地从源数据库同步到目标数据库。
这里补充几点注意事项和建议,帮助您更好地完成迁移任务:
权限与白名单:在配置源库与目标库时,确保使用的数据库账号具有足够的权限执行数据读写操作,并且记得添加DTS服务IP到源数据库和目标数据库的访问白名单中,以避免迁移过程中因网络访问限制导致的失败。
表结构兼容性:虽然您提到目标库中的表需要提前创建,但请注意检查源表和目标表的结构是否完全兼容。HybridDB for MySQL支持大部分MySQL语法,但也存在一些差异,特别是对于分区表、索引设计等特性,可能需要调整以适应HybridDB for MySQL的要求。
全量与增量同步:DTS支持全量迁移及增量数据同步,这意味着首次迁移会复制所有数据,之后持续捕捉并应用源数据库的新变化。在开始增量同步前,确认全量迁移已成功完成,且源数据库在此期间没有发生大量数据变更,以免数据不一致。
性能与时间规划:根据数据量大小和网络条件,全量迁移可能需要较长时间。合理安排迁移时间,避免业务高峰期,减少对在线服务的影响。同时,监控迁移过程中的性能指标,如迁移速度、延迟等,必要时可调整DTS的迁移速率设置。
测试验证:在正式迁移前,建议先进行小规模的数据迁移测试,验证数据的一致性和完整性。这可以通过创建一个测试数据库并在其中进行试迁移来实现。
备份:在开始任何迁移操作之前,确保对源数据库进行全面备份,这是数据迁移的最佳实践,以防迁移过程中出现不可预见的问题。
遵循上述步骤和建议,您可以有效地利用阿里云DTS服务完成向HybridDB for MySQL的数据迁移工作。
