
目前 E-MapReduce 集群中默认启动了 ZooKeeper服务。
注意事项
目前无论集群内有多少台机器,ZooKeeper 只会有 3 个节点。目前还不支持更多的节点。
创建集群
E-MapReduce 创建集群的软件配置页面,会默认勾选 ZooKeeper,如下图所示: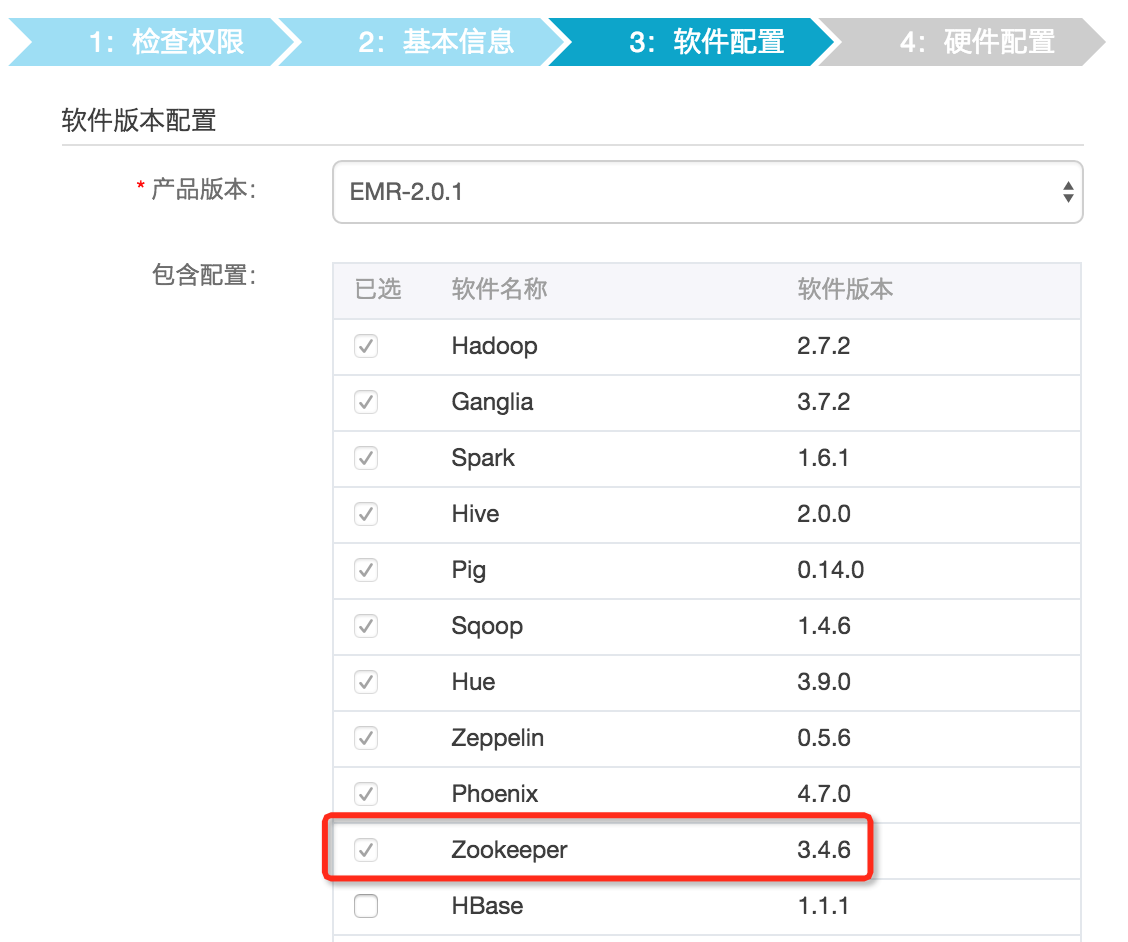
节点信息
集群创建成功,状态空闲后,查看集群的详情页面,可以查到 ZooKeeper 的节点信息,E-MapReduce 会启动 3 个 ZooKeeper节点。如下图所示,应用进程一栏标有 ZooKeeper 节点对应的内网 IP (端口默认为 2181),即可访问 ZooKeeper 服务。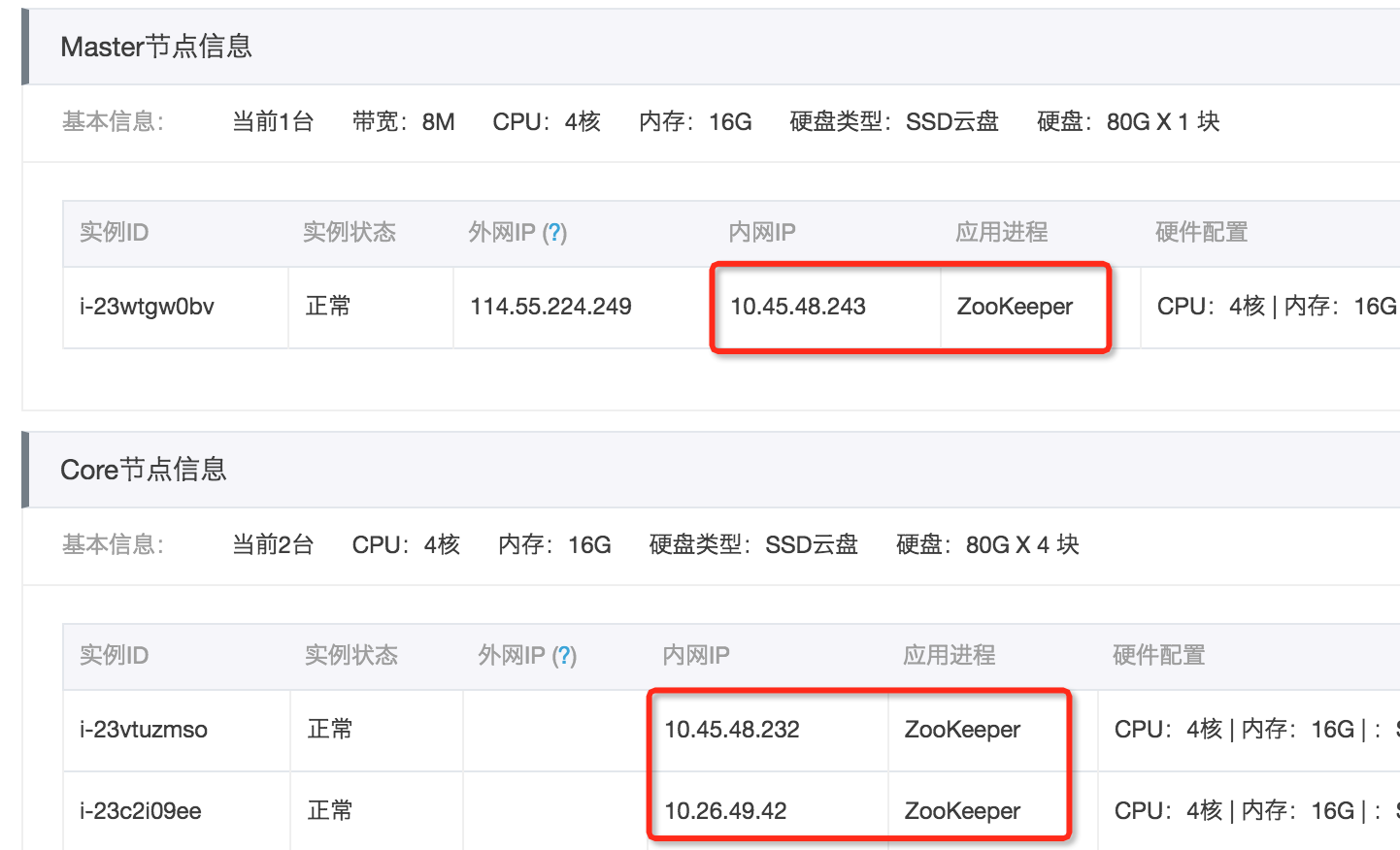
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
E-MapReduce是阿里云提供的一站式大数据处理平台,它基于Apache Hadoop和Apache Spark等开源技术构建,旨在简化大数据处理的集群搭建、运维和管理过程。在E-MapReduce集群中,默认集成ZooKeeper服务,这是非常关键的,因为ZooKeeper作为一个分布式协调服务,对于维护Hadoop生态中的各种组件(如HDFS、YARN)的高可用性和一致性至关重要。
您提到的,无论E-MapReduce集群内有多少台机器,ZooKeeper服务默认只启动3个节点,这是因为ZooKeeper设计时采用的是基于多数投票的故障容错机制。在最常见的配置中,奇数个节点可以确保系统在部分节点故障的情况下仍能维持服务的正常运行,3个节点是最小的能够容忍一个节点故障的配置。因此,即使您的集群规模很大,ZooKeeper服务也保持这个最小高可用配置,以保证系统的稳定性和资源的有效利用。
在使用E-MapReduce创建集群的过程中,软件配置页面会自动勾选ZooKeeper服务,这意味着用户无需手动干预即可获得一个预配置好的ZooKeeper环境。这大大简化了集群的部署流程,特别是对于那些希望快速开始大数据处理任务的用户来说,是一个非常便利的特性。
一旦集群创建成功并处于空闲状态,用户可以通过E-MapReduce控制台查看集群详情,获取到ZooKeeper服务的具体节点信息。这些信息包括每个ZooKeeper节点对应的内网IP地址以及默认使用的端口2181。了解这些信息对于后续配置其他依赖于ZooKeeper的服务(比如HBase、Kafka等)非常重要。
虽然当前E-MapReduce不支持自定义增加ZooKeeper节点数量,但其默认配置已经能满足大多数场景下的需求,确保了服务的高可用性。如果您的应用场景有特殊需求,比如需要更多的ZooKeeper节点来支撑更复杂的集群架构,建议关注E-MapReduce的官方更新或者联系阿里云技术支持,了解是否有新的功能发布或寻求专业的解决方案建议。
总之,E-MapReduce通过自动化集成和管理ZooKeeper,降低了大数据应用的部署复杂度,使得用户可以更加专注于数据处理和分析任务本身。
