
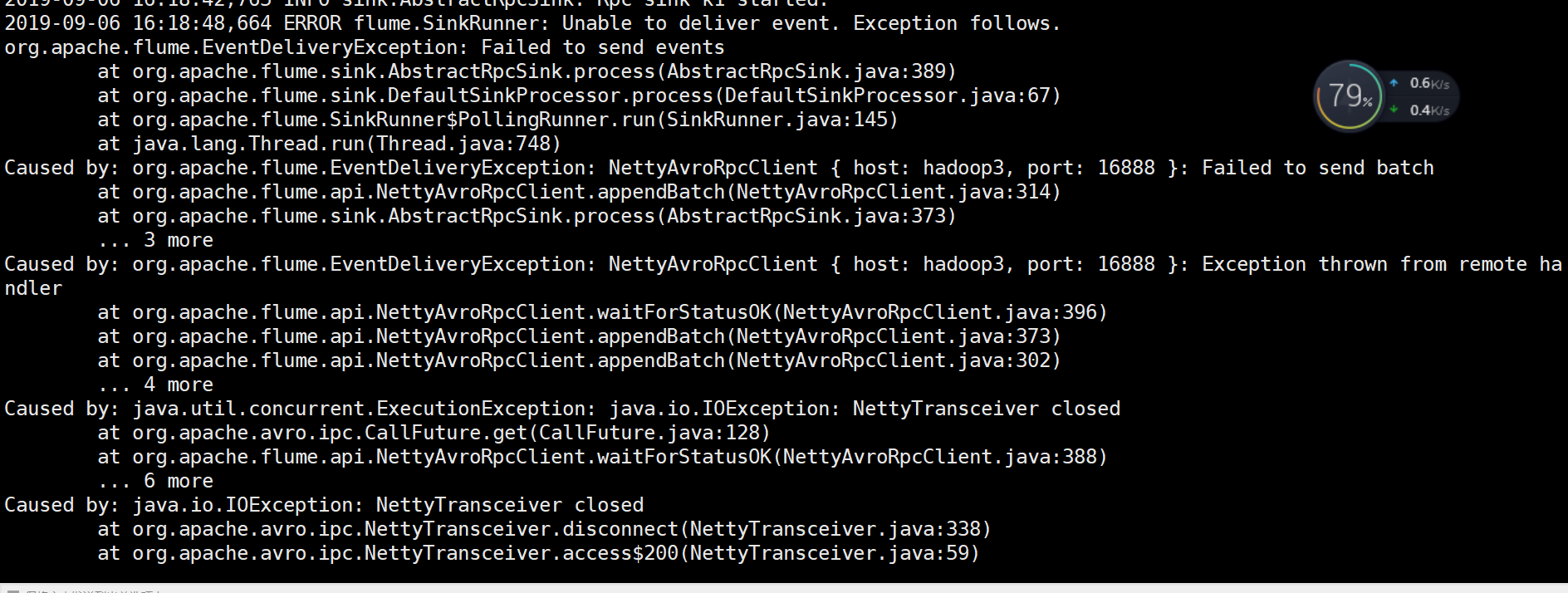
 hadoo1使用tail -f 检测文本,然后使用arvo sink传到hadoop3,hadoop3使用avro source logger打印 然后尝试了好多办法,都不行,今天换成flume1.6就没问题了,啥也没改
hadoo1使用tail -f 检测文本,然后使用arvo sink传到hadoop3,hadoop3使用avro source logger打印 然后尝试了好多办法,都不行,今天换成flume1.6就没问题了,啥也没改
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
从你的描述来看,你最初可能遇到了使用Apache Hadoop(可能是Hadoop 2.x版本)与Apache Flume集成时的问题,具体是在尝试使用Avro Source和Sink进行日志传输时遇到困难。tail -f命令通常用于实时跟踪文件的末尾内容变化,而Avro是一种数据序列化系统,常用于在Hadoop生态系统中的组件间高效、跨语言地传输数据。
问题可能出在几个方面:
配置问题:Flume配置文件中的source、channel、sink配置可能有误,比如地址、端口不匹配,或者Avro相关的配置参数设置不当。
版本兼容性:不同版本的Hadoop和Flume之间可能存在兼容性问题。你提到换成Flume 1.6后问题得到解决,这可能是因为该版本的Flume与你使用的Hadoop版本有更好的兼容性。
网络或权限问题:防火墙设置、网络连接问题或文件系统的访问权限也可能会导致数据无法正确传输。
依赖冲突:如果项目中存在多个版本的Avro库,可能会引起类路径冲突,影响数据序列化和反序列化的正常工作。
资源限制:Hadoop或Flume运行时的资源限制(如内存不足)也可能导致进程异常终止。
解决方案回顾: - 检查配置:确保Flume的配置文件(如flume-conf.properties)中所有组件的配置都是正确的,包括source.type、channel.type、sink.type以及它们各自的参数。 - 版本匹配:确认所使用的Hadoop和Flume版本之间的兼容性。如果可能,参考官方文档或社区讨论来选择合适的版本组合。 - 环境验证:检查网络连通性,确保没有防火墙阻止通信,并且Flume有权限访问相关目录和文件。 - 依赖管理:清理并管理项目依赖,避免Avro库的版本冲突。 - 监控资源:使用系统监控工具检查运行时资源使用情况,必要时调整资源配置。
如果你已经通过升级到Flume 1.6解决了问题,但仍然对之前的问题原因感兴趣,可以尝试回溯并逐一排查上述可能的原因,以获得更深入的理解。同时,分享你的解决方案到阿里云开发者社区或相关技术论坛,可以帮助其他遇到类似问题的开发者。
