
 各位大佬看看hbase master的GC情况,堆内存配置位8G,region数量不到8万 看看参数配置有没有问题
各位大佬看看hbase master的GC情况,堆内存配置位8G,region数量不到8万 看看参数配置有没有问题
238节点,8万region也有点多
平均在350左右
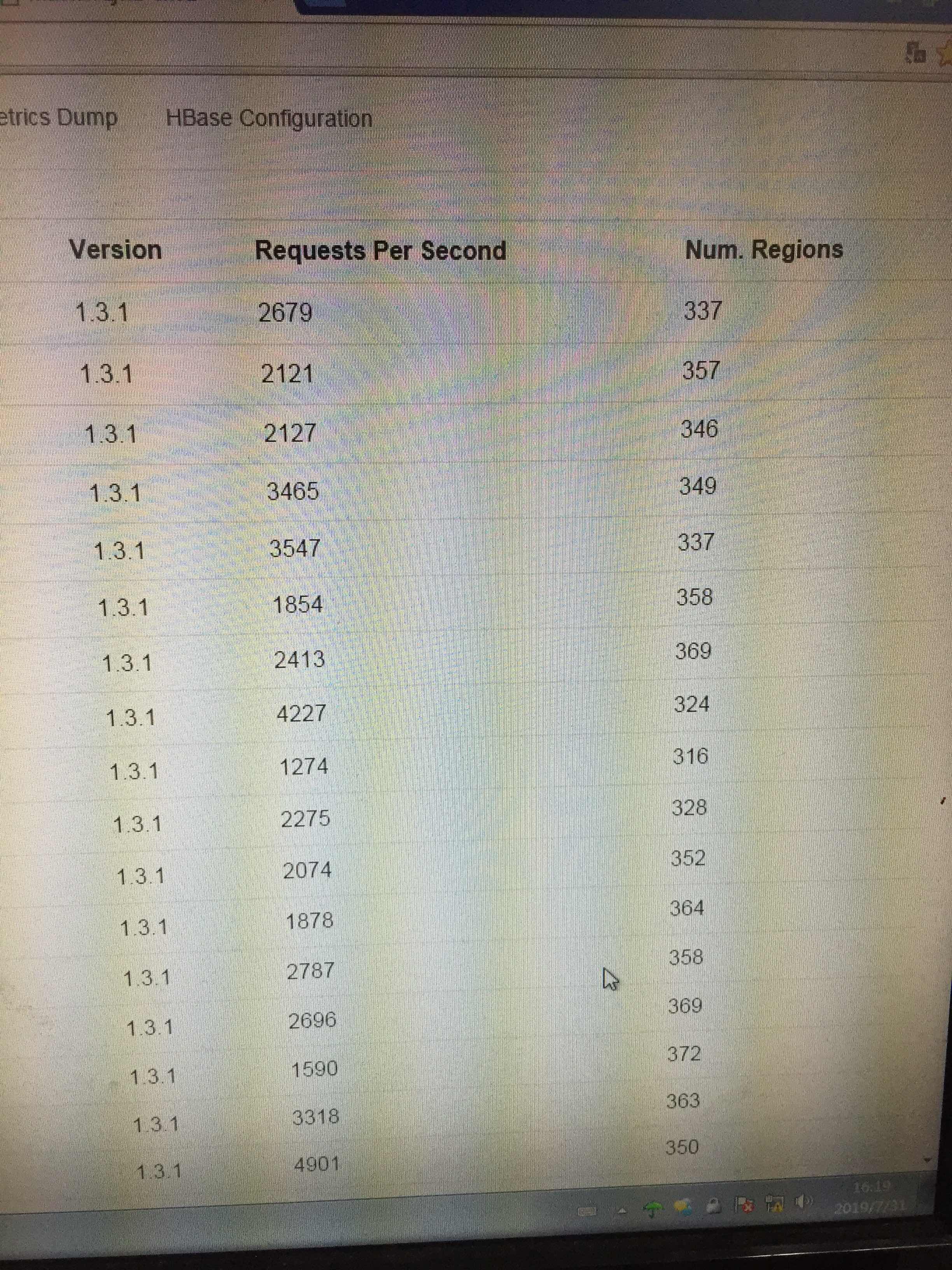
之后收集下每个 region 的qps,tps
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对您提到的HBase Master频繁进行垃圾回收(GC)的情况,以及配置和性能表现,这里提供一些建议来帮助分析和优化:
堆内存配置:您提到已将HBase Master的堆内存设置为8GB。对于Master节点而言,其主要职责是管理Region分配、监控RegionServer状态等元数据操作,而不是直接处理数据读写。通常情况下,Master并不需要处理大量数据,因此8GB的堆内存对大多数场景来说应该是足够的。但是,如果Master节点上运行了其他服务或者有额外的负担,可能会影响其性能。
Region数量:238个节点下管理不到8万个Region,这个比例看起来是合理的。每个RegionServer理论上可以管理成千上万的Region,但实际中应根据业务负载、查询模式等因素调整。过多的Region会增加Master的管理开销,包括但不限于内存占用、元数据操作的复杂度等。不过,您的情况似乎还未达到过度分割的程度。
GC活动频繁:平均GC时间在350ms左右,这表明可能存在一些压力导致垃圾回收较为频繁。虽然没有绝对的标准来判断GC是否过长,但频繁或长时间的GC可能会导致服务响应延迟。您可以考虑以下几点进行优化:
QPS/TPS收集:了解每个Region的QPS(每秒查询次数)和TPS(每秒事务数)对于诊断问题至关重要。高并发访问某些Region可能导致该RegionServer压力增大,间接影响到Master的管理任务。建议使用HBase内置的Metrics系统或第三方监控工具(如Prometheus+Grafana)来收集这些指标,并分析是否存在热点问题。
资源隔离与优化:确保HBase Master与其他服务(如RegionServer)在资源上得到良好的隔离,避免争抢CPU、网络或磁盘I/O资源。
最后,根据收集到的QPS/TPS数据,结合上述分析结果,进一步细化调整策略,比如重新平衡Region分布、优化读写路径、调整缓存策略等,以达到最佳性能。
