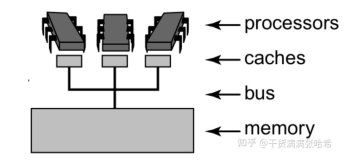
本系列是 The art of multipropcessor programming 的读书笔记,在原版图书的基础上,结合 OpenJDK 11 以上的版本的代码进行理解和实现。并根据个人的查资料以及理解的经历,给各位想更深入理解的人分享一些个人的资料
自旋锁与争用
3. 队列锁
之前实现的基于回退的锁,除了通用性以外,还有如下两个问题:
- CPU 高速缓存一致性流量:虽然由于回退存在,所以流量比 TASLock 要小,但是多线程访问锁的状态还是有一定因为缓存一致性导致的流量消耗的。
- 可能降低访问临界区的效率:由于所有线程的 sleep 延迟过大,导致当前所有线程都在 sleep,但是锁实际上已经释放。
可以将线程放入一个队列,来解决上面两个问题:
- 队列中,每个线程检查它的前驱线程是否已经完成,判断锁是否被释放,不用访问锁的状态。这样访问的是不同的内存,减少了锁释放修改状态导致的 CPU 高速缓存一致性流量
- 不需要 sleep,可以通过前驱线程告知线程锁被释放,尝试获取锁,提高了访问临界区的效率
最后,通过队列,也是实现了 FIFO 的公平性。
3.1. 基于数组的锁
我们通过一个数组来实现队列的功能,其流程是:
- 需要的存储:
- boolean 数组,为 true 则代表对应槽位的线程获取到了锁,为 false 则为对应槽位的线程没有获取到了锁
- 保存当前最新槽位的原子变量,每次上锁都会将这个原子变量加 1,之后对 boolean 数组的大小取余。这个值代表这个线程占用了 boolean 数组的这个位置,boolean 数组的这个位置的值代表这个线程是否获取到了锁。这也说明,boolean 数组的容量决定了这个锁同时可以有多少线程进行争用
- ThreadLocal,记录当前线程占用的 boolean 数组的位置
- 上锁流程:
- 原子变量 + 1,对 boolean 数组的大小取余得到 current
- 将 current 记录到 ThreadLocal
- 当 boolean 数组 cuurent 位置的值为 false 的时候,自旋等待
- 解锁流程:
- 从 ThreadLocal 中获取当前线程对应的位置 mine
- 将 boolean 数组的 mine 位置标记为 false
- 将 boolean 数组的 mine + 1 对数组大小取余的位置(防止数组越界)标记为 true
其源码是:
public class ArrayLock implements Lock { private final ThreadLocal<Integer> mySlotIndex = ThreadLocal.withInitial(() -> 0); private final AtomicInteger tail = new AtomicInteger(0); private final boolean[] flags; private final int capacity; public ALock(int capacity) { this.capacity = capacity; this.flags = new boolean[capacity]; } @Override public void lock() { int current = this.tail.getAndIncrement() % capacity; this.mySlotIndex.set(current); while (!this.flags[current]) { } } @Override public void unlock() { int mine = this.mySlotIndex.get(); this.flags[mine] = false; this.flags[(mine + 1) % capacity] = true; } }
在这个源码实现上,我们还可以做很多优化:
- 自旋等待可以不用强 Spin,而是 CPU 占用更低并且针对不同架构并且针对自旋都做了 CPU 指令优化的
Thread.onSpinWait()。 - boolean 数组的每个槽位需要做缓存行填充,防止 CPU false sharing 的发生导致缓存行失效信号过多发布。
- boolean 数组的更新需要是 volatile 更新,普通更新会延迟总线信号,导致其他等带锁的线程感知的更慢从而空转更多次。
- 取余是非常低效的运算,需要转化为与运算,对 2 的 n 次方取余相当于对 2 的 n 次方减去 1 取与运算,我们需要将传入的 capacity 值转化为大于 capacity 最近的 2 的 n 次方的值来实现。
this.flags[current]这个读取数组的操作需要放在循环外面,防止每次读取数组的性能消耗。
优化后的源码是:
public class ArrayLock implements Lock { private final ThreadLocal<Integer> mySlotIndex = ThreadLocal.withInitial(() -> 0); private final AtomicInteger tail = new AtomicInteger(0); private final ContendedBoolean[] flags; private final int capacity; private static class ContendedBoolean { //通过注解实现缓存行填充 @Contended private boolean flag; } //通过句柄实现 volatile 更新 private static final VarHandle FLAG; static { try { //初始化句柄 FLAG = MethodHandles.lookup().findVarHandle(ContendedBoolean.class, "flag", boolean.class); } catch (Exception e) { throw new Error(e); } } public ArrayLock(int capacity) { capacity |= capacity >>> 1; capacity |= capacity >>> 2; capacity |= capacity >>> 4; capacity |= capacity >>> 8; capacity |= capacity >>> 16; capacity += 1; //大于N的最小的2的N次方 this.flags = new ContendedBoolean[capacity]; for (int i = 0; i < this.flags.length; i++) { this.flags[i] = new ContendedBoolean(); } this.capacity = capacity; this.flags[0].flag = true; } @Override public void lock() { int current = this.tail.getAndIncrement() & (capacity - 1); this.mySlotIndex.set(current); ContendedBoolean contendedBoolean = this.flags[current]; while (!contendedBoolean.flag) { Thread.onSpinWait(); } } @Override public void unlock() { int mine = this.mySlotIndex.get(); FLAG.setVolatile(this.flags[mine], false); FLAG.setVolatile(this.flags[(mine + 1) & (capacity - 1)], true); } }
但是,即使有这些优化,在高并发大量锁调用的时候,这个锁的性能依然会很差。这个我们之后会分析优化。