
1. 基本介绍
- 如果要想灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为:
- 限定符
- 选择匹配符
- 分组组合和反向引用符
- 特殊字符
- 字符匹配符
- 定位符
2. 元字符(Metacharacter)-转义号 \
\\符号说明:在使用正则表达式去检索某些特殊字符的时候,需要用到转义符号,否则检索不到结果,甚至会报错的。- 案例:用
$去匹配“abc$(”,用(去匹配 “abc$(abc(123(”
String content = "abc$(abc(123(";
String regStr = "\\(";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}

- 需要用到转义符号的字符有以下:
.*+()$/\?[] ^{}
3. 元字符-字符匹配符


匹配任意三个数字
\\d\\d\\d = \\d{
3}
?表示后面是0个数字或1个数字
\\d{
3}(\\d)?
相当于对 \\d 取反,表示匹配单个非数字字符
\\D = [^0-9]
+ 表示1个或多个,至少一个
\\W+\\d{
2}
String regStr = "[a-z]";//匹配 a-z 之间任意一个字符
String regStr = "[A-Z]";//匹配 A-Z 之间任意一个字符
String regStr = "abc";//匹配 abc 字符串[默认区分大小写]
String regStr = "(?i)abc";//匹配 abc 字符串[不区分大小写]
3.1 案例
- [a-z]表示可以匹配a-z中任意一个字符,比如[A-Z]去匹配 11A22B33C
String content = "11A22B33C";
String regStr = "[A-Z]";
Pattern pattern = Pattern.compile(regStr)
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}

- java正则表达式默认是区分字母大小写的,如何实现不区分大小写
(?i)abc:表示abc都不区分大小写
a(?i)bc:表示bc不区分大小写
a((?i)b)c:表示只有b不区分大小写
Pattern pat = Pattern.compile(regEx, Pattern.CASE_INSENSITIVE);
- 当创建 Pattern 对象时,指定
Pattern.CASE_INSENSITIVE, 表示匹配是不区分字母大小写
Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);
[A-Z]表示可以匹配 A-Z 中任意一个字符[0-9]表示可以匹配 0-9 中任意一个字符
String regStr = "abc";//匹配 abc 字符串[默认区分大小写]
String regStr = "(?i)abc";//匹配 abc 字符串[不区分大小写]
[^a-z]表示可以匹配不是a-z中的任意一个字符
String content = "11A22B33CabcABC";
String regStr = "[^a-z]"; // 匹配不在 a-z 之间的任意一个字符
Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}

String regStr = "[^a-z]{2}"; // 匹配不在 a-z 之间的任意两个字符

String regStr = "[^0-9]"; // 匹配不在 0-9 之间的任意一个字符

[abcd]表示可以匹配abcd中的任意一个字符
String content = "1A2B3CabeABE";
String regStr = "[abcd]";
//当创建 Pattern 对象时,指定 Pattern.CASE_INSENSITIVE, 表示匹配是不区分字母大小写
Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}

[^abcd]表示可以匹配不是abcd中的任意一个字符\\d表示可以匹配0-9的任意一个数字,相当于[0-9]\\D表示可以匹配不是0-9中的任意一个数字,相当于[^0-9]\\w匹配任意英文字符、数字和下划线,相当于[a-zA-Z0-9_]\\W相当于[^a-zA-Z0-9],是\w刚好相反\\s匹配任何空白字符(空格,制表符等)\\S匹配任何非空白字符,和\s相反.匹配出\n之外的所有字符,如果要匹配,本身则需要使用\\.
4. 元字符-选择匹配符
- 在匹配某个字符串的时候是选择性的,即:既可以匹配这个,又可以匹配那个,这时需要用到选择匹配符号

- 案例:
```java
String content = "AA兮BB动CC人";
String regStr = "兮|动|人";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}

# 5. 元字符-限定符
- 用于指定其前面的字符和组合项连续出现多少次
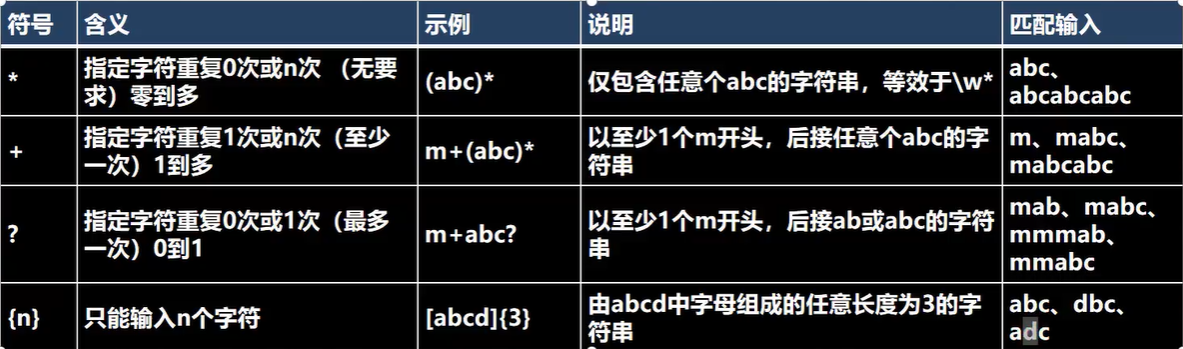

```bash
*:表示0或n个,0到多,[0, ∞)
+:表示至少1个,1到多,[1, ∞)
?:表示至多一个,0或1,[0, 1]
{n}:表示任意长度为n的字符串
{n,}:表示组成的任意长度不小于n的字符串,[n, ∞)
{n,m}:表示组成的任意长度不小于n、不大于m的字符串,[n,m]
- 案例:
1、n表示出现的次数,比如:a{3},1{4},\\d{2}
String context = "111111aaa";
// 表示匹配 aaa
String regStr = "a{3}";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}

下面有 7个 1,但只能匹配到一组
String context = "1111111aaa"; // 表示匹配连续4个1 String regStr = "1{4}";
有7个1,但只能匹配到3组
// 表示匹配长度为2的任意数字字符 String context = "1111111aaa"; String regStr = "\\d{2}";
注意: Java匹配默认是贪婪匹配,即尽可能匹配多的
String context = "1111111aaaa33333"; // 表示匹配 aaa 或 aaaa String regStr = "a{3,4}"; Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(context); while (matcher.find()) { System.out.println("找到 " + matcher.group(0)); }- 优先匹配 4个a的情况

- 如:换成6个a的情况下,如果每次都匹配3个a就正好匹配到,但Java默认的是贪婪模式,尽可能的匹配多的,所以就先匹配4个a,余下2个a就不会被匹配到
String context = "1111111aaaaaa33333";

\\d{2,5},下面有7个1,先匹配前5个1,后面2个1也符合长度范围,都能被匹配到String context = "1111111aaaaaa"; // 表示匹配长度为 [2,5]之间的数字字符 String regStr = "\\d{2,5}";
1+:默认还是贪婪匹配,所以会一次性全部匹配到7个1
String context = "1111111aaaaaa";
String regStr = "1+";

\\d+:匹配一个数字或多个数字String context = "1111111aaaaaa"; // 匹配一个数字或多个数字 String regStr = "\\d+";
1*:匹配0个1或多个1a1?:匹配 a 或 a1
String context = "a11111111aaaaaa";
String regStr = "a1?";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}
还是会遵循贪心匹配原则,先匹配 a1,再匹配 a

换成
a2?,由于没有 a2 ,所以只能匹配到 a
6. 元字符-定位符
- 定位符, 规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置

1、^
- 指定起始字符
```java
String context = "123abc";
// 以至少1个数字开头,后接任意个小写字母的字符串
String regStr = "^[0-9]+[a-z]*";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}
- 内容改为:`String context = "123abc12";`也还是可以匹配到

- 内容改为:`String context = "123";`也还是可以匹配到

2、`$`
- 指定结束字符
```java
String context = "123abc";
// 以至少1个数字开头,以至少一个小写字母结尾
String regStr = "^[0-9]+[a-z]+$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}

String context = "123-a";
String regStr = "^[0-9]+\\-[a-z]+$";

3、\\b
- 匹配目标字符串的边界,这里的边界是指被匹配的字符串的最后,也可以是空格的字符串后面
String context = "xdrxidongren asdfxdr qwerxdr";
// 表示匹配边界是 xdr,这里的边界是指被匹配的字符串的最后,也可以是空格的字符串后面
String regStr = "xdr\\b";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}

4、\\B
- 匹配目标字符串的非边界
String context = "xdrxidongren asdfxdr qwerxdr";
String regStr = "xdr\\B";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}

7. 分组
7.1 捕获分组

1、非命名分组
String context = "xdrxidongren xdr1998 qwer2008xdr";
// 匹配4个数字的字符串
String regStr = "(\\d\\d)(\\d\\d)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
System.out.println("第1个分组内容 " + matcher.group(1));
System.out.println("第2个分组内容 " + matcher.group(2));
}

- 分成3组
String context = "xdrxidongren xdr1998 qwer2008xdr";
String regStr = "(\\d\\d)(\\d)(\\d)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
System.out.println("第1个分组内容 " + matcher.group(1));
System.out.println("第2个分组内容 " + matcher.group(2));
System.out.println("第3个分组内容 " + matcher.group(3));
}

2、命名分组
- 即可以给分组取名
String context = "xdrxidongren xdr1998 qwer2008xdr";
// 命名分组
String regStr = "(?<group1>\\d\\d)(?<group2>\\d\\d)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
System.out.println("第1个分组内容 " + matcher.group(1));
System.out.println("第1个分组内容[通过组名] " + matcher.group("group1"));
System.out.println("第2个分组内容 " + matcher.group(2));
System.out.println("第2个分组内容[通过组名] " + matcher.group("group2"));
}

7.2 非捕获分组

1、(?:pattern)
String context = "xdr兮动人123 yunxdr兮动人456 兮动人789qwer";
// String regStr = "兮动人123|兮动人456|兮动人789";
// 上面的写法可以等价于非捕获分组,注意:非捕获分组不能使用 matcher.group(1)
String regStr = "兮动人(?:123|456|789)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}

2、(?=pattern)
- 只匹配有选项的内容
String context = "xdr兮动人123 yunxdr兮动人456 兮动人789qwer"; // 非捕获分组不能使用 matcher.group(1) String regStr = "兮动人(?:123|456)"; Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(context); while (matcher.find()) { System.out.println("找到 " + matcher.group(0)); }
3、(?!pattern)
- 和
(?=pattern)取反,匹配选项中非的情况
String context = "xdr兮动人123 yunxdr兮动人456 兮动人789qwer";
// 查出不是 兮动人123 和 兮动人456 的内容
String regStr = "兮动人(?!123|456)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}
- 最后会匹配到 兮动人789 中的 兮动人

8. 非贪婪匹配
// 默认是贪婪匹配,会尽量匹配最多的字符串
String context = "xdr630 yunxdr";
String regStr = "\\d+";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
while (matcher.find()) {
System.out.println("找到 " + matcher.group(0));
}

- 改为非贪婪匹配(尽量匹配少的),就会一次只匹配一个数字
String regStr = "\\d+?";

9. 应用实例
- 对字符串进行如下验证
1、汉字
String context = "兮动人";
// 汉字
String regStr = "^[\u0391-\uffe5]+$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}

2、邮政编码,要求:1-9 开头的一个六位数,比如:352189
String context = "352189";
String regStr = "^[1-9]\\d{5}$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}
3、QQ号码,要求:1-9 开头的一个(5 位数-10位数) ,如: 1123762674
String context = "1123762674";
String regStr = "^[1-9]\\d{4,9}$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}
4、手机号码,要求:必须以 13,14,15,18 开头的 11 位数
String context = "15933567680";
String regStr = "^1[3|4|5|8]\\d{9}";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}
10. 正则验证复杂URL
- 如:匹配B站视频的url
/** * 思路: * 1.先确定url的开始部分 https:// | http:// * 2.通过 ([\w-]+\.)+[\w-]+ 匹配 www.bilibili.com * 3. /video/BV1QA41187CL 匹配 */ String content = "https://www.bilibili.com/video/BV1QA41187CL"; // 注意:[.]表示匹配的就是.本身 String regStr = "^((http|https)://)([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.]*)?$"; Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(content); if (matcher.find()) { System.out.println("满足格式"); } else { System.out.println("不满足格式"); }
