云hbase+spark_个人页
云hbase+spark


文章
36
问答
58
视频
0
个人介绍
暂无个人介绍
擅长的技术
- Java
- Python
- 前端开发
- Linux
- 数据库
获得更多能力

通用技术能力:
-
Java
初级
能力说明:
了解变量作用域、Java类的结构,能够创建带main方法可执行的java应用,从命令行运行java程序;能够使用Java基本数据类型、运算符和控制结构、数组、循环结构书写和运行简单的Java程序。
-
前端开发
高级
能力说明:
掌握企业中如何利用常见工具,进行前端开发软件的版本控制与项目构建和协同。开发方面,熟练掌握Vue.js、React、AngularJS和响应式框架Bootstrap,具备开发高级交互网页的能力,具备基于移动设备的Web前端开发,以及Node.js服务器端开发技能。
云产品技术能力:
暂时未有相关云产品技术能力~
阿里云技能认证
详细说明
暂无更多信息
2019年10月
-
10.28 20:43:49
 发表了文章
2019-10-28 20:43:49
发表了文章
2019-10-28 20:43:49
X-Pack Spark 访问OSS
简介 对象存储服务(Object Storage Service,OSS)是一种海量、安全、低成本、高可靠的云存储服务,适合存放任意类型的文件。容量和处理能力弹性扩展,多种存储类型供选择,全面优化存储成本。
2019年09月
-
09.25 10:20:16发表了文章
2019-09-25 10:20:16
阿里云NoSQL X-Pack如何做到在线存储及计算一体?
大数据处理的挑战随着企业数据的逐渐积累和增多,数据架构从单节点的关系型数据库,演进到分库分表,再演进到NoSQL及hadoop生态。hadoop生态百花齐放,没有统一的架构标准,目前用的比较多的是Lambda架构,该架构主要特点为流计算、批处理、在线存储独立的,通过pipline来连接。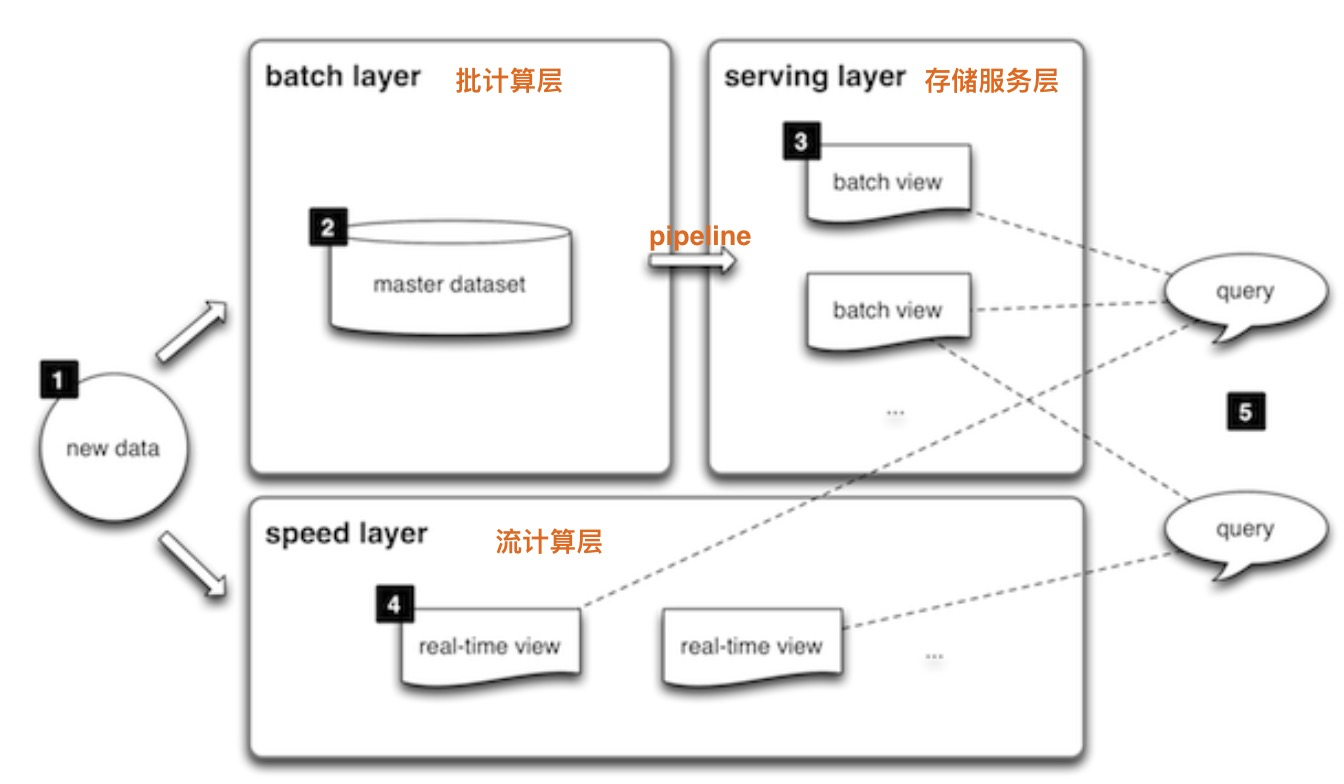
-
09.04 14:51:08
 回答了问题
2019-09-04 14:51:08
回答了问题
2019-09-04 14:51:08
yarn任务数超过9999查看方法
赞0 踩0 评论0 -
09.04 14:46:38
 提交了问题
2019-09-04 14:46:38
提交了问题
2019-09-04 14:46:38
-
09.04 12:01:17发表了文章
2019-09-04 12:01:17
X-Pack Spark 监控指标详解
概述 本文主要介绍X-Pack Spark集群监控指标的查看方法。Spark集群对接了Ganglia和云监控。下面分别介绍两者的使用方法。 Ganglia Ganglia是一个分布式监控系统。 Ganglia 入口 打开Spark集群依次进入:数据库连接>UI访问>详细监控UI>Ganglia。
2019年08月
-
08.20 18:04:37提交了问题
2019-08-20 18:04:37
-
08.20 11:48:23提交了问题
2019-08-20 11:48:23
-
08.17 22:38:08发表了文章
2019-08-17 22:38:08
SparkStreming:使用Checkpoint创建StreamingContext修改executor-cores、executor-memory等资源信息不生效。
在使用SparkStreaming时,使用StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)创建StreamingContext。 -
08.14 11:41:30回答了问题
2019-08-14 11:41:30
x-pack spark如何监控核心指标
赞0 踩0 评论0 -
08.14 11:34:51提交了问题
2019-08-14 11:34:51
2019年07月
-
07.29 11:14:08回答了问题
2019-07-29 11:14:08
-
07.25 15:32:21发表了文章
2019-07-25 15:32:21
X-Pack Spark使用[FAQ]
概述 本文主要列出在使用X-Pack Spark的FAQ。 Spark Connectors 主要列举Spark 对接其它数据源遇到的问题 Spark on HBase Spark on HBase Connector:如何在Spark侧设置HBase参数。 -
07.25 10:35:10发表了文章
2019-07-25 10:35:10
【降价信息】云HBase X-Pack最高降价31%,再次释放大数据处理红利
阿里云中国站云HBase X-Pack中的Spark服务将于2019年7月16日进行价格下调。 -
07.24 15:06:47发表了文章
2019-07-24 15:06:47
Spark on HBase Connector:如何在Spark侧设置HBase参数
前言 X-Pack Spark可以使用Spark on HBase Connector直接对接HBase数据库,读取HBase数据表数据。有时在读取HBase时需要设置HBase的一些参数调整性能,例如通过设置hbase.client.scanner.caching的大小调整读取HBase数据的性能。 -
07.22 18:01:58发表了文章
2019-07-22 18:01:58
Spark on Phoenix 4.x Connector:如何在Spark侧设置Phoenix参数
前言 X-Pack Spark可以使用Spark on Phoenix 4.x Connector直接对接Phoenix数据库,读取Phoenix数据表数据。有时在读取Phoenix时需要设置Phoenix的一些参数,例如Phoenix为了保障数据库的稳定性,默认开了索引包含,即查询Phoebe表必须要带上索引或者主键字段作为过滤条件。 -
07.08 17:37:24发表了文章
2019-07-08 17:37:24
Spark 通用的性能配置方法:内存和CPU的配置
前言 本文主要介绍关于通过配置Spark任务运行时的内存和CPU(Vcore)来提升Spark性能的方法。通过配置内存和CPU(Vcore)是比较基础、通用的方法。本文出现的Demo以X-Pack Spark数据工作台为背景介绍,数据工作台的详细介绍请参考:数据工作台。
2019年06月
-
06.22 23:06:22发表了文章
2019-06-22 23:06:22
Spark入门介绍
前言 Spark自从2014年1.2版本发布以来,已成为大数据计算的通用组件。网上介绍Spark的资源也非常多,但是不利于用户快速入门,所以本文主要通从用户的角度来介绍Spark,让用户能快速的认识Spark,知道Spark是什么、能做什么、怎么去做。 -
06.22 12:07:28发表了文章
2019-06-22 12:07:28
如何使用X-Pack Spark的YarnUI、SparkUI、Spark日志、任务运行状况的分析
概述 X-Pack Spark目前是通过Yarn管理资源,在提交Spark 任务后我们经常需要知道任务的运行状况,例如在哪里看日志、怎么查看每个Executor的运行状态、每个task的运行状态,性能瓶颈点在哪里等信息。 -
06.20 15:00:31发表了文章
2019-06-20 15:00:31
云Kafka搭配云HBase X-Pack构建一体化数据处理平台
云HBase X-Pack是基于Apache HBase、Phoenix、Spark深度扩展,融合Solr检索等技术,支持海量数据的一站式存储、检索与分析。融合云kafka+云HBase X-Pack能够构建一体化的数据处理平台,支持风控、推荐、检索、画像、社交、物联网、时空、表单查询、离线数仓等场景,助力企业数据智能化。 -
06.18 16:56:25发表了文章
2019-06-18 16:56:25
X-Pack Spark用户手册
概述 Spark是大数据平台的通用计算平台,应用非常广泛。本文主要介绍Spark相关的知识,主要包括:了解Spark,使用Spark,使用Spark过程中遇到的问题FAQ等,谨帮助用户快速的掌握Spark以及如何使用Spark。
-
发表了文章
2020-03-13
Dataworks同步数据到X-pack Spark
-
发表了文章
2019-10-28
X-Pack Spark 访问OSS
-
发表了文章
2019-09-25
阿里云NoSQL X-Pack如何做到在线存储及计算一体?
-
发表了文章
2019-09-04
X-Pack Spark 监控指标详解
-
发表了文章
2019-08-17
SparkStreming:使用Checkpoint创建StreamingContext修改executor-cores、executor-memory等资源信息不生效。
-
发表了文章
2019-07-25
X-Pack Spark使用[FAQ]
-
发表了文章
2019-07-25
【降价信息】云HBase X-Pack最高降价31%,再次释放大数据处理红利
-
发表了文章
2019-07-24
Spark on HBase Connector:如何在Spark侧设置HBase参数
-
发表了文章
2019-07-22
Spark on Phoenix 4.x Connector:如何在Spark侧设置Phoenix参数
-
发表了文章
2019-07-08
Spark 通用的性能配置方法:内存和CPU的配置
-
发表了文章
2019-06-22
Spark入门介绍
-
发表了文章
2019-06-22
如何使用X-Pack Spark的YarnUI、SparkUI、Spark日志、任务运行状况的分析
-
发表了文章
2019-06-20
云Kafka搭配云HBase X-Pack构建一体化数据处理平台
-
发表了文章
2019-06-18
X-Pack Spark用户手册
-
发表了文章
2019-05-23
广告点击数实时统计:Spark StructuredStreaming + Redis Streams
-
发表了文章
2019-02-14
2019 HBase Meetup 演讲者和议题征集
-
发表了文章
2018-11-06
中国HBase技术社区第八届MeetUp ——HBase典型应用场景与实践(南京站)
-
发表了文章
2018-10-29
中国HBase技术社区第六届MeetUp ——HBase典型应用场景与实践
-
发表了文章
2018-10-29
中国HBase技术社区第七届MeetUp ——HBase技术与应用实践(成都站)
-
发表了文章
2018-09-10
中国HBase技术社区第五届MeetUp ——HBase技术解析及应用实践(深圳站)
滑动查看更多
-
提交了问题
2019-09-04
yarn任务数超过9999查看方法
-
回答了问题
2019-09-04
yarn任务数超过9999查看方法
由于Yarn 界面默认的排序方式是按照ID字典顺序,所以当Application ID超过9999后达到10000就会被排序在9999之后。这时可以按照StartTime排序就可以看到最新的Application ID,如下图:赞0 踩0 评论0 -
提交了问题
2019-08-20
spark如何处理struct、array、map等复杂类型
-
提交了问题
2019-08-20
spark如何处理复杂类型struct(json)、array、map
-
提交了问题
2019-08-14
x-pack spark如何监控核心指标
-
回答了问题
2019-08-14
x-pack spark如何监控核心指标
spark集群的云监控配置和hbase类似的,在云监控里面 查看 '系统指标'、'分析集群指标'。 spark层面主要关注的指标有几个: hdfs容量:使用指标 “实例存储空间使用比例”集群的计算资源容量:使用指标 “AvailableVCores”、“AvailableMB” https://help.aliyun.com/document_detail/95995.html?spm=5176.11065259.1996646101.searchclickresult.4fbf384bjLFkEm作业的运行情况:可以在数据工作台上面直接配置报警的dingding机器人,如果作业失败了可以提示 https://help.aliyun.com/document_detail/106546.html?spm=a2c4g.11186623.6.611.77a56cb5pLQIIastreaming作业的延迟相关报警:可以通过“StreamingInputRate(records/s)”、“StreamingLatency(ms)”配置 https://help.aliyun.com/document_detail/95995.html?spm=5176.11065259.1996646101.searchclickresult.4fbf384bjLFkEm赞0 踩0 评论0 -
回答了问题
2019-07-29
phoenxi写进去的主键id=1数据,在hBase中rowkey被转换为\x80\x00\x00\x01
phoenix写进去要用phoenix读出来 phoenix有自己的编码格式赞0 踩0 评论0 -
回答了问题
2019-07-17
maven引入phoenix一直报错!
参考下我们的demo项目:https://github.com/aliyun/aliyun-apsaradb-hbase-demo/blob/master/phoenix/phoenix-5.x/pom.xml用这个: 5.0.0-HBase-2.0 org.apache.phoenix phoenix-queryserver-client ${phoenix.version}赞0 踩0 评论0 -
回答了问题
2019-07-17
hbase的表要怎么设计
先确定查询场景,后设计表如果某查询条件一定存在,把这个条件放在Rowkey中,称为必要条件如果查询条件大概率存在,把这个条件放在rowkey中,但放在必要条件后面如果通过必要条件就可以把查询限定在一个小的范围,则其他条件可以放在普通列,通过Filter来查询如果一张表无法满足所有查询,则创建索引表赞0 踩0 评论0 -
回答了问题
2019-07-17
这是diff独有的吗?
这里的DIFF指的不是“DIFF”编码,对rowkey的这种处理是基本的,几乎所有的hbase编码都有赞0 踩0 评论0 -
回答了问题
2019-07-17
hbase 在新建表的时候 会提示"Family 'info' already exists, the old one will be replaced",有哪位大神指点一下
可能表(column family)已经存在了吧?有具体的复现步骤吗?赞0 踩0 评论0 -
回答了问题
2019-07-17
HBase2.0的WAL不会自动清理
可以尝试重启master赞0 踩0 评论0 -
回答了问题
2019-07-17
求助,phoenix mapping时如何避免产生写请求?
Phoenix mapping应该不写数据的赞0 踩0 评论0 -
回答了问题
2019-07-17
HBase的表分裂出72个region为什么没有balance呢?
shell看一下balance有没有打开,另外balance有周期要等一下赞0 踩0 评论0 -
提交了问题
2019-04-03
《Cassandra 权威指南》第二版书评及访谈
-
回答了问题
2019-07-17
《Cassandra 权威指南》第二版书评及访谈
可以参考:https://www.infoq.cn/article/cassandra-2nd-edition-book-review赞0 踩0 评论0 -
回答了问题
2019-07-17
Phoenix事务机制原理是怎么实现的?
不支持事务,只有行级锁,谢谢。赞0 踩0 评论0 -
回答了问题
2019-07-17
怎么获取我的hbase所有支持的配置项
1.官网 https://hbase.apache.org/book.html#hbase_default_configurations2.源码 hbase-site-default.xml3.HBase UI上可看到运行时所配置所有参数。赞0 踩0 评论0 -
回答了问题
2019-07-17
mysql 如何通过 Phoenix 实现实时同步数据
可以通过实时分析mysql binlog将数据同步到phoenix。目前阿里云内部已经实现,即将上线推出。赞0 踩0 评论0 -
回答了问题
2019-07-17
hbase写入很慢,但是集群负载也不高
这个可能有很多的原因,可能是 并发不足,比如写线程不高,客户端并发不高,或者region比较少赞0 踩1 评论0
滑动查看更多
暂无更多信息