apache_flink_个人页
apache_flink

文章
13
问答
12
视频
1
个人介绍
Apache Flink China是经过Apache Flink官方授权的中文社区。是旨在向国内宣传和普及Flink相关技术,输出技术博文、译作、资讯等内容,推动国内大数据技术发展的开源社区。
擅长的技术
- 数据库

暂无更多信息
2019年06月
-
06.25 17:09:44
 发表了文章
2019-06-25 17:09:44
发表了文章
2019-06-25 17:09:44
社区活动 | Apache RocketMQ × Apache Flink Meetup · 上海站
7 月 6 日,Apache Flink Meetup 再度回归魔都,来自阿里巴巴、网易的 Flink 技术专家联合 Apache RocketMQ 社区大咖来一场 Flink 与 RocketMQ 的邂逅,看看 Apache RocketMQ × Apache Flink 会碰撞出怎样的火花。 -
06.20 13:56:28发表了文章
2019-06-20 13:56:28
谈谈流计算中的『Exactly Once』特性
本文翻译自 streaml.io 网站上的一篇博文:“Exactly once is NOT exactly the same” ,分析了流计算系统中常说的『Exactly Once』特性,主要观点是:『精确一次』并不保证是完全一样。 -
06.20 12:02:41发表了文章
2019-06-20 12:02:41
原理解析 | Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
1. Apache Flink 应用程序中的 Exactly-Once 语义 2. Flink 应用程序端到端的 Exactly-Once 语义 3. 示例 Flink 应用程序启动预提交阶段 4. 在 Flink 中实现两阶段提交 Operator 5. 总结 -
06.20 11:47:37发表了文章
2019-06-20 11:47:37
从 Spark Streaming 到 Apache Flink : 实时数据流在爱奇艺的演进
本文将为大家介绍 Apache Flink 在爱奇艺的生产与实践过程。你可以借此了解到爱奇艺引入 Apache Flink 的背景与挑战,以及平台构建化流程。 -
06.14 15:28:55发表了文章
2019-06-14 15:28:55
如何从小白进化成 Apache Flink 技术专家?9节基础课程免费公开!
为了让大家更全面地了解 Apache Flink 背后的技术以及应用实践,今天,我们首次免费公开 Apache Flink 系列视频课程。 -
06.06 14:40:45发表了文章
2019-06-06 14:40:45
Apache Flink Meetup · 北京站
Apache Flink Community China Meetup,关于大数据、实时计算、流计算、批处理等。邀请到Apache Flink PMC和Airbnb、阿里巴巴多位 Apache Flink Committer 现场分享。
-
发表了文章
2019-06-25
社区活动 | Apache RocketMQ × Apache Flink Meetup · 上海站
-
发表了文章
2019-06-20
谈谈流计算中的『Exactly Once』特性
-
发表了文章
2019-06-20
原理解析 | Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
-
发表了文章
2019-06-20
从 Spark Streaming 到 Apache Flink : 实时数据流在爱奇艺的演进
-
发表了文章
2019-06-14
如何从小白进化成 Apache Flink 技术专家?9节基础课程免费公开!
-
发表了文章
2019-06-14
Blink 有何特别之处?菜鸟供应链场景最佳实践
-
发表了文章
2019-06-06
Apache Flink Meetup · 北京站
-
发表了文章
2019-04-17
为什么说流处理即未来?
-
发表了文章
2018-12-25
阿里重磅开源 Blink:为什么我们等了这么久?
-
发表了文章
2018-11-22
超燃!Apache Flink 全球顶级盛会强势来袭
-
发表了文章
2018-11-09
Apache Flink China Meetup 北京站 - 计算之美,何止于快
-
发表了文章
2018-10-30
Flink China 社区运营成果报告(7月-9月)
滑动查看更多
-
 提交了问题
2019-02-14
提交了问题
2019-02-14
flink啥时候出 hadoop3.0版本的呀
-
提交了问题
2019-02-14
用 RocksDBStateBackend 时出现了这个错误
-
提交了问题
2019-02-14
yarn运行yarn-session报错,有大神知道吗
-
提交了问题
2019-02-14
如图,ture ? false? 是什么意思?
-
提交了问题
2019-02-14
blink使用streaming的runtime实现batch,效率会降低吗?
-
提交了问题
2019-02-14
有一个作业跑一段时间后总是挂,查nodemanager日志发现是内存不够了,但是堆内存使用情况正常
-
 回答了问题
2019-07-17
回答了问题
2019-07-17
flink啥时候出 hadoop3.0版本的呀
成阳:blink内部版本使用hadoop 3.0版本的client,从而能使用到一些yarn 3.x才有功能(比如placement constraint)。但如果使用hadoop 3.0特有的api后,会导致flink在低版本的hadoop集群中不能正常运行。目前大部分yarn用户还是以hadoop 2.6为主,所以目前blink开源版对于hadoop的依赖是2.6及以上版本的。如果flink用户不需要hadoop 3.0特有的api的话,编译flink时用hadoop 2.6版本即可。我们已经测试过基于hadoop 2.6.5的flink能够正常运行在hadoop 3.x的集群中。赞0 踩0 评论0 -
回答了问题
2019-07-17
用 RocksDBStateBackend 时出现了这个错误
邱从贤:用 RocksDBStateBackend 时出现了这个错误追问:incremental 模式 这个没有,用的是 RocksDBStateBackend 他就是增量哈  邱从贤:那需要看下哪个 task 超时了,然后看下日志找找看为啥超时了追问:这个是错误日志,问了问度娘说:因为Mapred多个task操作同一个文件,一个task完成后删掉文件导致。 查看了下 dfs.datanode.max.xcievers 为 4096,难道这个值还是小了嘛 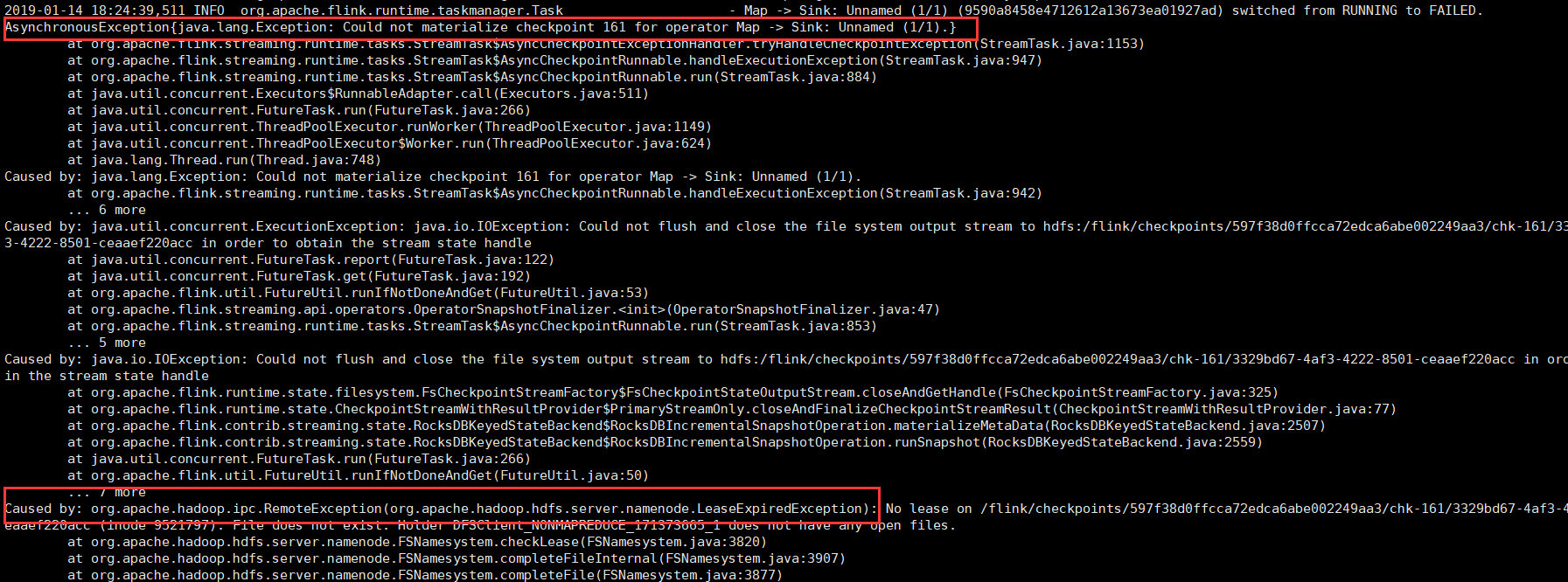 茶干:你这个错误实际上是expire 的checkpoint清理导致的task failover,root cause还是为啥你的checkpoint会超时,相关错误汇报可以参考 FLINK-10615和FLINK-10930赞0 踩0 评论0 -
回答了问题
2019-07-17
yarn运行yarn-session报错,有大神知道吗
无题:你看看 hdfs 那边的日志,我遇到的时候,是虚拟内存太底,导致不成功。赞0 踩0 评论0 -
回答了问题
2019-07-17
如图,ture ? false? 是什么意思?
澄水:false表示是撤回消息,true是插入或更新消息,这条query包含agg操作,从93->94需要先把93的结果撤回,然后发送更新结果94这控制台的已经是输出数据了,不用你控制赞0 踩0 评论0 -
回答了问题
2019-07-17
blink使用streaming的runtime实现batch,效率会降低吗?
在享受到流式处理优势的同时不会以牺牲吞吐位代价,首先checkpoint是增量异步的,overhead比较小对正常数据处理的影响很小,网络层的shuffle是以buffer为单位进行的,相当于micro batch吞吐很好,相比batch模式,下游提前启动了参与拉数据和处理,所以整体性能上会更好,除了资源占用会更多一些 绝顶:可以看一下FFC上蒋晓伟研究员讲的keynote,上面有tpc-ds和spark的对比数据https://files.alicdn.com/tpsservice/62fa5ebcd23ea0b8a956f2a06197b57a.pdf赞0 踩0 评论0 -
回答了问题
2019-07-17
有一个作业跑一段时间后总是挂,查nodemanager日志发现是内存不够了,但是堆内存使用情况正常
智笙:可以把gc日志打出来分析下墨简:堆内ok的话 堆外呢 有没有jni直接走malloc,new一类的赞0 踩0 评论0
滑动查看更多
