
程序员历小冰

已加入开发者社区2368天
勋章

MVP_Star
MVP_Star

开发者认证勋章
开发者认证勋章

初入江湖
初入江湖



我关注的人


粉丝

技术能力
兴趣领域
- Java
- Linux
- 数据库
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2021年04月
-
04.19 22:47:32
 发表了文章
2021-04-19 22:47:32
发表了文章
2021-04-19 22:47:32
ElasticSearch 如何使用 TDigest 算法计算亿级数据的百分位数?
今天,我们就来了解一下其聚合分析中较为常见的 percentiles 百分位数分析。n 个数据按数值大小排列,处于 p% 位置的值称第 p 百分位数。比如说,ElasticSearch 记录了每次网站请求访问的耗时,需要统计其 TP99,也就是整体请求中的 99% 的请求的最长耗时。
-
04.12 22:31:01发表了文章
2021-04-12 22:31:01
ElasticSearch 如何使用 ik 进行中文分词?
本篇文章则着重分析 ElasticSearch 在全文搜索前如何使用 ik 进行分词,让大家对 ElasticSearch 的全文搜索和 ik 中文分词原理有一个全面且深入的了解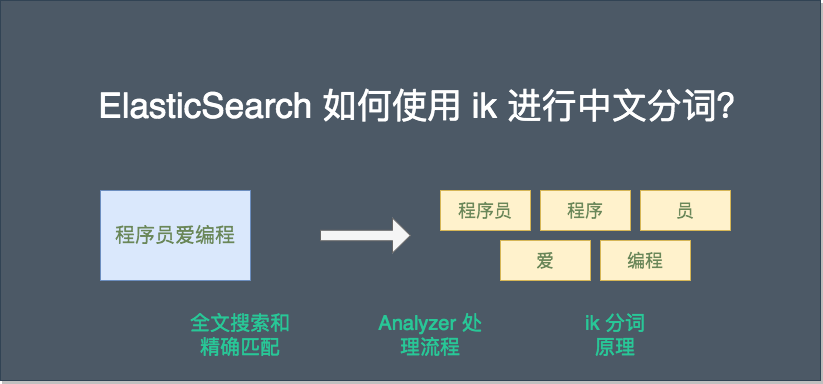
2021年03月
-
03.08 22:16:04发表了文章
2021-03-08 22:16:04
线上MySQL读写分离,出现写完读不到问题如何解决
今天我们来详细了解一下主从同步延迟时读写分离发生写后读不到的问题,依次讲解问题出现的原因,解决策略以及 Sharding-jdbc、MyCat 和 MaxScale 等开源数据库中间件具体的实现方案。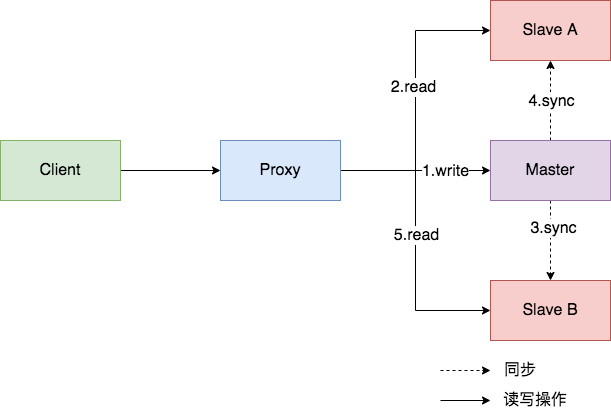
2021年02月
-
02.20 21:55:49发表了文章
2021-02-20 21:55:49
为什么ElasticSearch比MySQL更适合全文索引
熟悉 MySQL 的同学一定都知道,MySQL 对于复杂条件查询的支持并不好。MySQL 最多使用一个条件涉及的索引来过滤,然后剩余的条件只能在遍历行过程中进行内存过滤,上述这种处理复杂条件查询的方式因为只能通过一个索引进行过滤,所以需要进行大量的 I/O 操作来读取行数据,并消耗 CPU 进行内存过滤,导致查询性能的下降。 而 ElasticSearch 因其特性,十分适合进行复杂条件查询,是业界主流的复杂条件查询场景解决方案,广泛应用于订单和日志查询等场景。
2020年12月
-
12.03 21:28:53发表了文章
2020-12-03 21:28:53
一万字详解 Redis Cluster Gossip 协议
大家好,我是历小冰,今天来讲一下 Reids Cluster 的 Gossip 协议和集群操作。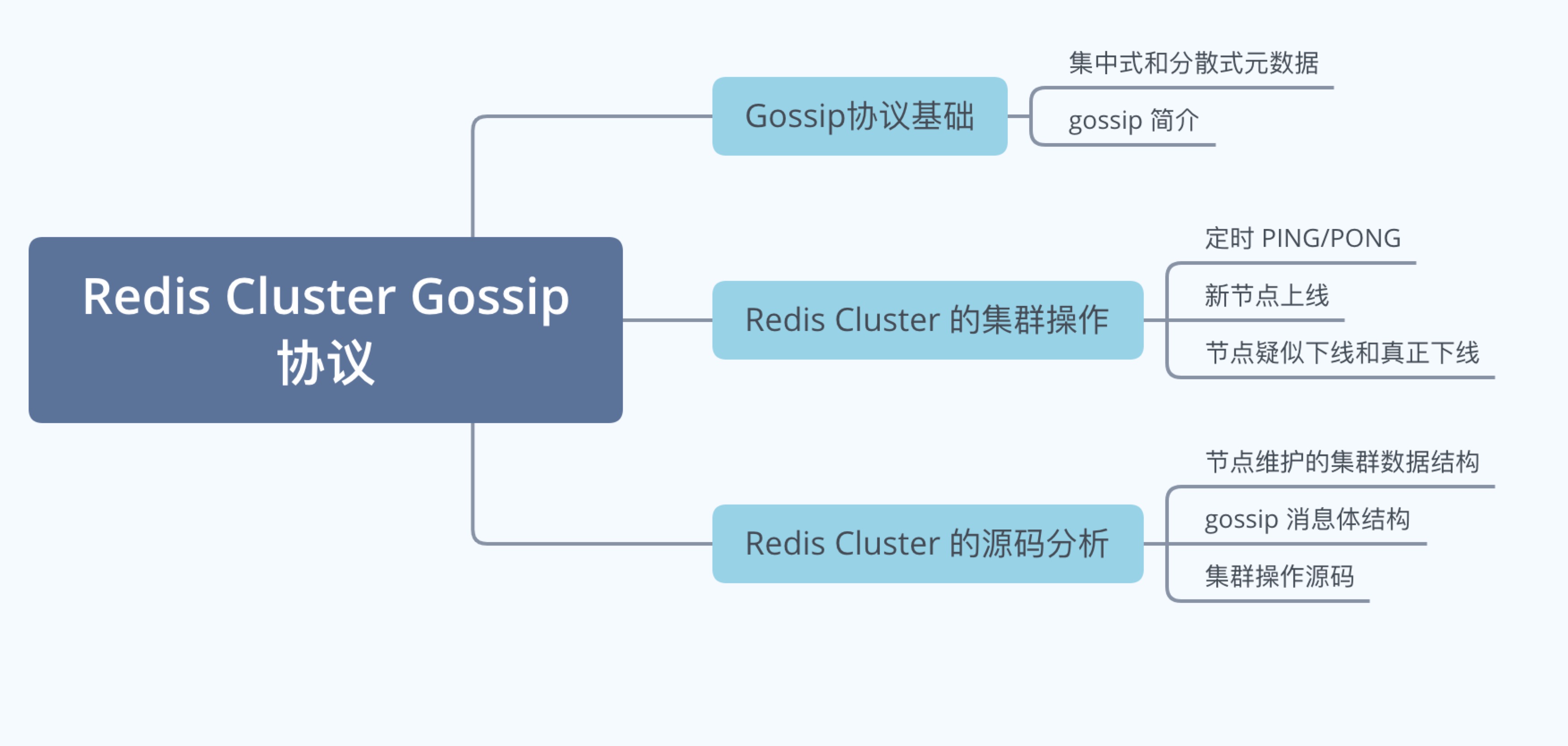
2020年11月
-
11.11 22:13:03发表了文章
2020-11-11 22:13:03
MySQL 的 join 功能弱爆了?
对于 join 操作的实现,大概有 Nested Loop Join (循环嵌套连接),Hash Join(散列连接) 和 Sort Merge Join(排序归并连接) 三种较为常见的算法,它们各有优缺点和适用条件,接下来我们会依次来介绍。
2020年10月
-
10.19 20:58:43发表了文章
2020-10-19 20:58:43
MySQL死锁系列-线上死锁问题排查思路
本篇文章会讲解一下如果线上发生了死锁异常,如何去排查和处理。除了系列前文讲解的有关加锁和锁冲突的原理还,还需要对 MySQl 死锁日志和 binlog 日志进行分析。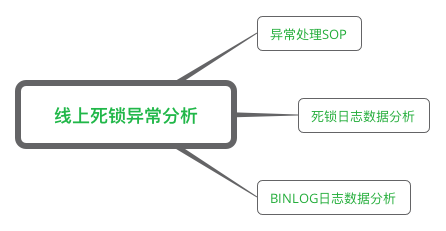
2020年08月
-
08.31 22:45:55发表了文章
2020-08-31 22:45:55
MySQL复杂where条件分析
的加锁原理并具体分析了大部分的简单 SQL 语句,但是实际业务场景中 SQL 语句往往及其复杂,包含多个条件,此时就需要具体分析SQL 使用到的索引,并了解 where 条件的判断逻辑。 我们可以直接使用 explain 或者 optimizer_trace 来分析 SQL 语句执行使用了哪些索引,具体使用可以看本系列文章的前两篇文章。但是,今天我们讲一下具体 Where 语句的条件的拆分和使用,即复杂 Where 条件是如何生效的。
-
08.11 12:20:39
 回答了问题
2020-08-11 12:20:39
回答了问题
2020-08-11 12:20:39
-
08.07 15:53:06回答了问题
2020-08-07 15:53:06
请问以下canal能不能监控到MySQL视图的变化
赞1 踩0 评论0 -
08.05 12:19:10回答了问题
2020-08-05 12:19:10
数据库的乐观锁和悲观锁是什么?怎么实现的?
赞1 踩0 评论0 -
08.04 12:33:58回答了问题
2020-08-04 12:33:58
-
08.03 22:19:51发表了文章
2020-08-03 22:19:51
100% 展示 MySQL 语句执行的神器-Optimizer Trace
有时SQL明明使用了索引列,但是执行时却未使用索引,Optimizer Trace 可以分析此类情况,帮助我们了解 SQL执行背后的原理.
2019年11月
-
11.12 20:52:33发表了文章
2019-11-12 20:52:33
当 Redis 发生高延迟时,到底发生了什么
Redis 是一种内存数据库,将数据保存在内存中,读写效率要比传统的将数据保存在磁盘上的数据库要快很多。但是 Redis 也会发生延迟时,这是就需要我们对其产生原因有深刻的了解,以便于快速排查问题,解决 Redis的延迟问题 -
11.02 22:13:22发表了文章
2019-11-02 22:13:22
公理设计-由奇怪海战引发的软件设计思考
公理设计理论将设计建立在科学公理、定理和推论的基础上,由麻省理工学院教授 Nam. P. Suh 领导的研究小组于 1978 年提出,适用于各种类别的设计活动。软件设计当然也属于一类工程设计过程,下面我们就来看一下两者的关联。
2019年10月
-
10.28 22:25:25发表了文章
2019-10-28 22:25:25
详解 Redis 内存管理机制和实现
Redis是一个基于内存的键值数据库,其内存管理是非常重要的。本文内存管理的内容包括:过期键的懒性删除和过期删除以及内存溢出控制策略。
2019年09月
-
09.18 22:11:26发表了文章
2019-09-18 22:11:26
编程小技巧之 Linux 文本处理命令
合格的程序员都善于使用工具,正所谓君子性非异也,善假于物也。合理的利用 Linux 的命令行工具,可以提高我们的工作效率。
2019年07月
-
07.30 22:24:42发表了文章
2019-07-30 22:24:42
Redis AOF 持久化详解
Redis 是一种内存数据库,将数据保存在内存中,读写效率要比传统的将数据保存在磁盘上的数据库要快很多。但是一旦进程退出,Redis 的数据就会丢失。 AOF( append only file )持久化以独立日志的方式记录每次写命令,并在 Redis 重启时在重新执行 AOF 文件中的命令以达到恢复数据的目的。 -
07.06 19:12:09发表了文章
2019-07-06 19:12:09
Redis RDB 持久化详解
Redis 是一种内存数据库,将数据保存在内存中,读写效率要比传统的将数据保存在磁盘上的数据库要快很多。但是一旦进程退出,Redis 的数据就会丢失。 为了解决这个问题,Redis 提供了 RDB 和 AOF 两种持久化方案,将内存中的数据保存到磁盘中,避免数据丢失。
2019年06月
-
06.17 21:38:23发表了文章
2019-06-17 21:38:23
用户日活月活怎么统计 - Redis HyperLogLog 详解
Redis 的 HyperLogLog 只需要消耗12KB内存,在标准误差0.81%的前提下,能通统计2^64个数。今天我们就一起来深入了解一下 HyperLogLog 的使用,基础原理和源码实现。
-
发表了文章
2021-04-19
ElasticSearch 如何使用 TDigest 算法计算亿级数据的百分位数?
-
发表了文章
2021-04-12
ElasticSearch 如何使用 ik 进行中文分词?
-
发表了文章
2021-03-08
线上MySQL读写分离,出现写完读不到问题如何解决
-
发表了文章
2021-02-20
为什么ElasticSearch比MySQL更适合全文索引
-
发表了文章
2020-12-03
一万字详解 Redis Cluster Gossip 协议
-
发表了文章
2020-11-11
MySQL 的 join 功能弱爆了?
-
发表了文章
2020-10-19
MySQL死锁系列-线上死锁问题排查思路
-
发表了文章
2020-08-31
MySQL复杂where条件分析
-
发表了文章
2020-08-03
100% 展示 MySQL 语句执行的神器-Optimizer Trace
-
发表了文章
2020-06-15
用 Explain 命令分析 MySQL 的 SQL 执行
-
发表了文章
2020-05-28
MySQL死锁系列-常见加锁场景分析
-
发表了文章
2020-05-11
带你100% 地了解 Redis 6.0 的客户端缓存
-
发表了文章
2020-04-14
Java 数据持久化系列之 HikariCP (一)
-
发表了文章
2020-04-01
MySQL的死锁系列- 锁的类型以及加锁原理
-
发表了文章
2020-02-03
Java 数据持久化系列之池化技术
-
发表了文章
2019-12-14
Redis 命令执行过程(下)
-
发表了文章
2019-12-11
Redis 命令执行过程(上)
-
发表了文章
2019-11-12
当 Redis 发生高延迟时,到底发生了什么
-
发表了文章
2019-11-02
公理设计-由奇怪海战引发的软件设计思考
-
发表了文章
2019-10-28
详解 Redis 内存管理机制和实现
滑动查看更多
-
回答了问题
2020-08-11
mysql innodb的辅助索引如何存储重复的列值?在查询上有什么不一样吗?#云原生后端
InnoDB 辅助索引的结构如下所示,可以很清晰的看出,通过辅助索引只能查出对应的主键索引值,需要再根据主键索引去查询出相应的数据行。赞1 踩0 评论0 -
回答了问题
2020-08-07
请问以下canal能不能监控到MySQL视图的变化
canal是基于MySQL binlog 进行增量订阅和消费的组件,而MySQL视图基于基于具体的表,自身没有binlog,所以canal无法直接监控MySQL视图。但是它可以监控视图背后的表,这样应该也能达成想要的效果。赞1 踩0 评论0 -
回答了问题
2020-08-05
数据库的乐观锁和悲观锁是什么?怎么实现的?
一、乐观锁 乐观锁不是数据库自带的,需要我们自己去实现。乐观锁是指操作数据库时(更新操作),想法很乐观,认为这次的操作不会导致冲突,在操作数据时,并不进行任何其他的特殊处理(也就是不加锁),而在进行更新后,再去判断是否有冲突了。 通常实现是这样的:在表中的数据进行操作时(更新),先给数据表加一个版本(version)字段,每操作一次,将那条记录的版本号加1。也就是先查询出那条记录,获取出version字段,如果要对那条记录进行操作(更新),则先判断此刻version的值是否与刚刚查询出来时的version的值相等,如果相等,则说明这段期间,没有其他程序对其进行操作,则可以执行更新,将version字段的值加1;如果更新时发现此刻的version值与刚刚获取出来的version的值不相等,则说明这段期间已经有其他程序对其进行操作了,则不进行更新操作。比如下面的sql 语句就使用了乐观锁思想。 update t1 set status=2, version=version+1 where id=#{id} and version=#{version}; 悲观锁 悲观锁就是在操作数据时,认为此操作会出现数据冲突,所以在进行每次操作时都要通过获取锁才能进行对相同数据的操作,这点跟java中的synchronized很相似,所以悲观锁需要耗费较多的时间。另外与乐观锁相对应的,悲观锁是由数据库自己实现了的,要用的时候,我们直接调用数据库的相关语句就可以了。 具体的悲观锁实现,可以了解一下 InnoDB 的行锁之类的知识。赞1 踩0 评论0 -
回答了问题
2020-08-04
在k8s上部署,为什么还需要eureka呢,k8s的service就提供注册发现和负载均衡的#K8S
如果你已经使用了 Spring Cloud 全家桶,就需要使用注入 eureka或者consul等额外的服务注册和发现中心;如果还没有,则可以使用service,后续调研isitio。两者都是无侵入的 不需要改应用代码。赞2 踩0 评论0
滑动查看更多
暂无更多信息