我是咔咔

已加入开发者社区1793天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝




技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2022年05月
-
05.21 16:26:21
 发表了文章
2022-05-21 16:26:21
发表了文章
2022-05-21 16:26:21
面试问Redis集群,被虐的不行了......(2)
面试问Redis集群,被虐的不行了......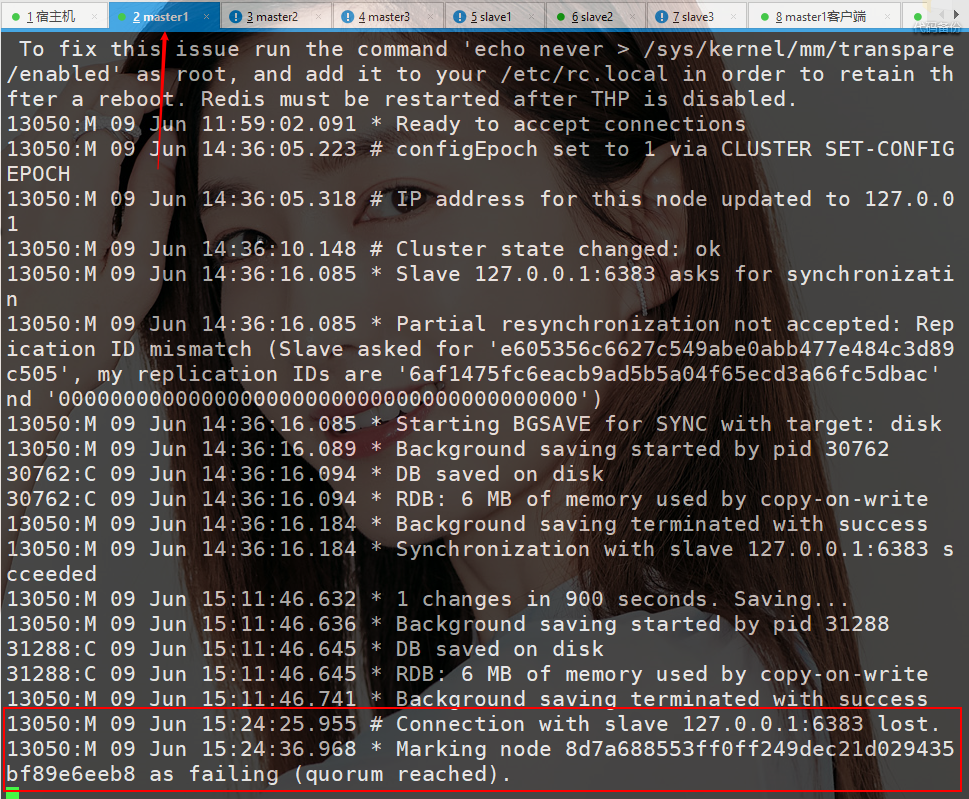
-
05.21 16:23:51发表了文章
2022-05-21 16:23:51
面试问Redis集群,被虐的不行了......(1)
面试问Redis集群,被虐的不行了......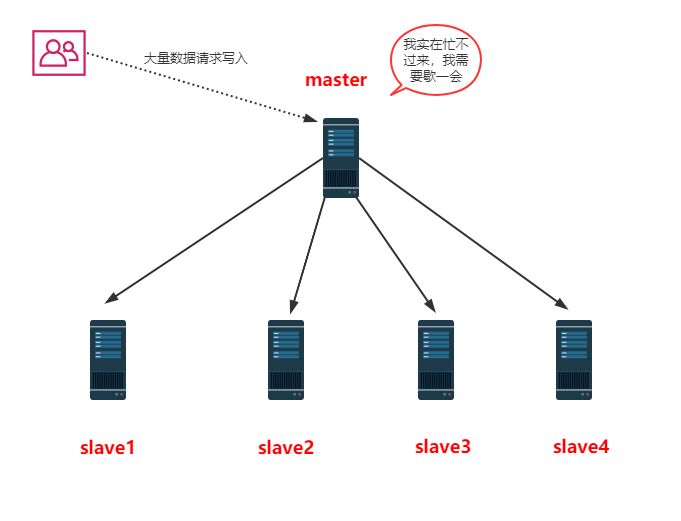
-
05.21 16:13:29发表了文章
2022-05-21 16:13:29
Redis主从复制原理以及常见问题(2)
Redis主从复制原理以及常见问题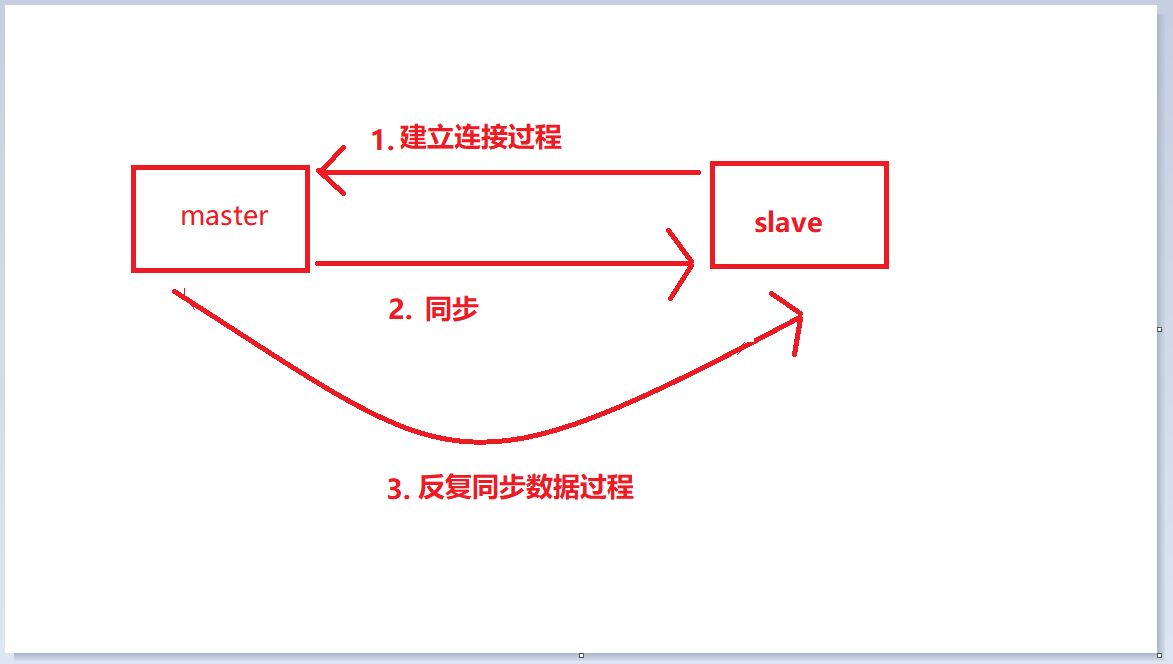
-
05.21 15:27:42发表了文章
2022-05-21 15:27:42
Redis主从复制原理以及常见问题(1)
Redis主从复制原理以及常见问题
-
05.21 15:23:05发表了文章
2022-05-21 15:23:05
为什么不建议给MySQL设置Null值?《死磕MySQL系列 十八》
为什么不建议给MySQL设置Null值?《死磕MySQL系列 十八》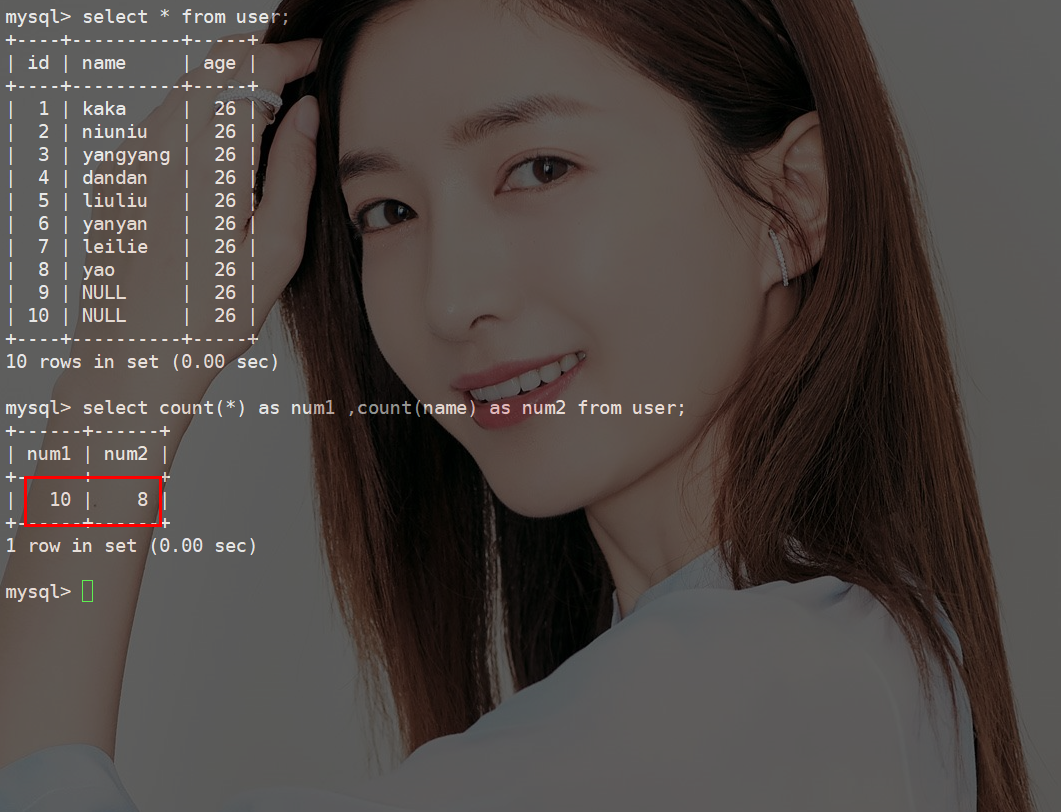
-
05.21 15:19:58发表了文章
2022-05-21 15:19:58
MySQL对JOIN做了那些不为人知的优化《死磕MySQL系列 十七》(2)
MySQL对JOIN做了那些不为人知的优化《死磕MySQL系列 十七》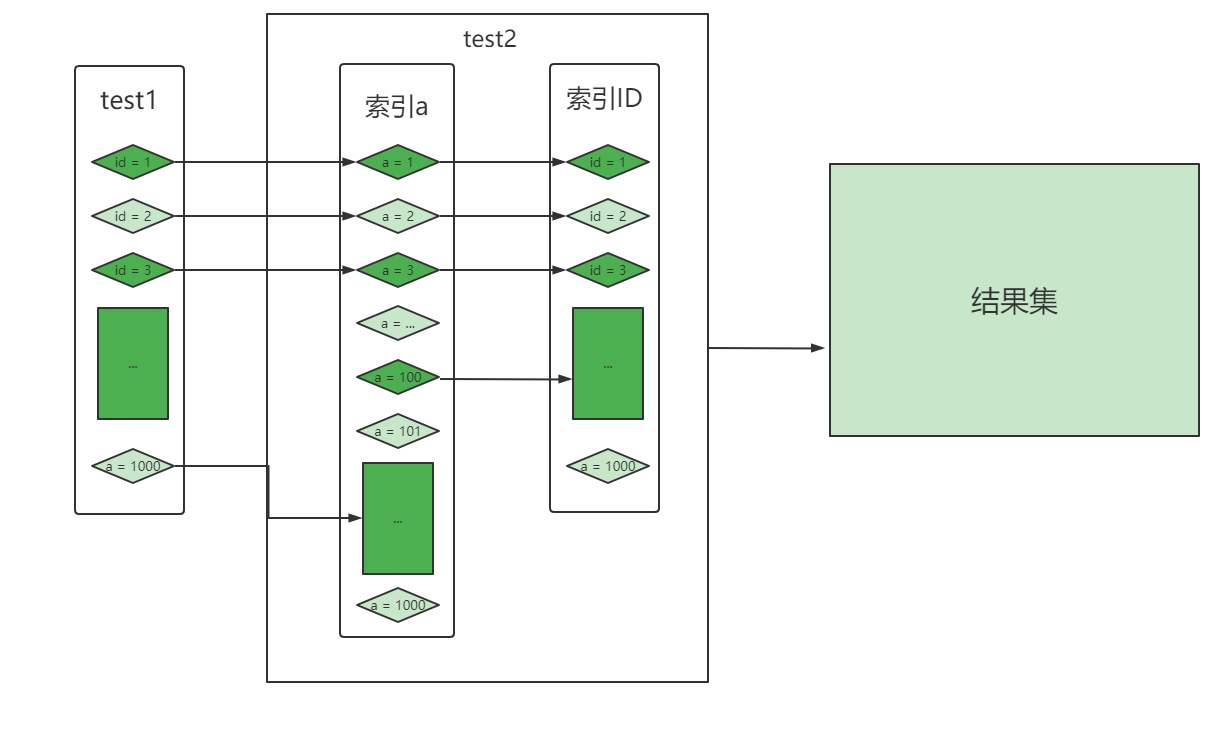
-
05.21 15:18:38发表了文章
2022-05-21 15:18:38
MySQL对JOIN做了那些不为人知的优化《死磕MySQL系列 十七》
MySQL对JOIN做了那些不为人知的优化《死磕MySQL系列 十七》
-
05.21 15:14:50发表了文章
2022-05-21 15:14:50
速看,ElasticSearch如何处理空值《玩转ElasticSearch 4》-2
速看,ElasticSearch如何处理空值《玩转ElasticSearch 4》 -
05.21 15:12:56发表了文章
2022-05-21 15:12:56
速看,ElasticSearch如何处理空值《玩转ElasticSearch 4》-1
速看,ElasticSearch如何处理空值《玩转ElasticSearch 3》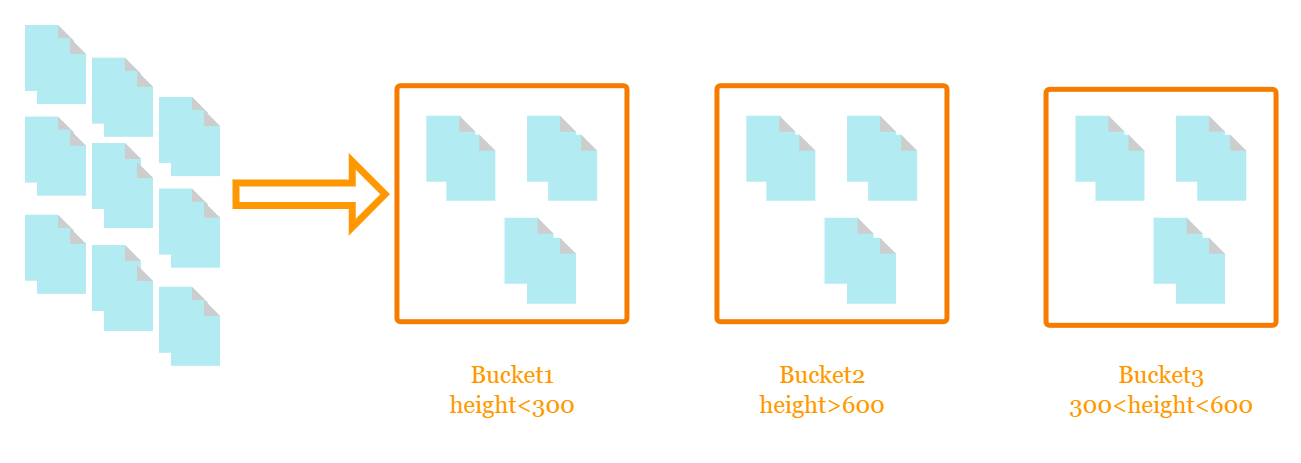
-
05.21 15:01:55发表了文章
2022-05-21 15:01:55
速看,ElasticSearch如何处理空值《玩转ElasticSearch 3》-3
速看,ElasticSearch如何处理空值《玩转ElasticSearch 3》 -
05.21 00:06:58发表了文章
2022-05-21 00:06:58
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》-3
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》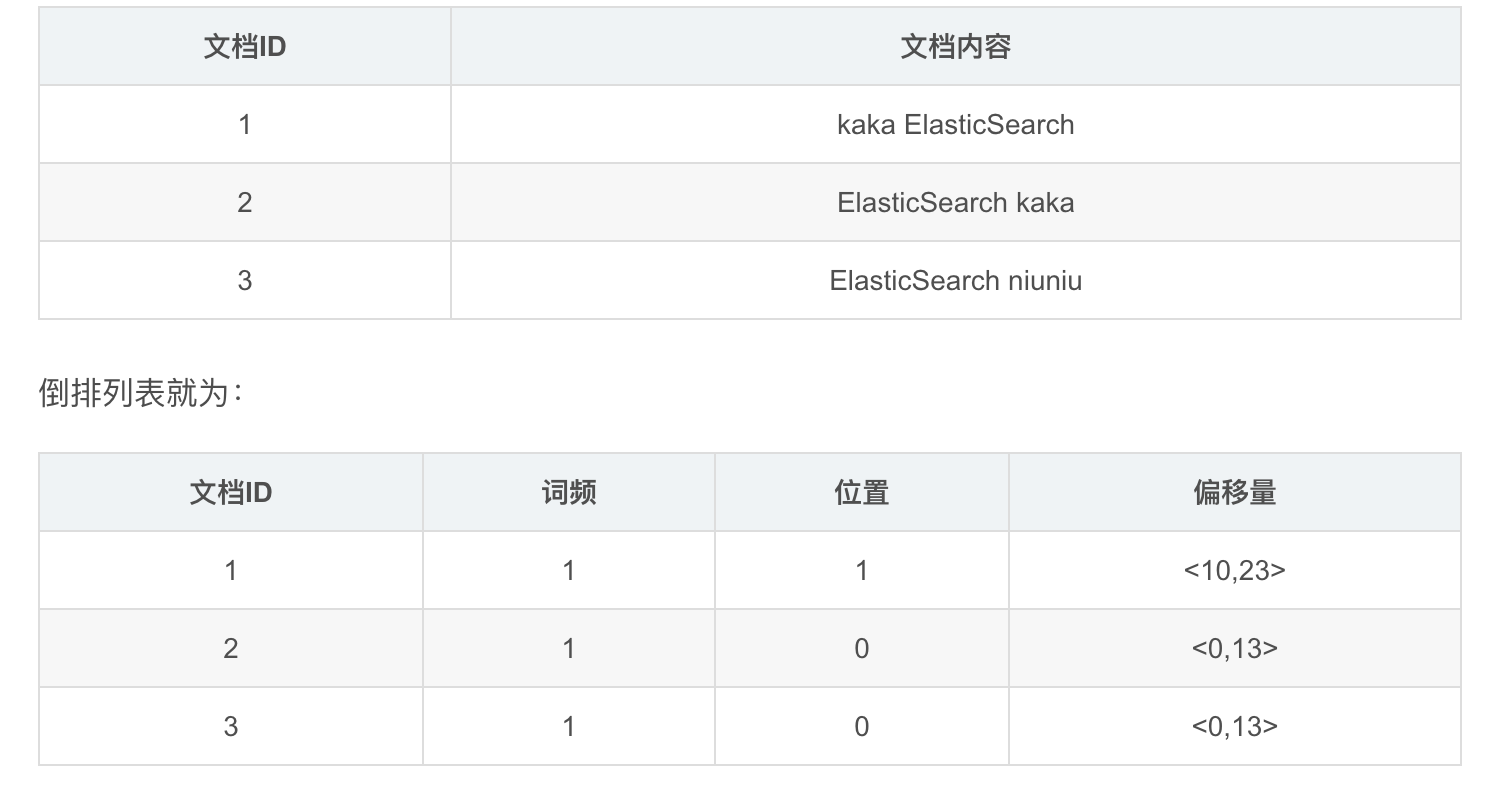
-
05.21 00:03:13发表了文章
2022-05-21 00:03:13
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》-2
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》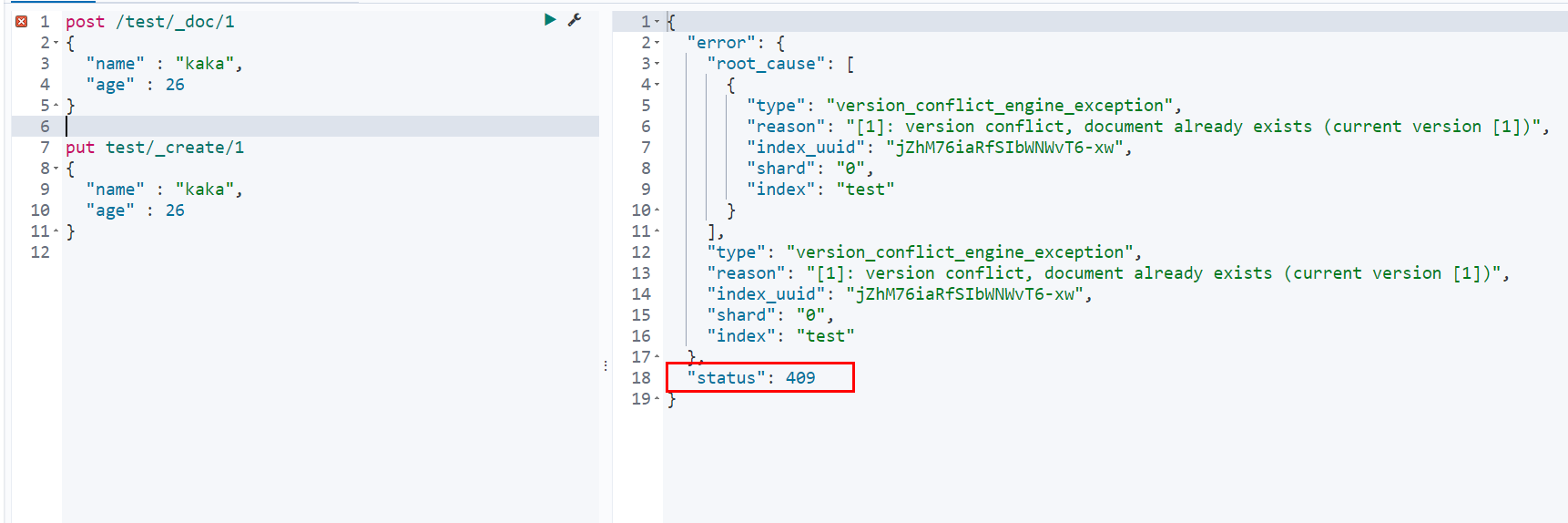
-
05.21 00:00:43发表了文章
2022-05-21 00:00:43
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》-1
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》
-
05.20 23:56:17发表了文章
2022-05-20 23:56:17
Redis哨兵原理,我忍你很久了!(4)
Redis哨兵原理,我忍你很久了!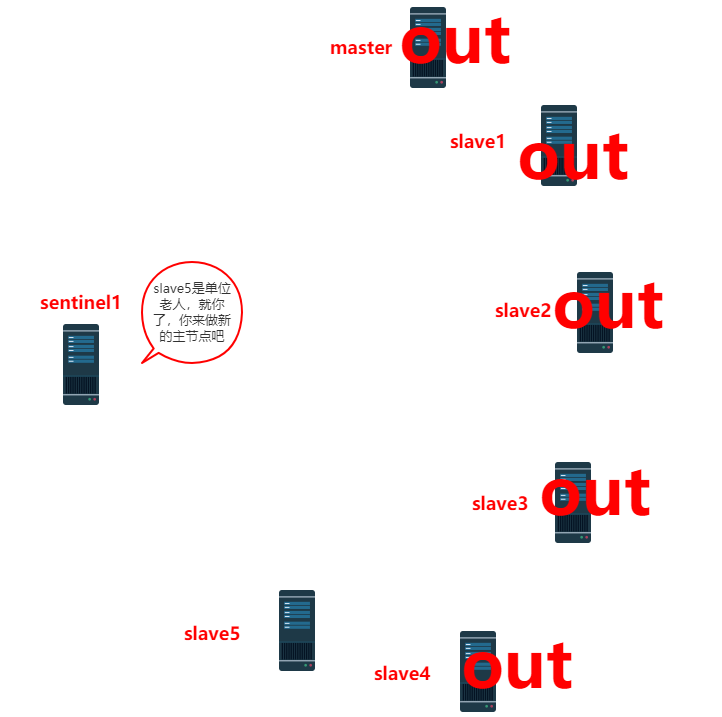
-
05.20 23:54:20发表了文章
2022-05-20 23:54:20
Redis哨兵原理,我忍你很久了!(3)
Redis哨兵原理,我忍你很久了!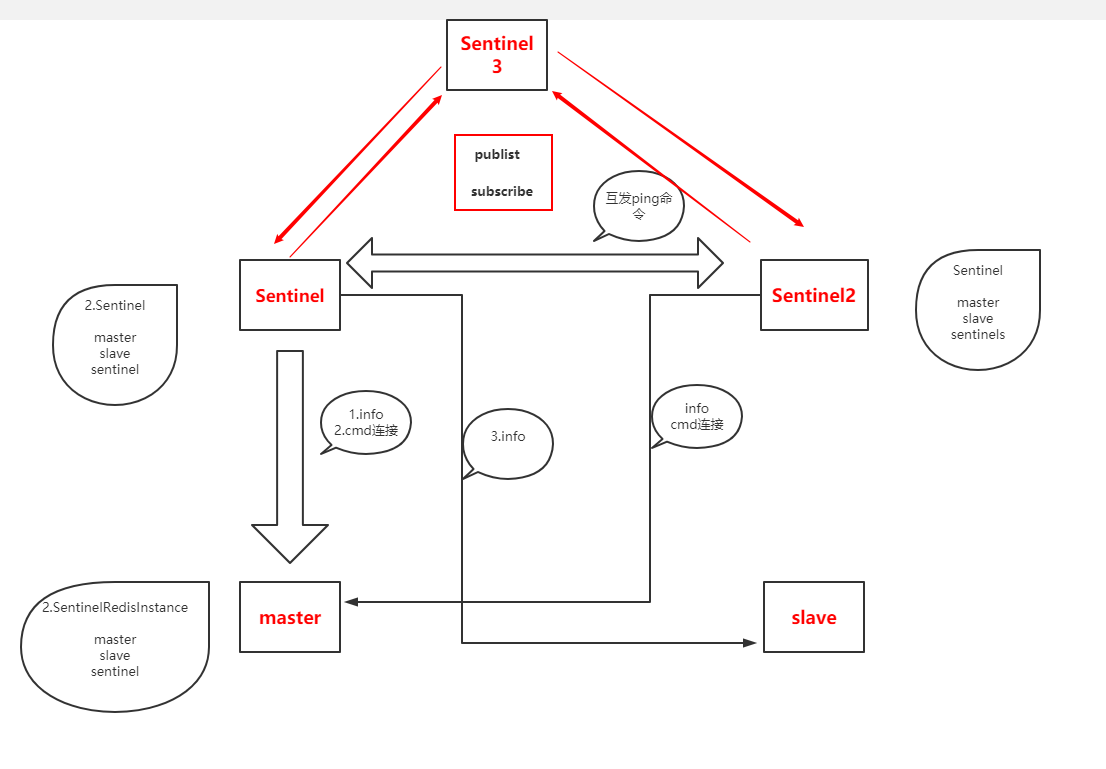
-
05.20 23:52:06发表了文章
2022-05-20 23:52:06
Redis哨兵原理,我忍你很久了!(2)
Redis哨兵原理,我忍你很久了!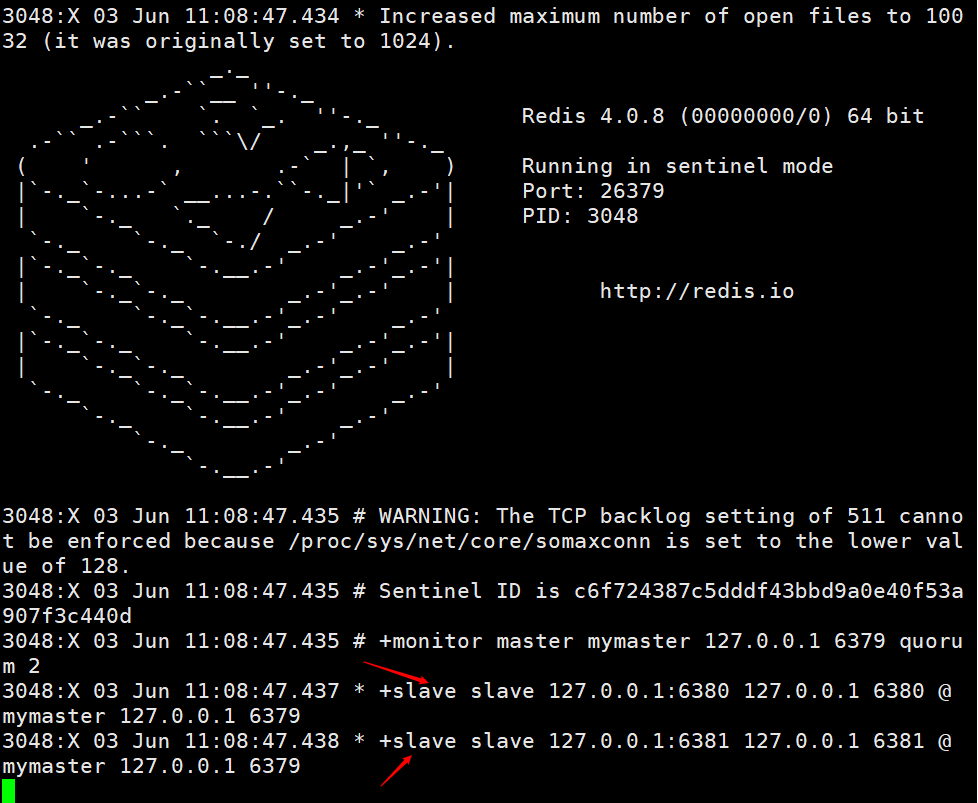
-
05.20 23:50:20发表了文章
2022-05-20 23:50:20
Redis哨兵原理,我忍你很久了!(1)
Redis哨兵原理,我忍你很久了!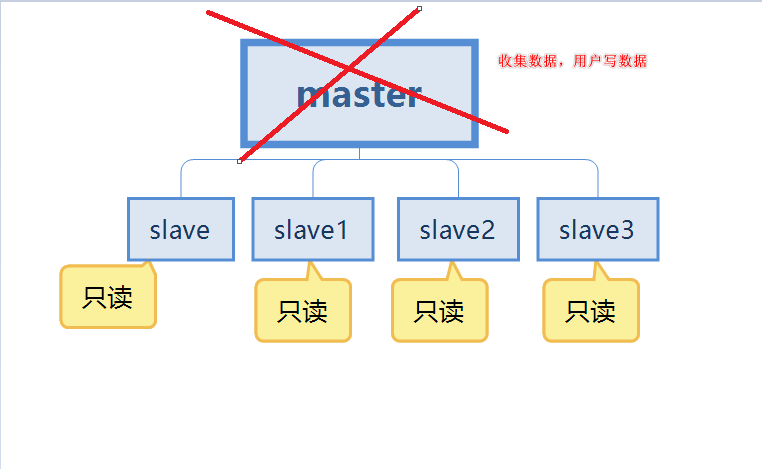
-
05.20 23:41:55发表了文章
2022-05-20 23:41:55
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》-3
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》
-
05.20 23:39:52发表了文章
2022-05-20 23:39:52
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》-2
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》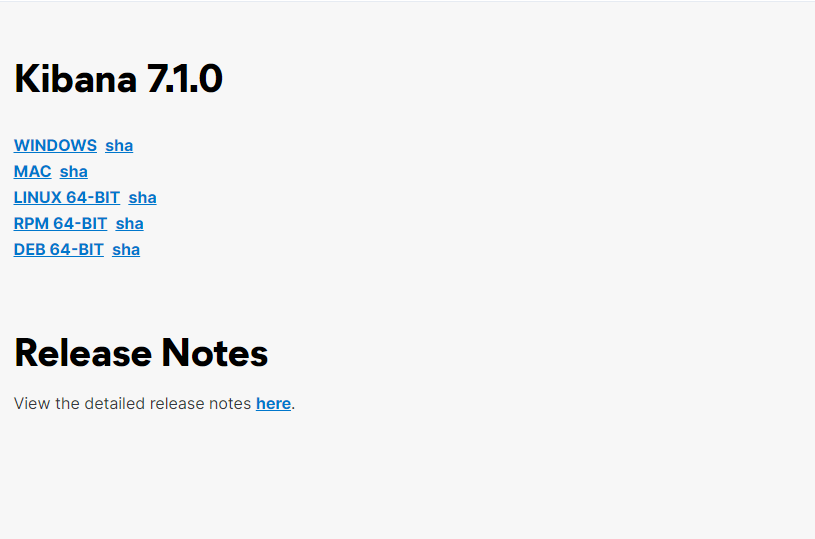
-
05.20 23:37:55发表了文章
2022-05-20 23:37:55
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》-1
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》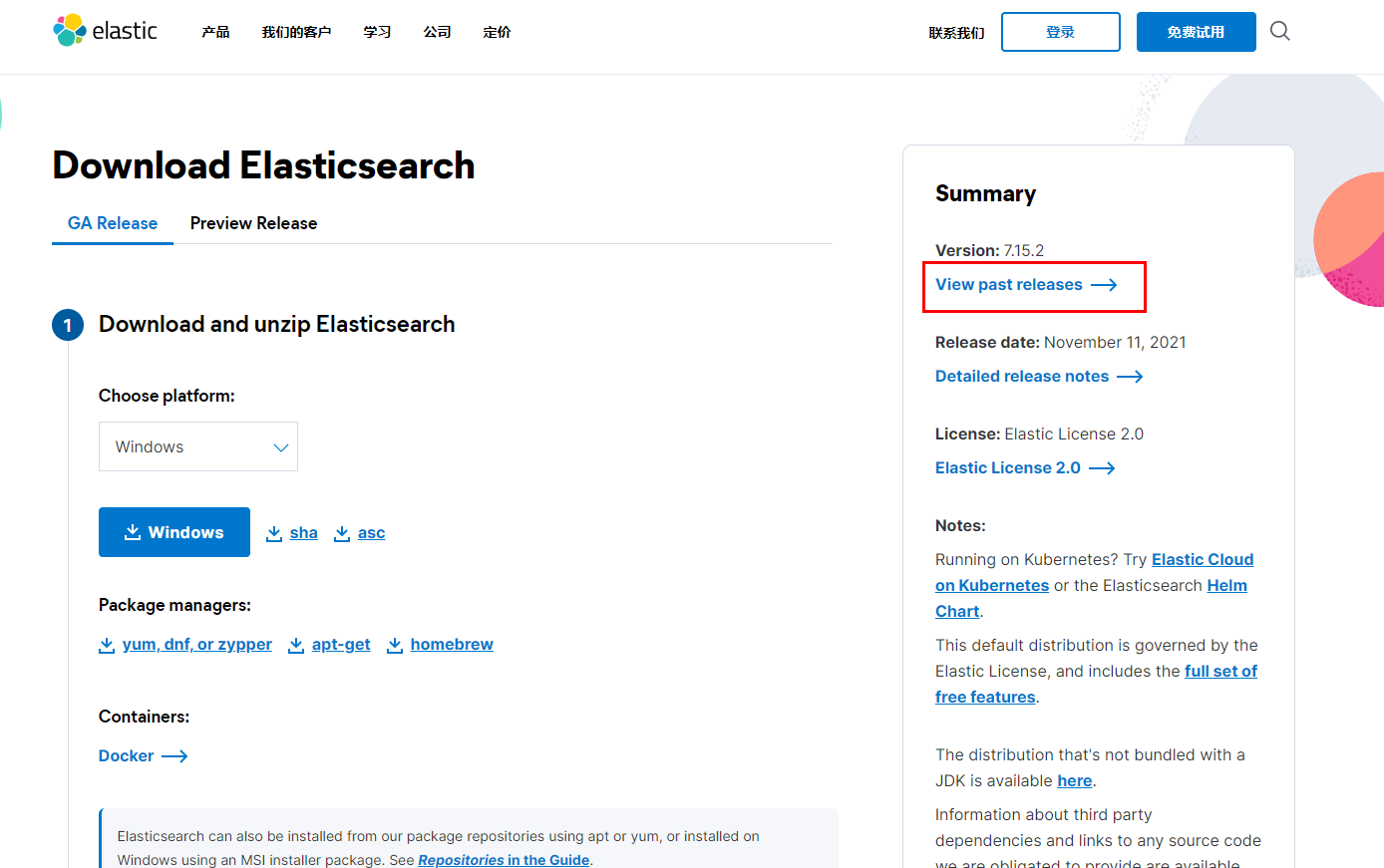
-
05.20 23:33:29发表了文章
2022-05-20 23:33:29
为什么不让用join?《死磕MySQL系列 十六》
为什么不让用join?《死磕MySQL系列 十六》
-
05.20 23:31:23发表了文章
2022-05-20 23:31:23
如何让脚本在任意地方可执行
如何让脚本在任意地方可执行
-
05.20 23:28:06发表了文章
2022-05-20 23:28:06
聊聊MySQL的加锁规则《死磕MySQL系列 十五》
聊聊MySQL的加锁规则《死磕MySQL系列 十五》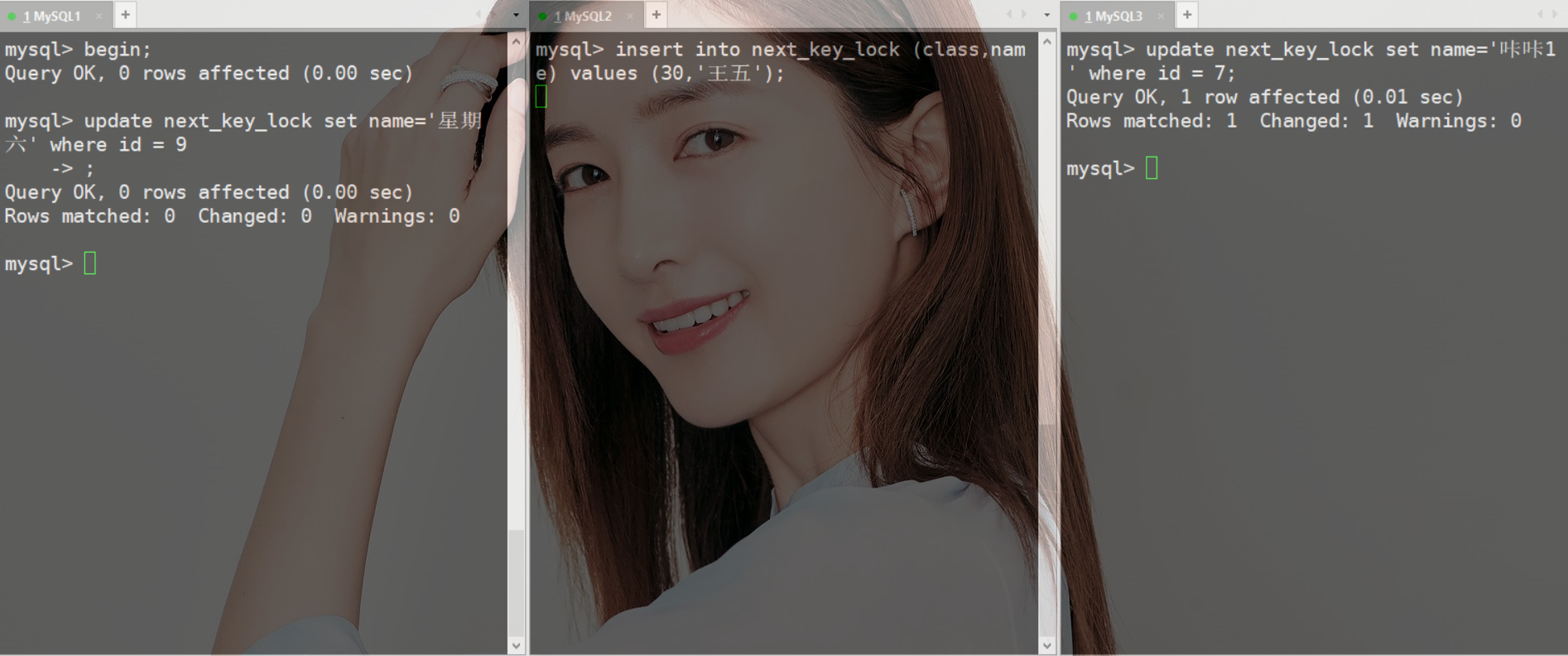
-
05.20 23:25:33发表了文章
2022-05-20 23:25:33
免费增加几个T电脑空间方法,拿去不谢
免费增加几个T电脑空间方法,拿去不谢
-
05.20 23:24:27发表了文章
2022-05-20 23:24:27
闯祸了,生产环境执行了DDL操作《死磕MySQL系列 十四》(2)
闯祸了,生产环境执行了DDL操作《死磕MySQL系列 十四》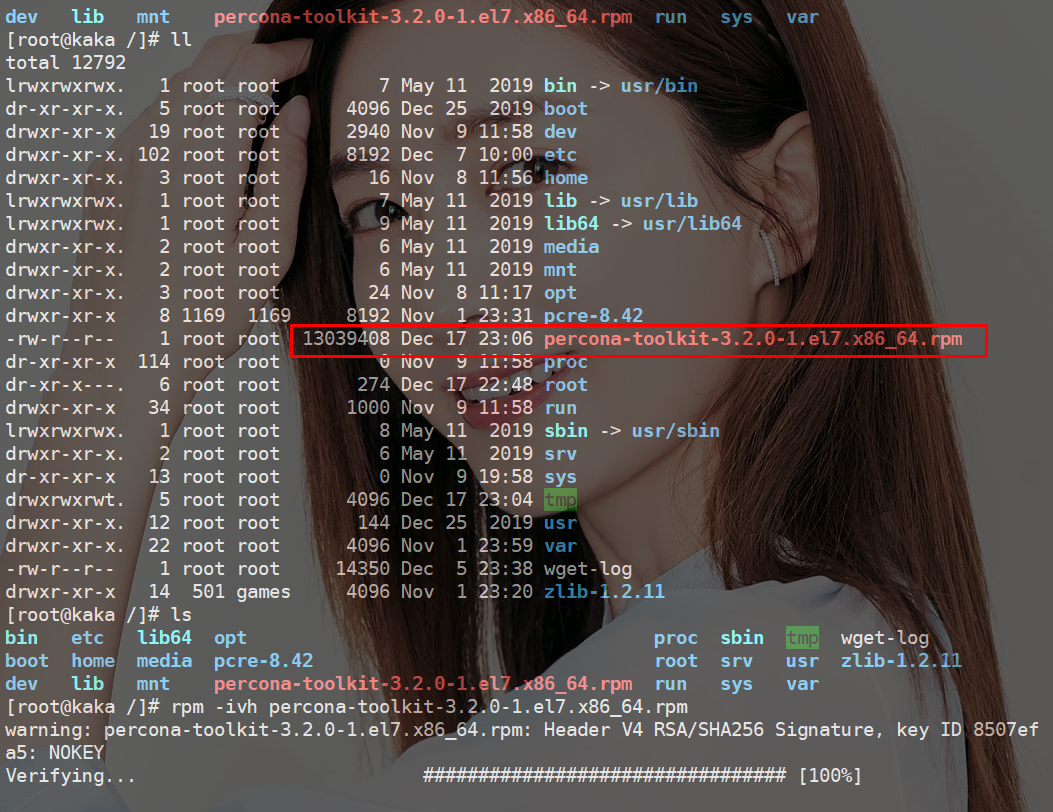
-
05.20 23:22:56发表了文章
2022-05-20 23:22:56
闯祸了,生产环境执行了DDL操作《死磕MySQL系列 十四》(1)
闯祸了,生产环境执行了DDL操作《死磕MySQL系列 十四》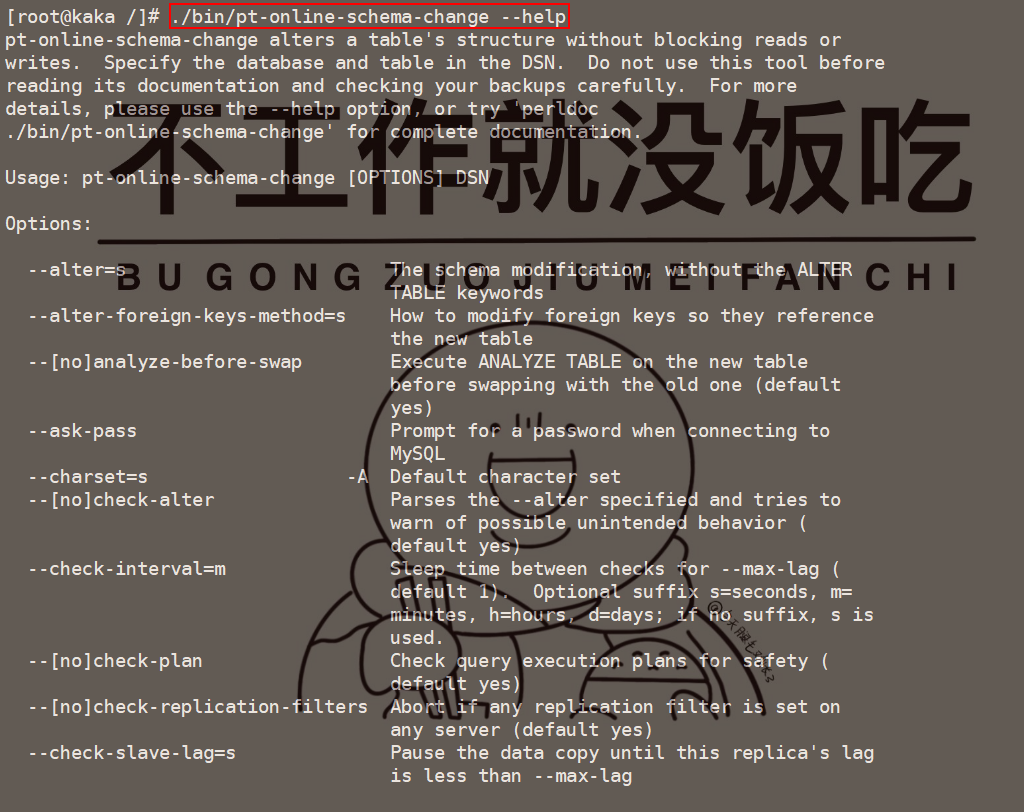
-
05.20 23:20:26发表了文章
2022-05-20 23:20:26
重重封锁,让你一条数据都拿不到《死磕MySQL系列 十三》
重重封锁,让你一条数据都拿不到《死磕MySQL系列 十三》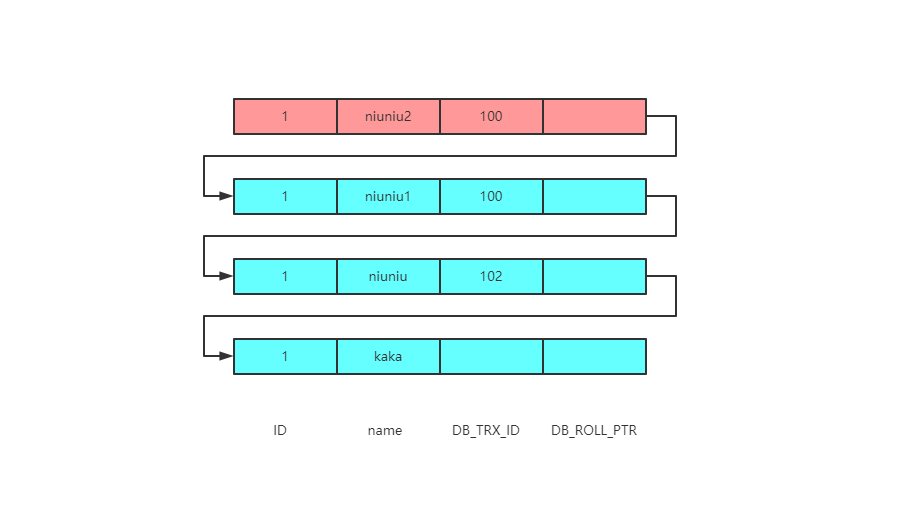
-
05.20 23:19:18发表了文章
2022-05-20 23:19:18
打开order by的大门,一探究竟《死磕MySQL系列 十二》(2)
打开order by的大门,一探究竟《死磕MySQL系列 十二》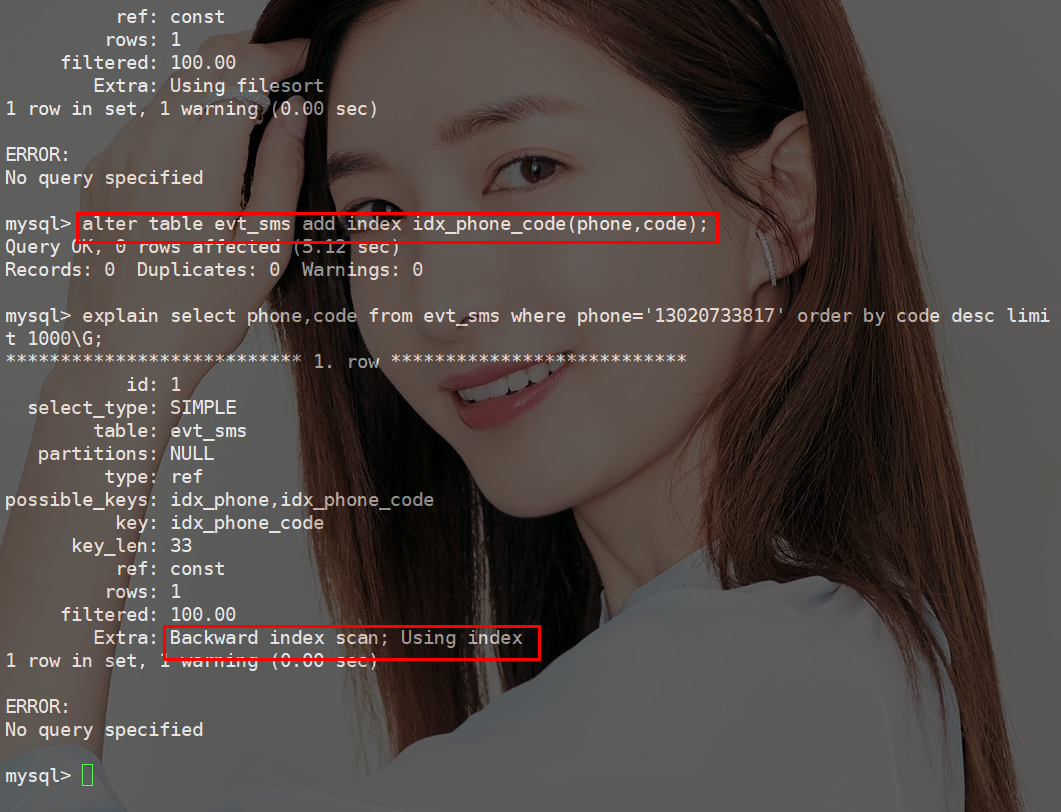
-
05.20 23:18:44发表了文章
2022-05-20 23:18:44
打开order by的大门,一探究竟《死磕MySQL系列 十二》(1)
打开order by的大门,一探究竟《死磕MySQL系列 十二》
-
05.20 23:15:00发表了文章
2022-05-20 23:15:00
为什么MySQL字符串不加引号索引失效?《死磕MySQL系列 十一》
为什么MySQL字符串不加引号索引失效?《死磕MySQL系列 十一》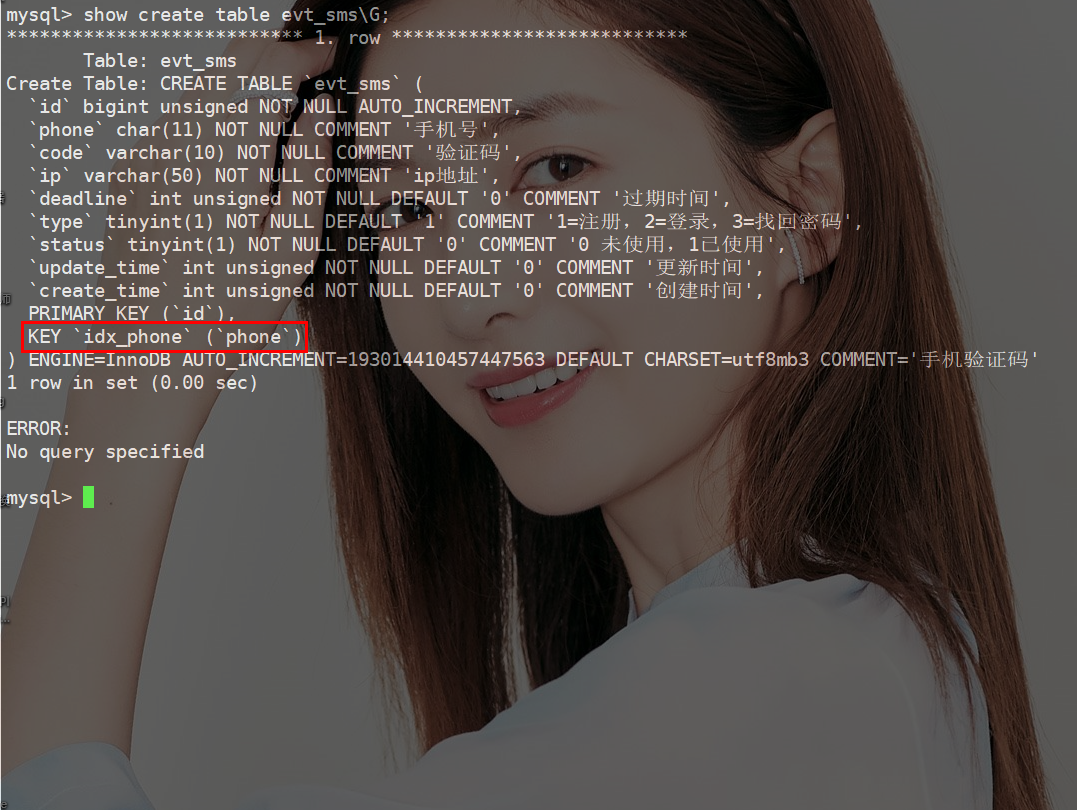
-
05.20 23:13:36发表了文章
2022-05-20 23:13:36
MySQL统计总数就用count,别花里胡哨的《死磕MySQL系列 十》
MySQL统计总数就用count,别花里胡哨的《死磕MySQL系列 十》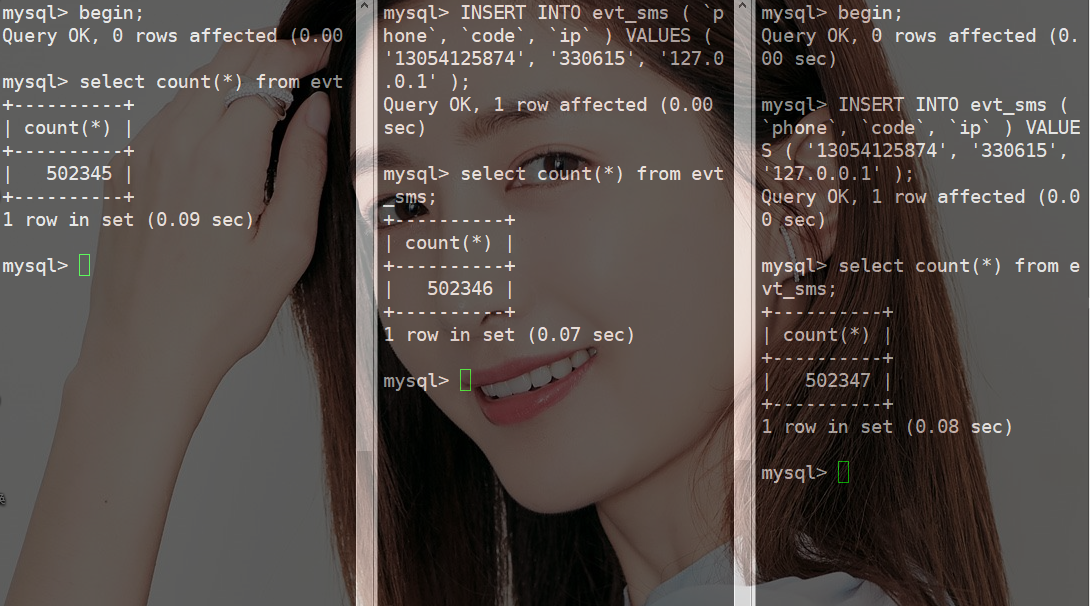
-
05.20 23:12:07发表了文章
2022-05-20 23:12:07
什么?还在用delete删除数据《死磕MySQL系列 九》(2)
什么?还在用delete删除数据《死磕MySQL系列 九》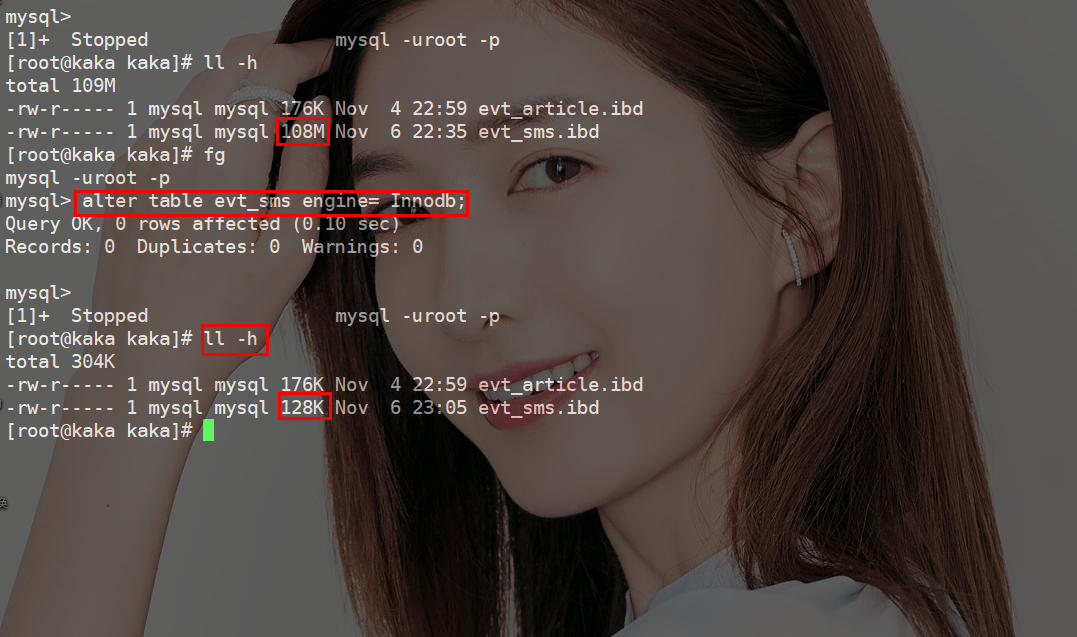
-
05.20 23:11:18发表了文章
2022-05-20 23:11:18
什么?还在用delete删除数据《死磕MySQL系列 九》(1)
什么?还在用delete删除数据《死磕MySQL系列 九》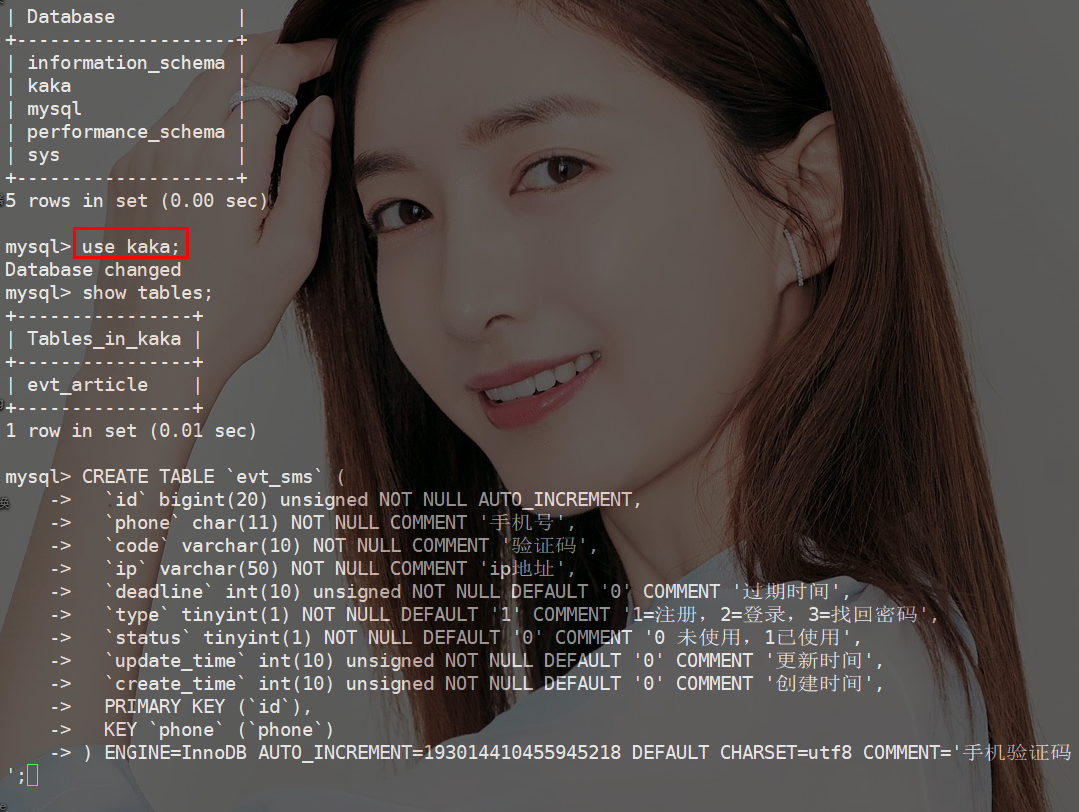
-
05.20 23:09:14发表了文章
2022-05-20 23:09:14
无法复现的“慢”SQL《死磕MySQL系列 八》
无法复现的“慢”SQL《死磕MySQL系列 八》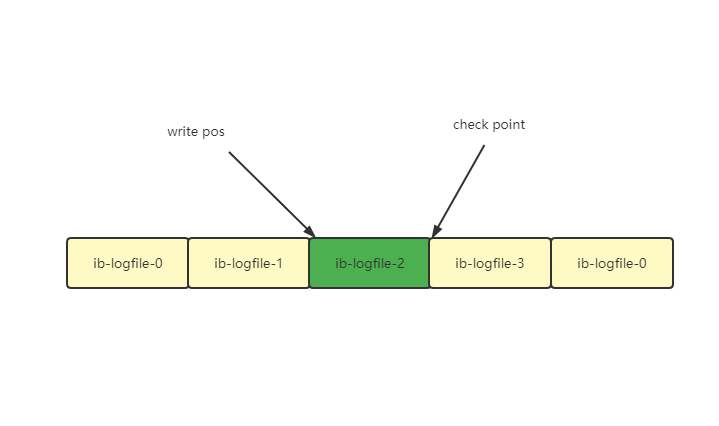
-
05.20 23:07:04发表了文章
2022-05-20 23:07:04
字符串可以这样加索引,你知吗?《死磕MySQL系列 七》
字符串可以这样加索引,你知吗?《死磕MySQL系列 七》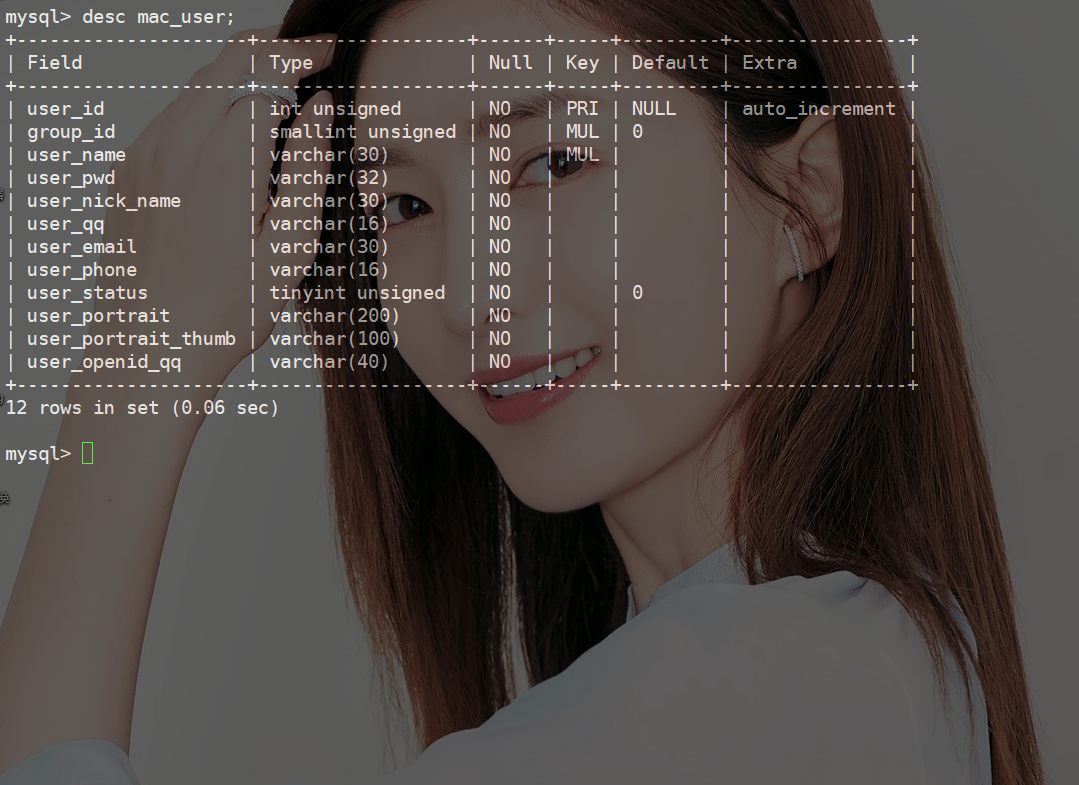
-
05.20 23:05:41发表了文章
2022-05-20 23:05:41
五分钟,让你明白MySQL是怎么选择索引《死磕MySQL系列 六》
五分钟,让你明白MySQL是怎么选择索引《死磕MySQL系列 六》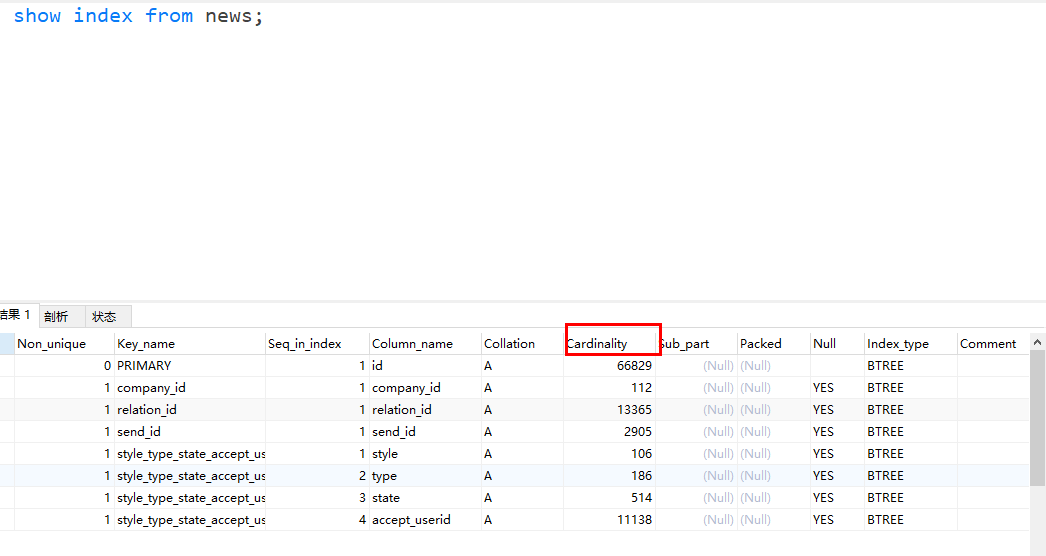
-
05.20 16:44:13发表了文章
2022-05-20 16:44:13
如何选择普通索引和唯一索引《死磕MySQL系列 五》
如何选择普通索引和唯一索引《死磕MySQL系列 五》
-
05.20 16:35:42发表了文章
2022-05-20 16:35:42
S 锁与 X 锁的爱恨情仇《死磕MySQL系列 四》
S 锁与 X 锁的爱恨情仇《死磕MySQL系列 四》
-
05.20 16:32:44发表了文章
2022-05-20 16:32:44
MySQL强人“锁”难《死磕MySQL系列 三》
MySQL强人“锁”难《死磕MySQL系列 三》
-
05.20 16:31:14发表了文章
2022-05-20 16:31:14
Phalcon多模块如何实现连接不同数据库 《Phalcon入坑指南系列 五》(2)
Phalcon多模块如何实现连接不同数据库 《Phalcon入坑指南系列 五》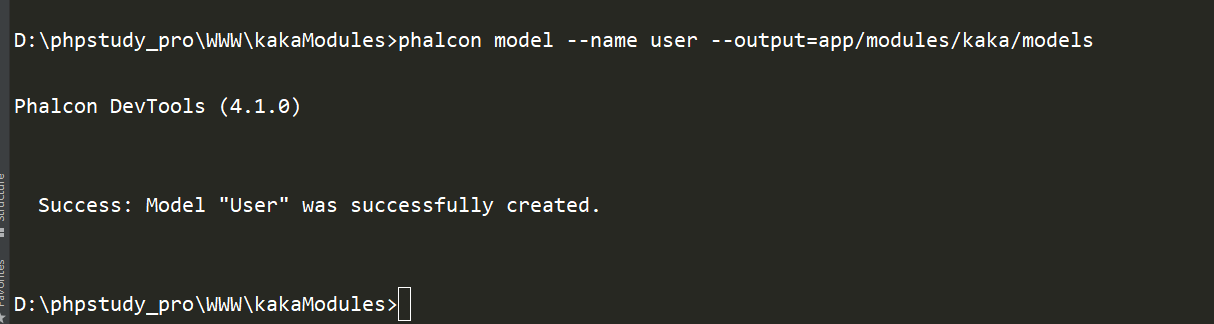
-
05.20 16:30:33发表了文章
2022-05-20 16:30:33
Phalcon多模块如何实现连接不同数据库 《Phalcon入坑指南系列 五》(1)
Phalcon多模块如何实现连接不同数据库 《Phalcon入坑指南系列 五》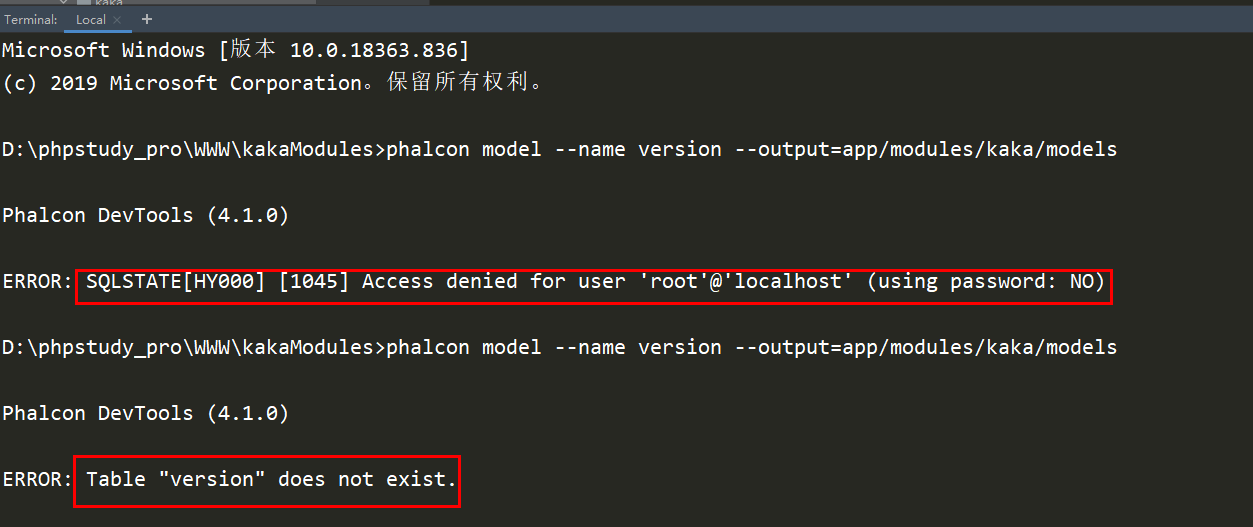
-
05.20 16:28:04发表了文章
2022-05-20 16:28:04
Phalcon如何创建多模块并能进行访问 《Phalcon入坑指南系列 四》(2)
Phalcon如何创建多模块并能进行访问 《Phalcon入坑指南系列 四》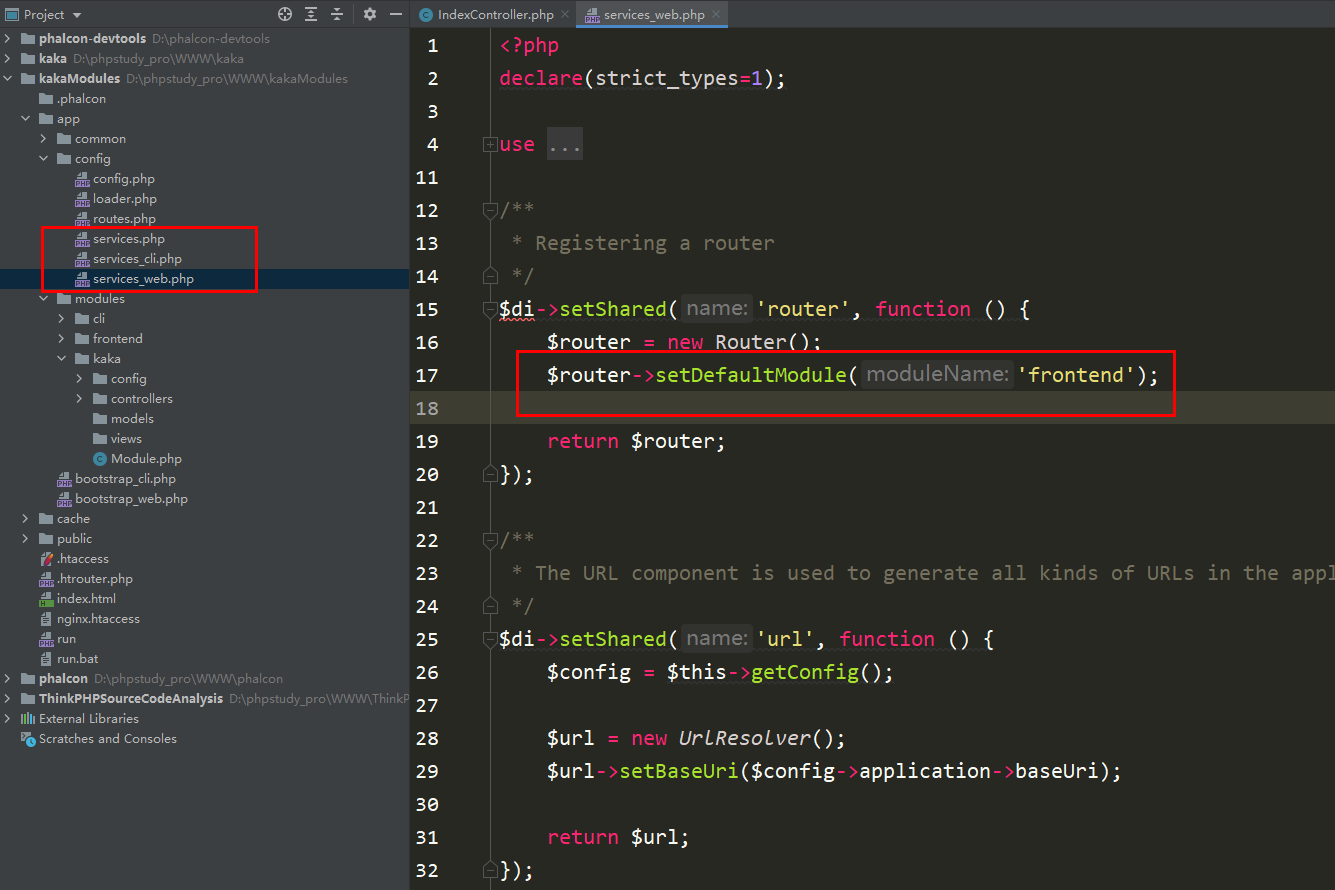
-
05.20 16:27:18发表了文章
2022-05-20 16:27:18
Phalcon如何创建多模块并能进行访问 《Phalcon入坑指南系列 四》(1)
Phalcon如何创建多模块并能进行访问 《Phalcon入坑指南系列 四》
-
05.20 15:34:58发表了文章
2022-05-20 15:34:58
Phalcon如何切换数据库《Phalcon入坑指南系列 三》(2)
Phalcon如何切换数据库《Phalcon入坑指南系列 三》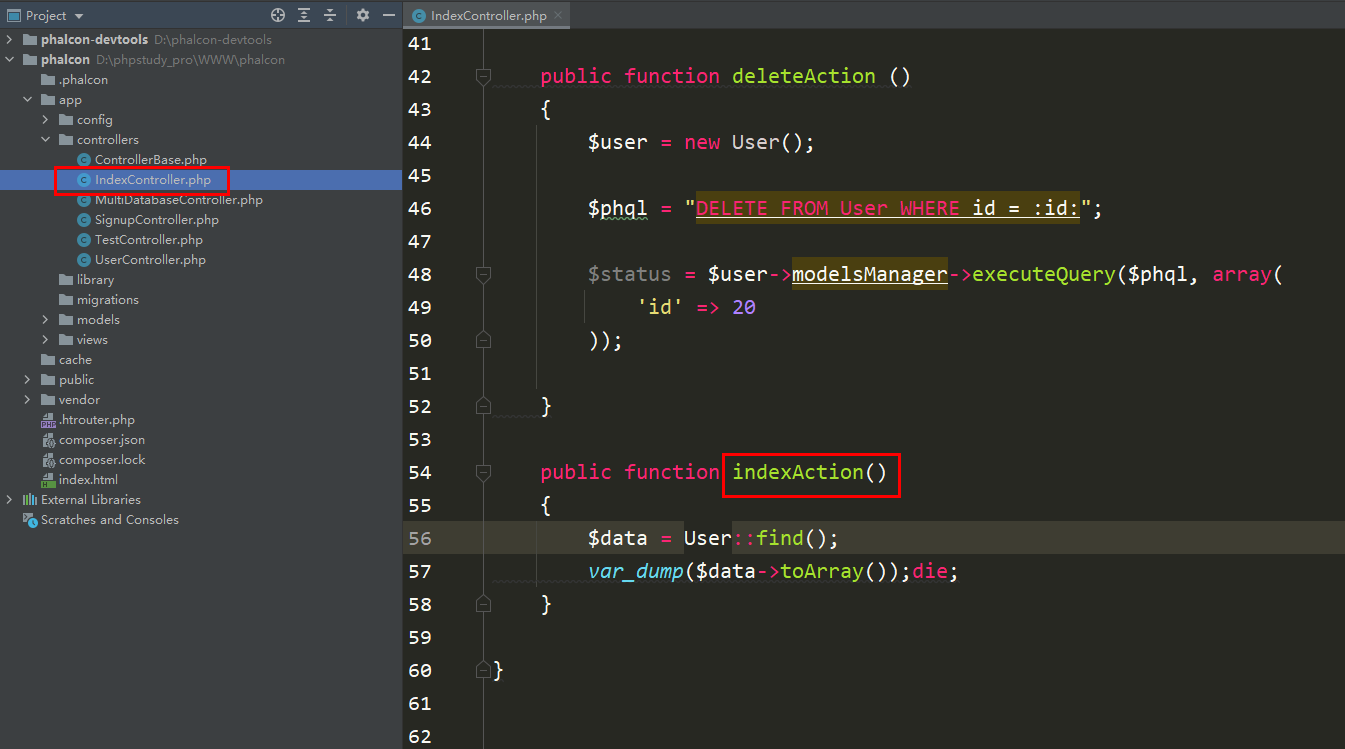
-
05.20 15:34:19发表了文章
2022-05-20 15:34:19
Phalcon如何切换数据库《Phalcon入坑指南系列 三》(1)
Phalcon如何切换数据库《Phalcon入坑指南系列 三》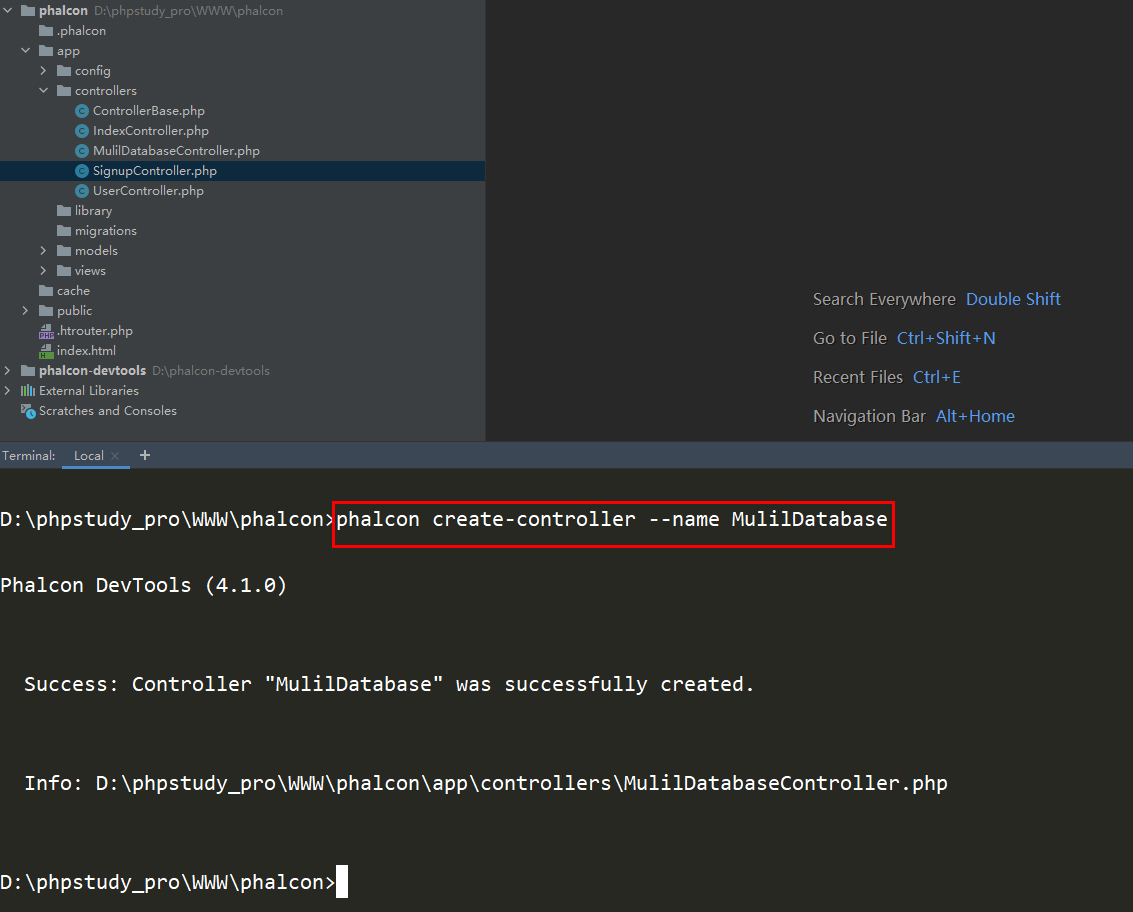
-
05.20 15:31:02发表了文章
2022-05-20 15:31:02
一生挚友redo log、binlog《死磕MySQL系列 二》(2)
一生挚友redo log、binlog《死磕MySQL系列 二》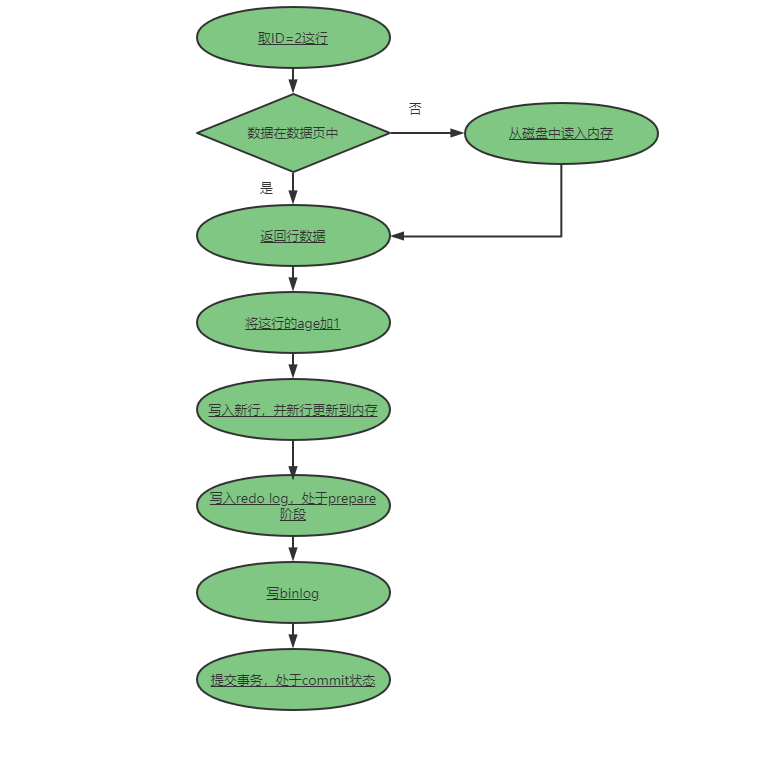
-
05.20 15:29:55发表了文章
2022-05-20 15:29:55
一生挚友redo log、binlog《死磕MySQL系列 二》(1)
一生挚友redo log、binlog《死磕MySQL系列 二》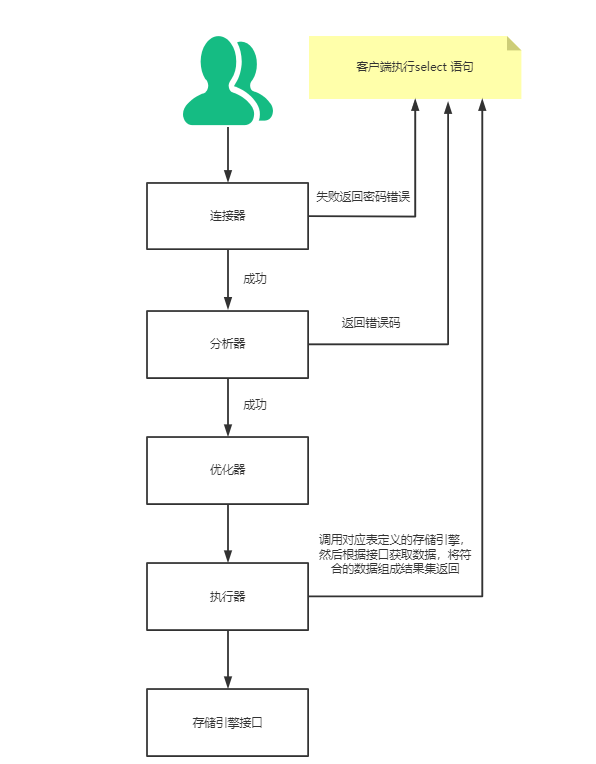
-
05.20 15:28:13发表了文章
2022-05-20 15:28:13
如何写出安全又可靠的PHP脚本
如何写出安全又可靠的PHP脚本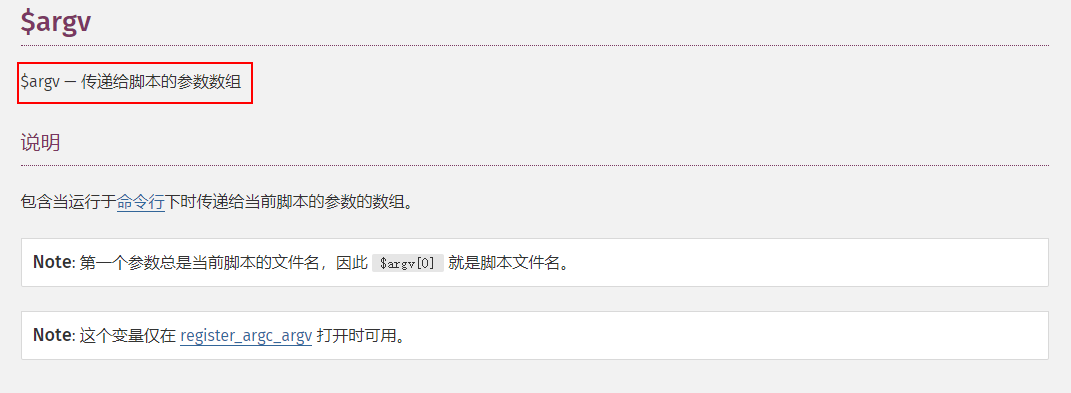
-
05.20 15:26:26发表了文章
2022-05-20 15:26:26
五分钟搞定Docker安装ElasticSearch
五分钟搞定Docker安装ElasticSearch
-
05.20 15:24:03发表了文章
2022-05-20 15:24:03
原来一条select语句在MySQL是这样执行的《死磕MySQL系列 一》
原来一条select语句在MySQL是这样执行的《死磕MySQL系列 一》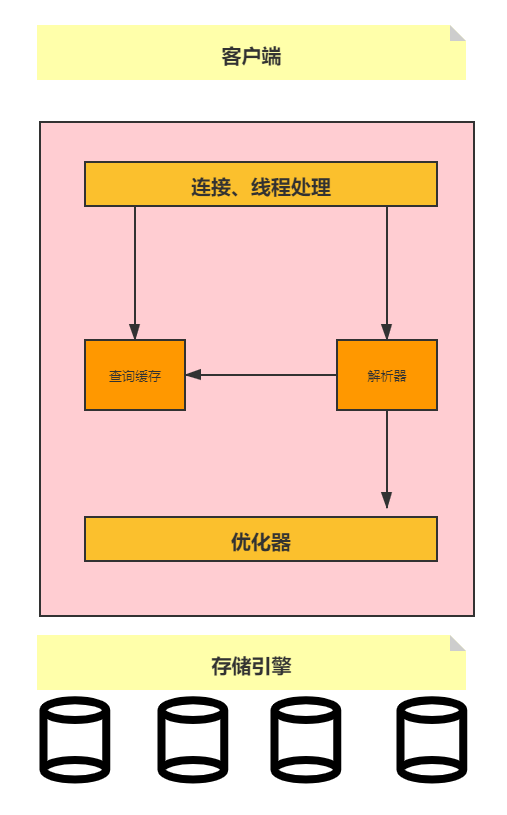
-
发表了文章
2022-05-21
面试问Redis集群,被虐的不行了......(2)
-
发表了文章
2022-05-21
面试问Redis集群,被虐的不行了......(1)
-
发表了文章
2022-05-21
Redis主从复制原理以及常见问题(2)
-
发表了文章
2022-05-21
Redis主从复制原理以及常见问题(1)
-
发表了文章
2022-05-21
为什么不建议给MySQL设置Null值?《死磕MySQL系列 十八》
-
发表了文章
2022-05-21
MySQL对JOIN做了那些不为人知的优化《死磕MySQL系列 十七》(2)
-
发表了文章
2022-05-21
MySQL对JOIN做了那些不为人知的优化《死磕MySQL系列 十七》
-
发表了文章
2022-05-21
速看,ElasticSearch如何处理空值《玩转ElasticSearch 4》-2
-
发表了文章
2022-05-21
速看,ElasticSearch如何处理空值《玩转ElasticSearch 4》-1
-
发表了文章
2022-05-21
速看,ElasticSearch如何处理空值《玩转ElasticSearch 3》-3
-
发表了文章
2022-05-21
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》-3
-
发表了文章
2022-05-21
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》-2
-
发表了文章
2022-05-21
初学者都能学会的ElasticSearch入门实战《玩转ElasticSearch 2》-1
-
发表了文章
2022-05-20
Redis哨兵原理,我忍你很久了!(4)
-
发表了文章
2022-05-20
Redis哨兵原理,我忍你很久了!(3)
-
发表了文章
2022-05-20
Redis哨兵原理,我忍你很久了!(2)
-
发表了文章
2022-05-20
Redis哨兵原理,我忍你很久了!(1)
-
发表了文章
2022-05-20
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》-3
-
发表了文章
2022-05-20
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》-2
-
发表了文章
2022-05-20
终结初学者对ElasticSearch、Kibana、Logstash安装的种种困难《玩转ElasticSearch 1》-1
滑动查看更多
暂无更多信息
暂无更多信息