Ccww

已加入开发者社区721天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝
技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2022年05月
-
05.26 21:28:34
 发表了文章
2022-05-26 21:28:34
发表了文章
2022-05-26 21:28:34
Redis高可用总结:Redis主从复制、哨兵集群、脑裂...
在实际的项目中,服务高可用非常重要,如,当Redis作为缓存服务使用时, 缓解数据库的压力,提高数据的访问速度,提高网站的性能 ,但如果使用Redis 是单机模式运行 ,只要一个服务器宕机就不可以提供服务,这样会可能造成服务效率低下,甚至出现其相对应的服务应用不可用。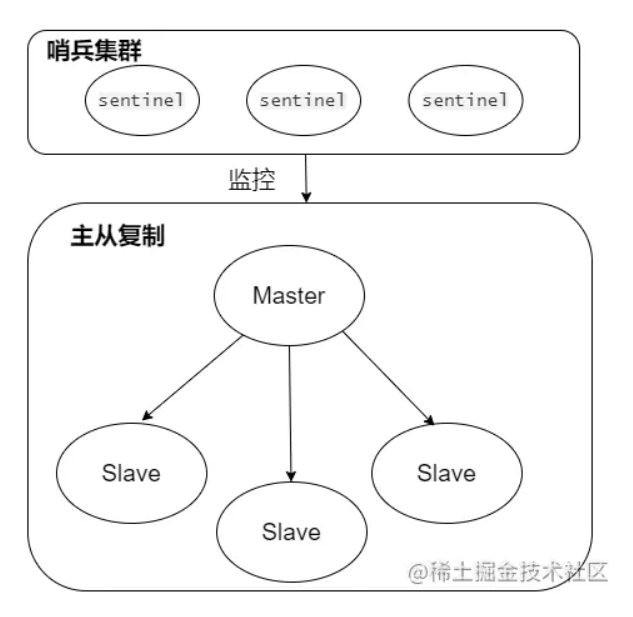
-
05.26 21:20:04发表了文章
2022-05-26 21:20:04
Redis缓存总结:淘汰机制、缓存雪崩、数据不一致....
由于Redis 天然就具有这两个特征,Redis基于内存操作的,且其具有完善的数据淘汰机制,十分适合作为缓存组件。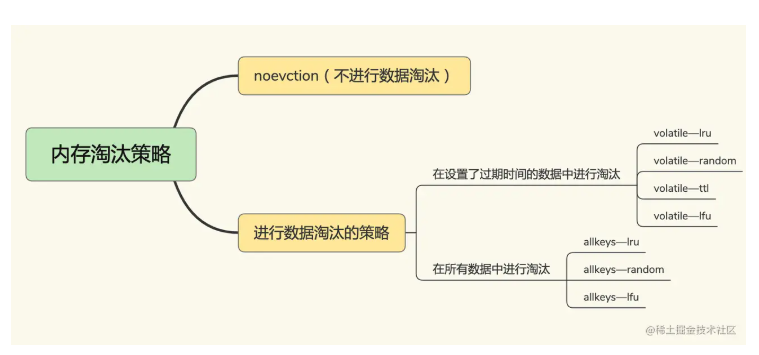
-
05.26 21:15:19发表了文章
2022-05-26 21:15:19
面试:Redis为什么快呢?查询为何会变慢呢?
在实际开发,Redis使用会频繁,那么在使用过程中我们该如何正确抉择数据类型呢?哪些场景下适用哪些数据类型。而且在面试中也很常会被面试官问到Redis数据结构方面的问题: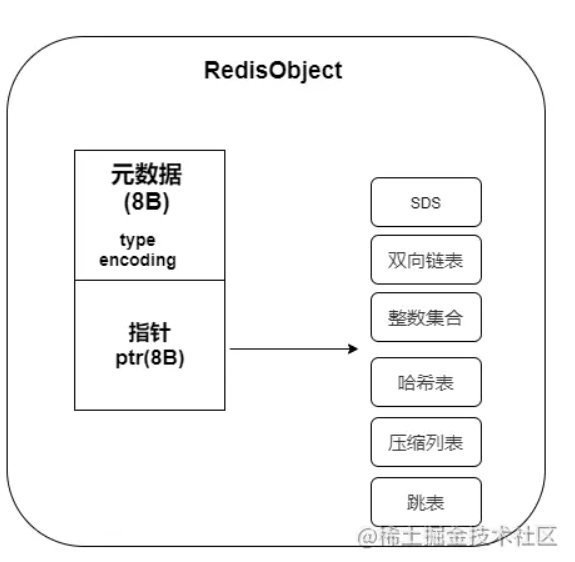
-
05.26 20:53:18发表了文章
2022-05-26 20:53:18
MySQL查询性能优化前,必须先掌握MySQL索引理论
数据库索引在平时的工作是必备的,怎么建索引,怎么使用索引,可以提高数据的查询效率。而且在面试过程,数据库的索引也是必问的知识点,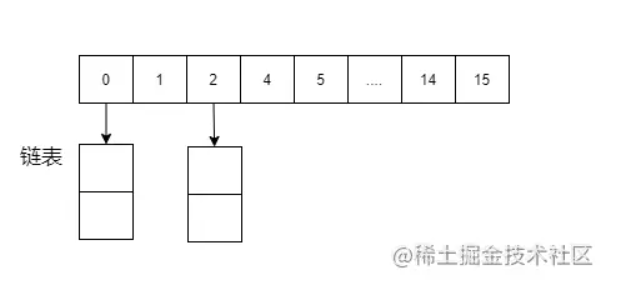
-
05.26 20:44:16发表了文章
2022-05-26 20:44:16
理解完这些基本上能解决面试中MySql的事务问题
在面试中,基本上都会问到关于数据库的事务问题,如果啥都不会或者只回答到表面的上知识点的话,那面试基本上是没戏了,为了能顺利通过面试,那MySql的事务问题就需要了解,所以就根据网上的资料总结一版Mysql事务的知识点,巩固一下事务的知识。
-
05.26 20:32:34发表了文章
2022-05-26 20:32:34
面试:面试官有没有在Mybatis执行过程上为过难你呢?看完就不再怂(图文解析)
在了解了MyBatis初始化加载过程后,我们也应该研究看看SQL执行过程是怎样执行?这样我们对于Mybatis的整个执行流程都熟悉了,在开发遇到问题也可以很快定位到问题。
-
05.26 20:24:26发表了文章
2022-05-26 20:24:26
面试:你知道MyBatis执行过程之初始化是如何执行的吗?
在了解MyBatis架构以及核心内容分析后,我们可以研究MyBatis执行过程,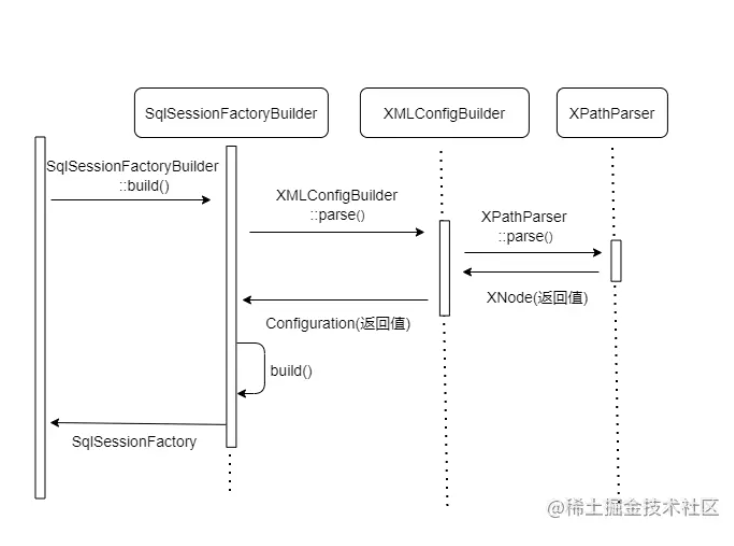
-
05.26 20:17:19发表了文章
2022-05-26 20:17:19
MyBatis面试题分析导读-架构以及核心内容
MyBatis不管在是平时的使用还是在面试中都必须掌握一个知识点,MyBatis 是支持自定义 SQL、存储过程和高级映射的类持久框架,跟数据库打交道的一个开源持久化框架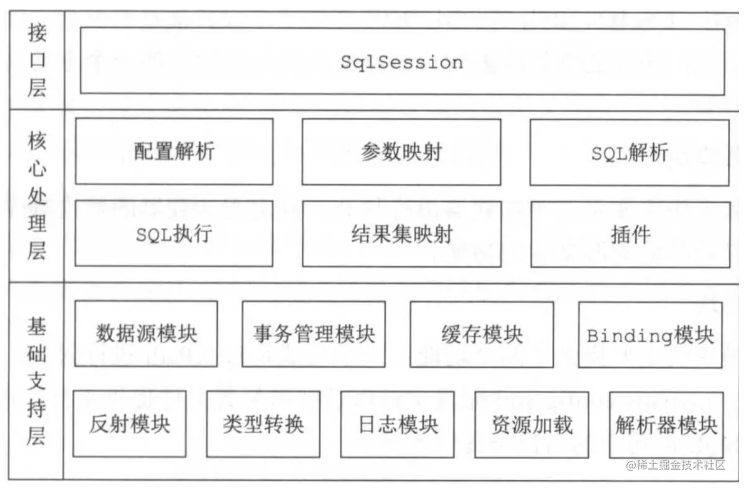
-
05.26 20:11:11发表了文章
2022-05-26 20:11:11
面试:为了进阿里,必须掌握HashMap原理和面试题(图解版一)
集合在基础面试中是必备可缺的一部分,其中重要的HashMap更是少不了,那面试官会面试中提问那些问题呢,这些在JDK1.7和1.8有什么区别??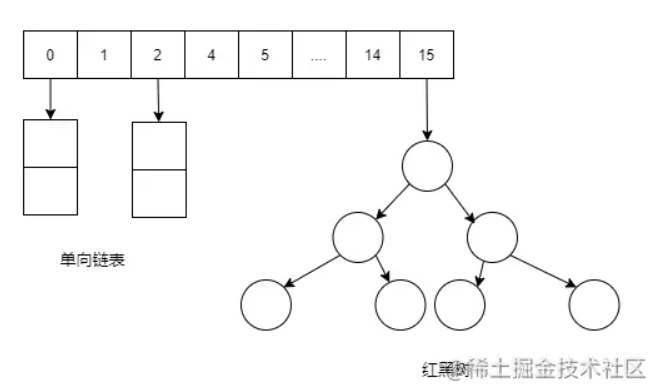
-
05.26 20:03:21发表了文章
2022-05-26 20:03:21
面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(二)
在上篇《面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(一)》,研究了基础原理,以及ConcurrentHashMap数据put的流程等线程安全的,来回顾一下面试的问题点
-
05.26 19:58:26发表了文章
2022-05-26 19:58:26
面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(一)
在平时中集合使用中,当涉及多线程开发时,如果使用HashMap可能会导致死锁问题,使用HashTable效率又不高。而ConcurrentHashMap在保持同步同时并发效率比较高,ConcurrentHashmap是最好的选择,那面试中也会被常常问到,那可能的问题是:
-
05.26 19:53:02发表了文章
2022-05-26 19:53:02
面试:为了进阿里,需要深入理解ReentrantLock原理
在面试,很多时间面试官都会问到锁的问题,ReentrantLock也是常问一个点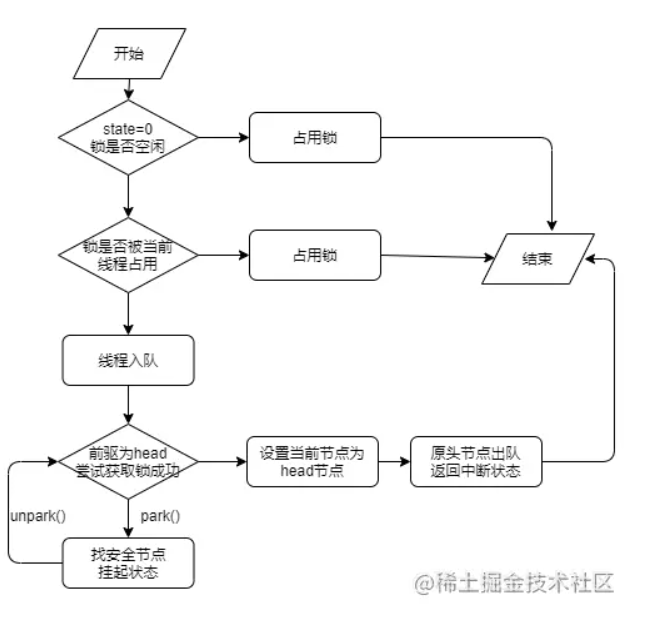
-
05.26 19:48:15发表了文章
2022-05-26 19:48:15
面试:为了进阿里,重新翻阅了Volatile与Synchronized
在深入理解使用Volatile与Synchronized时,应该先理解明白Java内存模型 (Java Memory Model,JMM)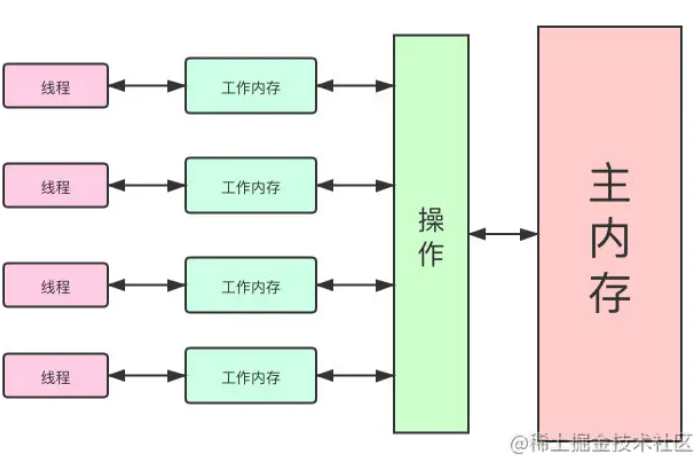
-
05.26 19:42:32发表了文章
2022-05-26 19:42:32
面试:为了进阿里,又把并发CAS(Compare and Swap)实现重新精读一遍
在面试中,并发线程安全提问必然是不会缺少的,那基础的CAS原理也必须了解,这样在面试中才能加分,
-
05.26 19:38:50发表了文章
2022-05-26 19:38:50
面试:在面试中关于List(ArrayList、LinkedList)集合会怎么问呢?你该如何回答呢?
在一开始基础面的时候,很多面试官可能会问List集合一些基础知识,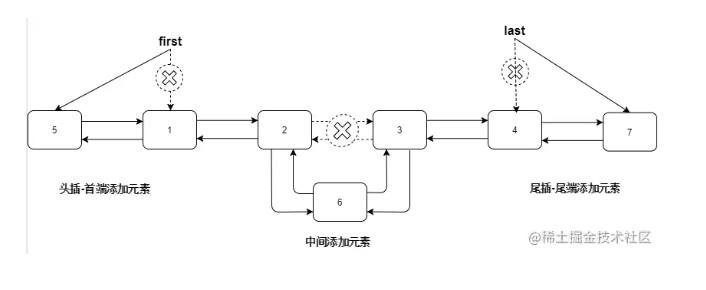
-
05.26 19:33:35发表了文章
2022-05-26 19:33:35
对于单例模式面试官会怎样提问呢?你又该如何回答呢?
在面试的时候面试官会怎么在单例模式中提问呢?你又该如何回答呢?可能你在面试的时候你会碰到这些问题: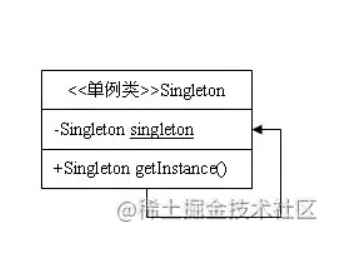
-
05.26 19:26:58发表了文章
2022-05-26 19:26:58
如何快速批量导入非Oracle DB格式的数据--sqlloader
在 Oracle 数据库中,我们通常在不同数据库的表间记录进行复制或迁移时会用以下几种方法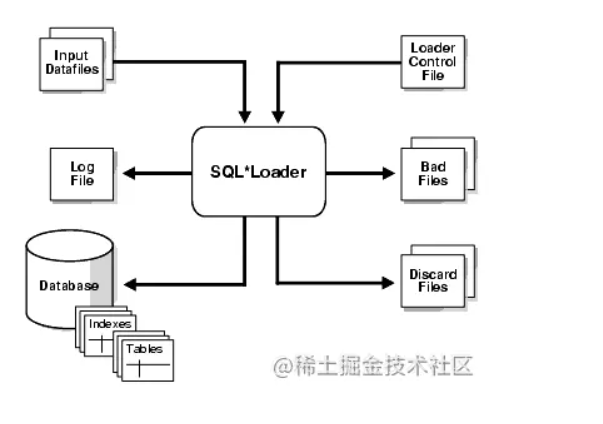
-
05.26 16:41:01发表了文章
2022-05-26 16:41:01
在开发环境下,基于Springboot的RocketMQ示例(含安装步骤、错误分析)
在看这文章之前建议先看看先前架构原理介绍文章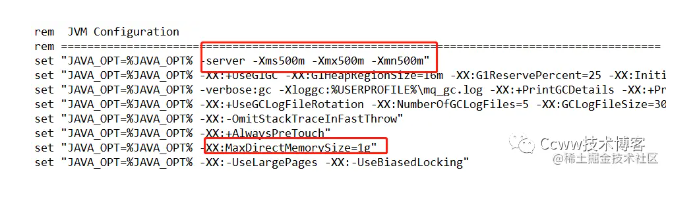
-
05.26 16:31:09发表了文章
2022-05-26 16:31:09
必须先理解的RocketMQ入门手册,才能再次深入解读
RocketMQ是一个分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里研发的一个队列模型的消息中间件,后开源给apache基金会成为了apache的顶级开源项目,具有高性能、高可靠、高实时、分布式特点,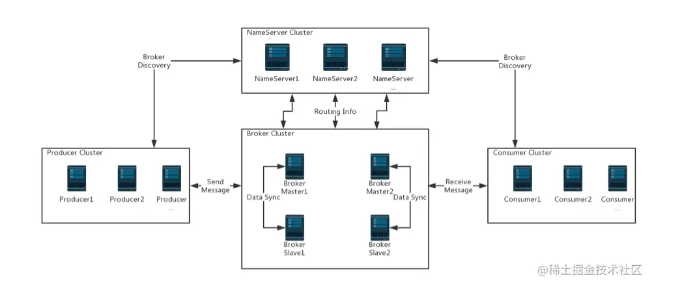
-
05.26 16:21:26发表了文章
2022-05-26 16:21:26
《干货分享》分区表改造(脚本模板生成),值得收藏起来实战再用
太久没有更新技术博客,后续还是保持以前的更新速度,走向新的的学习之路,也欢迎大家一起来学习学习 -
05.26 16:16:13发表了文章
2022-05-26 16:16:13
《提升能力,涨薪可待》-ThreadLocal的内存泄露的原因分析以及如何避免
在分析ThreadLocal导致的内存泄露前,需要普及了解一下内存泄露、强引用与弱引用以及GC回收机制,这样才能更好的分析为什么ThreadLocal会导致内存泄露呢?更重要的是知道该如何避免这样情况发生,增强系统的健壮性。
-
05.26 16:13:09发表了文章
2022-05-26 16:13:09
《提升能力,涨薪可待》-Java多线程与并发之ThreadLocal
ThreadLocal是线程本地变量,可以为多线程的并发问题提供一种解决方式,当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。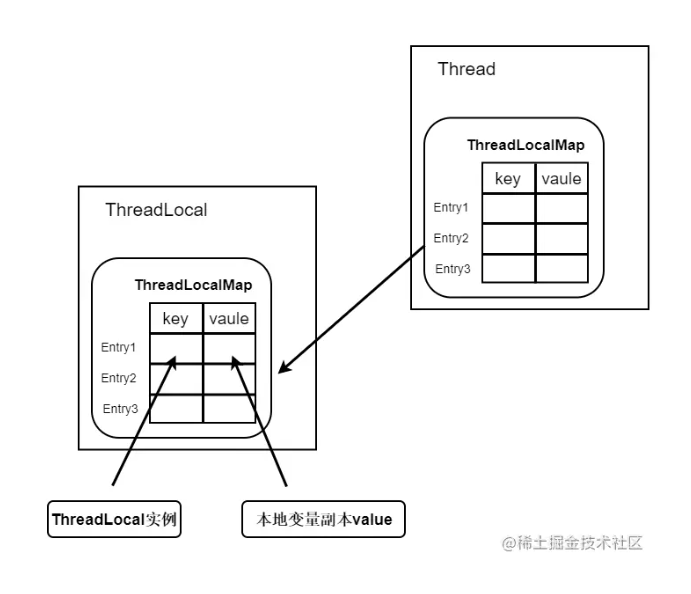
-
05.26 16:08:37发表了文章
2022-05-26 16:08:37
《提升能力,涨薪可待》—Java并发之Synchronized
线程安全是并发编程中的至关重要的, -
05.26 16:05:43发表了文章
2022-05-26 16:05:43
你知道Neo4j这是什么数据库吗?有什么用呢?
对于一个社交网络APP,一定会存在着错综复杂的用户关系以及用户属性,在数据库表的设计中除了要存储每个用户的姓名、性别、喜好这些基本信息外,还需要存储一个用户和哪些用户是朋友 ,和哪些用户是亲人等这些关系数据的用户关系,那Neo4j图数据库就该出场了。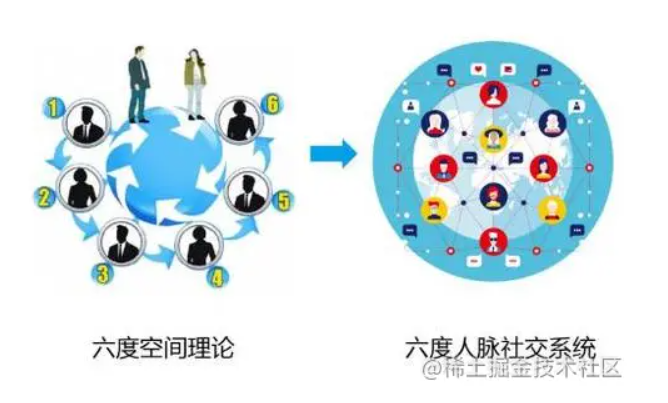
-
05.26 16:01:09发表了文章
2022-05-26 16:01:09
【如何让代码变“高级”(二)】-这样操作值得一波666(Java Stream)(这么有趣)
对于"普通"的CV族来说,这样就差不多了,功能实现了,又可以收拾包袱准备下班了.完美!!! 但对于我们"高级"CV族来,这不够,这远远的不够,我们需要保持一颗折腾的心💗,这样的代码彰显不出我们这段位的价值(青铜😀王者). -
05.26 15:58:22发表了文章
2022-05-26 15:58:22
【面试官之你说我听】-MyBatis常见面试题
既然${}会引起sql注入,为什么有了#{}还需要有${}呢?那其存在的意义是什么? #{}主要用于预编译,而预编译的场景其实非常受限,而${}用于替换,很多场景会出现替换,而这种场景可不是预编译 -
05.26 15:53:02发表了文章
2022-05-26 15:53:02
【如何让代码变“高级”(一)】-Spring组合注解提升代码维度(这么有趣)
在定义某个类或接口时,使用了Spring自带的注解(@Controller、@Service,@Conditional),同时又要使用公司特定的注解标注公司的业务,接着就出现了以下处理方式的那一幕。 -
05.26 15:48:07发表了文章
2022-05-26 15:48:07
【面试宝典】:检验是否为合格的初中级程序员的面试知识点,你都知道了吗?查漏补缺(下)
String 类中使用 final 关键字字符数组保存字符串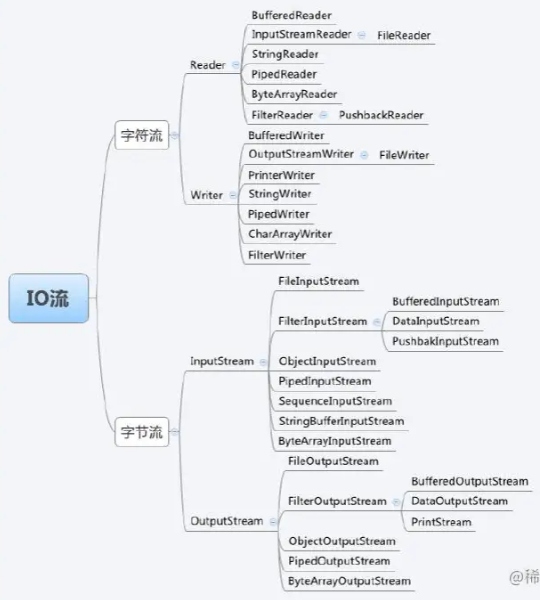
-
05.26 15:40:10发表了文章
2022-05-26 15:40:10
【面试宝典】:检验是否为合格的初中级程序员的面试知识点,你都知道了吗?查漏补缺(上)
在找工作面试应在学习的基础进行总结面试知识点,工作也指日可待,欢迎一起学习【面试知识,工作可待】系列 《面试知识,工作可待篇》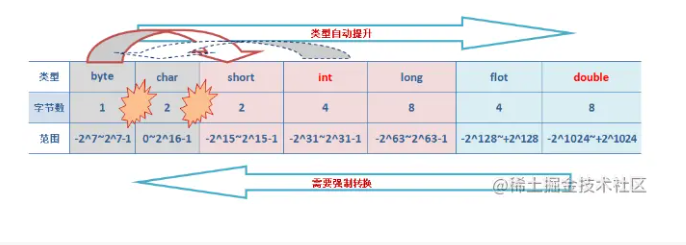
-
05.26 15:31:41发表了文章
2022-05-26 15:31:41
【绝对有收获】看看MQ?必须告诉你为什么要使用MQ消息中间件(图解版)
假设你有个系统A,这个系统A会产出一个核心数据,现在下游有系统B和系统C需要使用这个数据。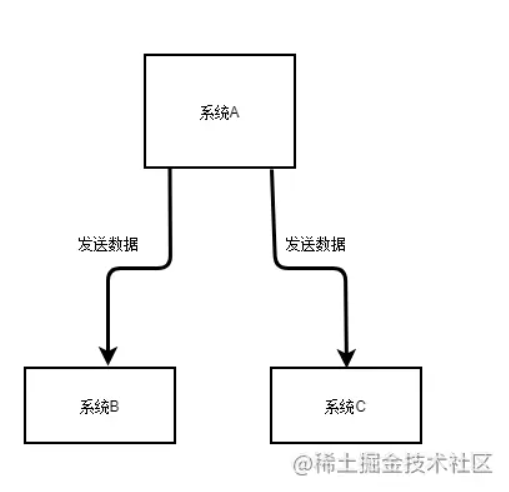
-
05.26 15:21:37发表了文章
2022-05-26 15:21:37
《面试知识,工作可待:集合篇》-java集合面试知识大全
在工作上必须保持学习的能力,这样才能在工作得到更好的晋升,涨薪指日可待,欢迎一起学习【提升能力,涨薪可待】系列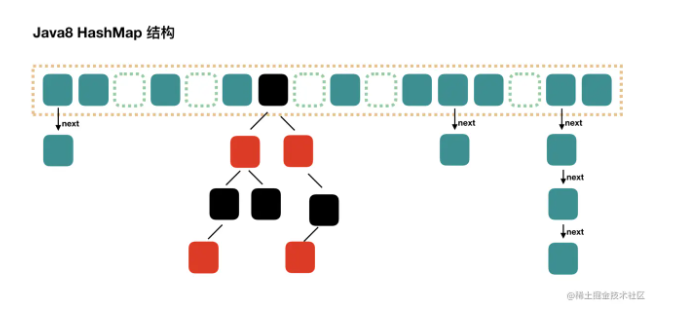
-
05.26 15:14:10发表了文章
2022-05-26 15:14:10
《提升能力,涨薪可待》-如何设计一个符合自己公司的微服务架构
在工作上必须保持学习的能力,这样才能在工作得到更好的晋升,涨薪指日可待,欢迎一起学习【提升能力,涨薪可待】系列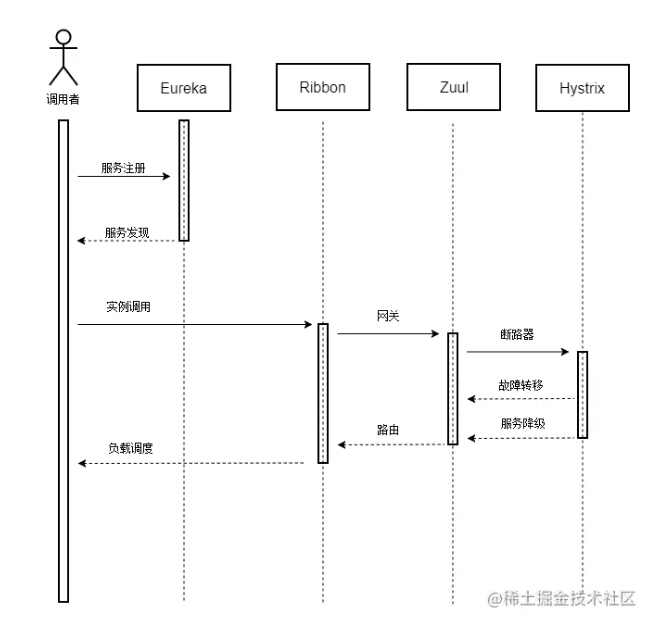
-
05.26 15:08:18发表了文章
2022-05-26 15:08:18
《提升能力,涨薪可待》-Java并发之AQS全面详解
在工作上必须保持学习的能力,这样才能在工作得到更好的晋升,涨薪指日可待,欢迎一起学习【提升能力,涨薪可待】系列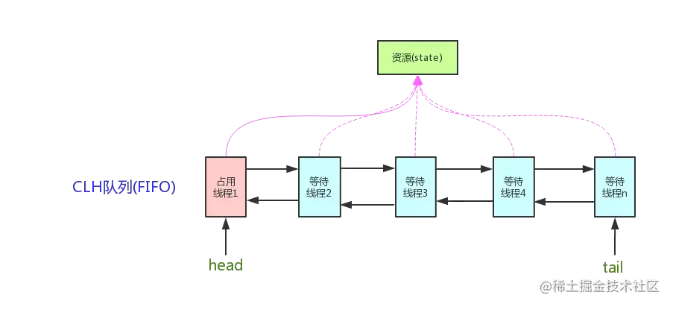
-
05.26 11:23:51发表了文章
2022-05-26 11:23:51
java多线程并发系列--基础知识点(笔试、面试必备)(下)
多个线程间锁的并发控制,对象锁多个线程、每个线程持有该方法所属对象的锁以及类锁。synchronized, wait, notify 是任何对象都具有的同步工具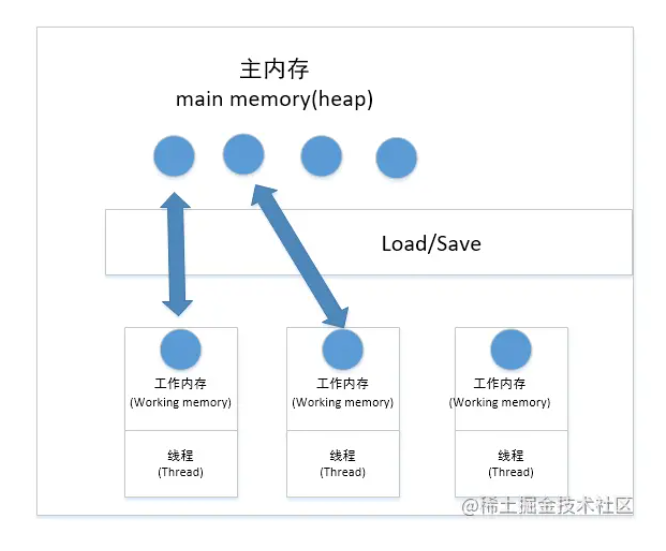
-
05.26 11:15:27发表了文章
2022-05-26 11:15:27
java多线程并发系列--基础知识点(笔试、面试必备)(上)
多线程和并发是求职大小厂面试中必问的知识点,其涉及到点很多,难度很大。有些人面对这些问题有点迷茫,为了解决这情况,总结了一下java多线程并发的基础知识点。而且要想深入研究java多线程并发也必须先掌握基础知识,可为后续各个模块深入研究做好做好准备。现在废话不多说,各位看官请查看基础知识点,后续还有源码解析(synchronize底层原理,线程池原理,Lock,AQS,同步、并发容器等源码解析)。
-
05.26 11:07:22发表了文章
2022-05-26 11:07:22
面试:简明的图解Redis RDB持久化、AOF持久化(续集)
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态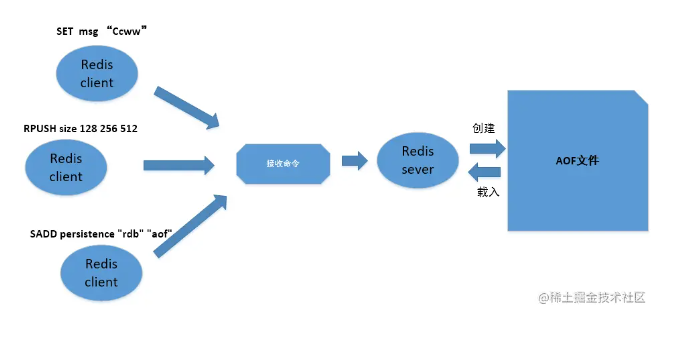
-
05.26 11:03:00发表了文章
2022-05-26 11:03:00
面试:简明的图解Redis RDB持久化、AOF持久化
持久化(Persistence),持久化是将程序数据在持久状态和瞬时状态间转换的机制,即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。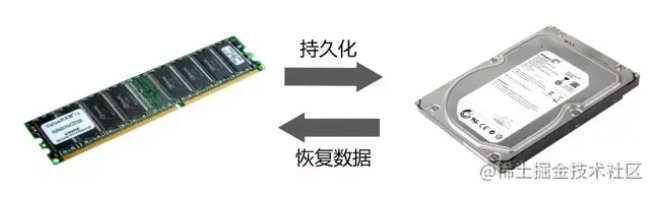
-
05.26 10:56:19发表了文章
2022-05-26 10:56:19
微服务中如何使用RestTemplate优雅调用API(拦截器、异常处理、消息转换)
在微服务中,rest服务互相调用是很普遍的,我们该如何优雅地调用,其实在Spring框架使用RestTemplate类可以优雅地进行rest服务互相调用,它简化了与http服务的通信方式,统一了RESTful的标准,封装了http链接,操作使用简便,还可以自定义RestTemplate所需的模式 -
05.26 10:53:07发表了文章
2022-05-26 10:53:07
面试:原来Redis常用的五种数据类型底层结构是这样的
在Redis中会涉及很多数据结构,比如SDS,双向链表、字典、压缩列表、整数集合等等。Redis会基于这些数据结构自定义一个对象系统,而且自定义的对象系统有很多好处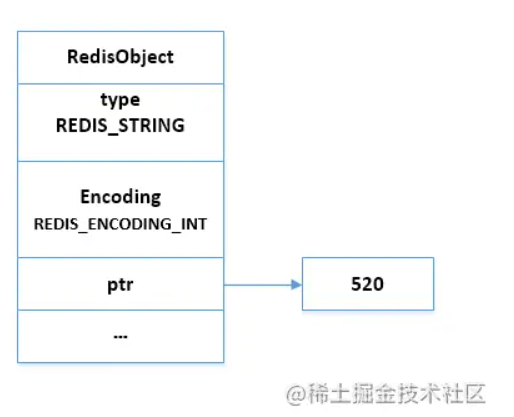
-
05.26 10:44:50发表了文章
2022-05-26 10:44:50
当遇到美女面试官之如何理解Redis的Expire Key(过期键)
在面试中遇到美女面试官时,我们以为面试会比较容易过,也能好好表现自己技术的时候了。然而却出现以下这一幕,当美女面试官听说你使用过Redis时,那么问题来了。
-
05.26 10:39:43发表了文章
2022-05-26 10:39:43
赶紧收藏起MongoDB面试题轻松面对BAT灵魂式的拷问(下)
MongoDB是基于分布式文件存储的数据库,由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案,且MongodDB是一个介于关系数据库与非关系数据库之间的产品,是非关系型数据库中功能最丰富,最像关系数据库。 -
05.26 10:38:30发表了文章
2022-05-26 10:38:30
赶紧收藏起MongoDB面试题轻松面对BAT灵魂式的拷问(上)
MongoDB是基于分布式文件存储的数据库,由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案,且MongodDB是一个介于关系数据库与非关系数据库之间的产品,是非关系型数据库中功能最丰富,最像关系数据库。 -
05.26 10:30:17发表了文章
2022-05-26 10:30:17
MongoDB--Spring Data MongoDB详细的操作手册(增删改查)
在NoSQL盛行的时代,App很大可能会涉及到MongoDB数据库的使用,而也必须学会在Spring boot使用Spring Data连接MongoDB进行数据增删改查操作,如下为详细的操作手册。 -
05.26 10:26:53发表了文章
2022-05-26 10:26:53
【SpringBoot2.x】-SpringBoot Web开发中Thymeleaf、Web、Tomcat以及Favicon
Web开发是开发中至关重要的一部分, Web开发的核心内容主要包括内嵌Servlet容器和Spring MVC。更重要的是,Spring Boot``为web开发提供了快捷便利的方式进行开发,使用依赖jar:spring-boot-starter-web,提供了嵌入式服务器Tomcat以及Spring MVC的依赖,且自动配置web相关配置,可查看org.springframework.boot.autoconfigure.web。
-
05.26 10:20:32发表了文章
2022-05-26 10:20:32
【SpringBoot2.x】-自定义Spring boot Starter(原理、demo代码实现以及解决面试问题)
SpringBoot的方便快捷主要体现之一starter pom,Spring Boot为我们提供了简化企业级开发绝大多数场景的starter pom, 只要使用了应用场景所需要的starter pom,只需要引入对应的starter即可,即可以得到Spring Boot为我们提供的自动配置的Bean。 -
05.25 23:59:55发表了文章
2022-05-25 23:59:55
【SpringBoot2.x】--Spring Boot核心(原理以及代码实现)
SpringBoot作为我们日常开发的框架,我们必须熟悉掌握SpringBoot基础核心,包括SpringBoot运行原理、基础配置、外部配置、日志配置、Profile配置、核心注解等等,
-
05.25 23:53:24发表了文章
2022-05-25 23:53:24
-
05.25 23:05:16发表了文章
2022-05-25 23:05:16
(超长篇 ,谨入)推荐收藏系列-SpringBoot配置大全总结(上)
在pom.xml中配置Java版本 -
05.25 22:38:05发表了文章
2022-05-25 22:38:05
[超长文,谨入]一文解决面试、工作遇到的安全性问题
安全问题其实是很多程序员容易忽略的问题但需要我们重视起来,提高应用程序的安全性。常出现的安全问题包括,程序接受数据可能来源于未经验证的用户,网络连接和其他不受信任的来源,如果未对程序接受数据进行校验,则可能会引发安全问题等等
-
05.25 22:18:59发表了文章
2022-05-25 22:18:59
安全开发规范:开发人员必须了解开发安全规范(一)(涉及安全问题,以及解决方法和代码实现)
安全问题其实是很多程序员想了解又容易忽略的问题,但需要我们重视起来,提高应用程序的安全性。常出现的安全问题包括,程序接受数据可能来源于未经验证的用户,网络连接和其他不受信任的来源,如果未对程序接受数据进行校验,则可能会引发安全问题等等
-
发表了文章
2022-05-26
Redis高可用总结:Redis主从复制、哨兵集群、脑裂...
-
发表了文章
2022-05-26
Redis缓存总结:淘汰机制、缓存雪崩、数据不一致....
-
发表了文章
2022-05-26
面试:Redis为什么快呢?查询为何会变慢呢?
-
发表了文章
2022-05-26
MySQL查询性能优化前,必须先掌握MySQL索引理论
-
发表了文章
2022-05-26
理解完这些基本上能解决面试中MySql的事务问题
-
发表了文章
2022-05-26
面试:面试官有没有在Mybatis执行过程上为过难你呢?看完就不再怂(图文解析)
-
发表了文章
2022-05-26
面试:你知道MyBatis执行过程之初始化是如何执行的吗?
-
发表了文章
2022-05-26
MyBatis面试题分析导读-架构以及核心内容
-
发表了文章
2022-05-26
面试:为了进阿里,必须掌握HashMap原理和面试题(图解版一)
-
发表了文章
2022-05-26
面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(二)
-
发表了文章
2022-05-26
面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(一)
-
发表了文章
2022-05-26
面试:为了进阿里,需要深入理解ReentrantLock原理
-
发表了文章
2022-05-26
面试:为了进阿里,重新翻阅了Volatile与Synchronized
-
发表了文章
2022-05-26
面试:为了进阿里,又把并发CAS(Compare and Swap)实现重新精读一遍
-
发表了文章
2022-05-26
面试:在面试中关于List(ArrayList、LinkedList)集合会怎么问呢?你该如何回答呢?
-
发表了文章
2022-05-26
对于单例模式面试官会怎样提问呢?你又该如何回答呢?
-
发表了文章
2022-05-26
如何快速批量导入非Oracle DB格式的数据--sqlloader
-
发表了文章
2022-05-26
在开发环境下,基于Springboot的RocketMQ示例(含安装步骤、错误分析)
-
发表了文章
2022-05-26
必须先理解的RocketMQ入门手册,才能再次深入解读
-
发表了文章
2022-05-26
《干货分享》分区表改造(脚本模板生成),值得收藏起来实战再用
滑动查看更多
暂无更多信息
暂无更多信息