
德哥

已加入开发者社区2359天
勋章

MVP_Star
MVP_Star

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

开发者认证勋章
开发者认证勋章

江湖新秀
江湖新秀



我关注的人









粉丝
pfk3zgwt4z6u2
pfk3zgwt4z6u2
游客kufjpufzm3kco
游客kufjpufzm3kco
1896568931743859
1896568931743859
tgyd2018
tgyd2018
枫度
枫度
游客sefspres6inga
游客sefspres6inga
游客jggrgmkzq2omm
游客jggrgmkzq2omm
1657519812376575
1657519812376575
nick5084733268
nick5084733268
哈基米1220
哈基米1220
tvcvtyv3aheaq
tvcvtyv3aheaq
游客ihpiud4dfufue
游客ihpiud4dfufue
技术能力
兴趣领域
- 数据库
- PostgreSQL
- PolarDB
- DuckDB
- ADB
擅长领域
技术认证
-
-
 阿里云大模型高级工程师ACP认证
获得于2025-04-12 14:29:09
阿里云大模型高级工程师ACP认证
获得于2025-04-12 14:29:09 -
阿里云关系型数据库工程师ACP认证(Alibaba Cloud Certified Professional - Relational Database)
获得于2022-01-28 12:31:40
-
-
-
阿里云大模型工程师ACA认证
获得于2025-04-10 17:24:30
-
阿里云云数据库助理工程师认证(ACA)
获得于2021-04-25 13:55:35
-
公益是一辈子的事, I am digoal, just do it. 阿里云数据库团队, 擅长PolarDB, PostgreSQL, DuckDB, ADB等, 长期致力于推动开源数据库技术、生态在中国的发展与开源产业人才培养. 曾荣获阿里巴巴麒麟布道师称号、2018届OSCAR开源尖峰人物.
暂无精选文章
暂无更多信息
2024年05月
-
04.22 16:59:25
 发表了文章
2024-04-22 16:59:25
发表了文章
2024-04-22 16:59:25
使用 PolarDB 开源版 部署 PostGIS 支撑时空轨迹|地理信息|路由等业务
背景PolarDB 的云原生存算分离架构,,具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理;;PolarDB与计算算法结合,,将实现双剑合璧,推动业务数据的价值产出,将数据变成生产力。本文将介绍使用 PolarDB 开源版 部署 PostGIS 支撑时空轨迹|地理信息|路... -
04.22 16:59:23发表了文章
2024-04-22 16:59:23
使用 PolarDB 开源版 部署 pgrouting 支撑出行、快递、配送等商旅问题的路径规划业务
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.本文将介绍使用 PolarDB 开源版 部署 pgrouting 支撑出行、快递、配... -
04.22 16:59:22发表了文章
2024-04-22 16:59:22
使用 PolarDB 开源版 部署 pgpointcloud 支撑激光点云数据的高速存储、压缩、高效精确提取
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.本文将介绍使用 PolarDB 开源版 部署 pgpointcloud 支撑激光点云... -
04.22 16:59:21发表了文章
2024-04-22 16:59:21
PolarDB 开源版 通过pgpointcloud 实现高效孪生数据存储和管理 - 支撑工厂、农业等现实世界数字化|数字孪生, 元宇宙相关业务的虚拟现实结合
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理;PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力。本文将介绍PolarDB 开源版 通过 pgpointcloud 实现高效孪生数据存储... -
04.22 16:59:20发表了文章
2024-04-22 16:59:20
PolarDB 开源版 通过rdkit 支撑生物、化学分子结构数据存储与计算、分析
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.本文将介绍PolarDB 开源版 通过rdkit 支撑生物、化学分子结构数据存储与计... -
04.22 16:59:17发表了文章
2024-04-22 16:59:17
PolarDB 开源版 轨迹应用实践 - 出行、配送、快递等业务的调度; 传染溯源; 刑侦
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理,PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出,将数据变成生产力。本文将介绍PolarDB 开源版 轨迹应用实践,例如:出行、配送、快递等业务的调度快递员... -
04.22 16:59:15发表了文章
2024-04-22 16:59:15
PolarDB 开源版 使用pgpool-II实现透明读写分离
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.本文将介绍PolarDB 开源版 使用pgpool-II实现透明读写分离.pgpoo... -
04.22 16:59:14发表了文章
2024-04-22 16:59:14
PolarDB 开源版 使用PostGIS 以及泰森多边形 解决 零售、配送、综合体、教培、连锁店等经营|通信行业基站建设功率和指向 的地理最优解问题
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.本文将介绍PolarDB 开源版 使用PostGIS 以及泰森多边形 解决 "零售、... -
04.22 16:59:11发表了文章
2024-04-22 16:59:11
PolarDB 开源版 使用PostGIS 数据寻龙点穴(空间聚集分析)- 大数据与GIS分析解决线下店铺选址问题
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.本文将介绍PolarDB 开源版 使用PostGIS 数据寻龙点穴(空间聚集分析)-... -
04.22 16:59:10发表了文章
2024-04-22 16:59:10
PolarDB 开源版 使用TimescaleDB 实现时序数据高速写入、压缩、实时聚合计算、自动老化等
背景PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.本文将介绍PolarDB 开源版 使用TimescaleDB 实现时序数据高速写入、... -
04.22 16:48:59发表了文章
2024-04-22 16:48:59
基于阿里云RDS PostgreSQL打造实时用户画像推荐系统(varbitx))
用户画像在市场营销的应用重建中非常常见,已经不是什么新鲜的东西,比较流行的解决方案是给用户贴标签,根据标签的组合,圈出需要的用户。通常画像系统会用到宽表,以及分布式的系统。宽表的作用是存储标签,例如每列代表一个标签。但实际上这种设计不一定是最优或唯一的设计,本文将以PostgreSQL数据库为基础,给大家讲解一下更加另类的设计思路,并且看看效率如何。
2023年10月
-
10.13 13:45:29发表了文章
2023-10-13 13:45:29
沉浸式学习PostgreSQL|PolarDB 21,相似图像搜索
传统数据库不支持图像类型, 图像相似计算函数, 图像相似计算操作服, 相似排序操作符. 所以遇到类似的需求, 需要自行编写应用来解决. PG|PolarDB 通过imgsmlr插件, 可以将图像转换为向量特征值, 使用相似距离计算函数得到相似值, 使用索引加速相似度排序, 快速获得相似图片, 实现以图搜图. 也可以通过pgvector插件来存储图片向量特征值, 结合大模型服务(抠图、图像向量转换), 可以实现从图像转换、基于图像的相似向量检索全流程能力. -
10.12 13:39:34发表了文章
2023-10-12 13:39:34
沉浸式学习PostgreSQL|PolarDB 20: 学习成为数据库大师级别的优化技能
在上一个实验《沉浸式学习PostgreSQL|PolarDB 19: 体验最流行的开源企业ERP软件 odoo》 中, 学习了如何部署odoo和polardb|pg. 由于ODOO是非常复杂的ERP软件, 对于关系数据库的挑战也非常大, 所以通过odoo业务可以更快速提升同学的数据库优化能力, 发现业务对数据库的使用问题(如索引、事务对锁的运用逻辑问题), 数据库的代码缺陷, 参数或环境配置问题, 系统瓶颈等. -
10.12 13:38:35发表了文章
2023-10-12 13:38:35
沉浸式学习PostgreSQL|PolarDB 19: 体验最流行的开源企业ERP软件 odoo
本文主要教大家怎么用好数据库, 而不是怎么运维管理数据库、怎么开发数据库内核. -
10.07 15:22:13发表了文章
2023-10-07 15:22:13
沉浸式学习PostgreSQL|PolarDB 18: 通过GIS轨迹相似伴随|时态分析|轨迹驻点识别等技术对拐卖、诱骗场景进行侦查
本文主要教大家怎么用好数据库, 而不是怎么运维管理数据库、怎么开发数据库内核.
2023年09月
-
09.22 16:54:13发表了文章
2023-09-22 16:54:13
沉浸式学习PostgreSQL|PolarDB 17: 向量数据库, 通义大模型AI的外脑
本文所涉及的实验体验的就是怎么建设AI的外脑?向量数据库的核心价值:AI外脑 -
09.21 15:48:30发表了文章
2023-09-21 15:48:30
新生产力工具AI推动下一级人类文明跃迁? AI如何倒逼数据库的进化? AI加持后的数据库应用场景有哪些变化?
新生产力工具AI会催生下一级人类文明跃迁吗? 数据库进化出了哪些与AI相结合的能力? AI加持后的数据库应用场景有哪些变化? -
09.14 20:30:13发表了文章
2023-09-14 20:30:13
沉浸式学习PostgreSQL|PolarDB 16: 植入通义千问大模型+文本向量化模型, 让数据库具备AI能力
本文将带领大家来体验一下如何将“千问大模型+文本向量化模型”植入到PG|PolarDB中, 让数据库具备AI能力.
-
09.14 20:28:00发表了文章
2023-09-14 20:28:00
沉浸式学习PostgreSQL|PolarDB 15: 企业ERP软件、网站、分析型业务场景、营销场景人群圈选, 任意字段组合条件数据筛选
本篇文章目标学习如何快速在任意字段组合条件输入搜索到满足条件的数据. -
09.14 20:25:57发表了文章
2023-09-14 20:25:57
沉浸式学习PostgreSQL|PolarDB 14: 共享单车、徒步、旅游、网约车轨迹查询
本文的目的是帮助你了解如何设计轨迹表, 如何高性能的写入、查询、分析轨迹数据. -
09.14 20:24:47发表了文章
2023-09-14 20:24:47
沉浸式学习PostgreSQL|PolarDB 13: 博客、网站按标签内容检索, 并按匹配度排序
本文主要教大家怎么用好数据库, 而不是怎么运维管理数据库、怎么开发数据库内核. -
09.06 17:56:43发表了文章
2023-09-06 17:56:43
沉浸式学习PostgreSQL|PolarDB 12: 如何快速构建 海量 逼真 测试数据
本文主要教大家怎么用好数据库, 而不是怎么运维管理数据库、怎么开发数据库内核. -
09.06 09:41:48发表了文章
2023-09-06 09:41:48
沉浸式学习PostgreSQL|PolarDB 11: 物联网(IoT)、监控系统、应用日志、用户行为记录等场景 - 时序数据高吞吐存取分析
物联网场景, 通常有大量的传感器(例如水质监控、气象监测、新能源汽车上的大量传感器)不断探测最新数据并上报到数据库. 监控系统, 通常也会有采集程序不断的读取被监控指标(例如CPU、网络数据包转发、磁盘的IOPS和BW占用情况、内存的使用率等等), 同时将监控数据上报到数据库. 应用日志、用户行为日志, 也就有同样的特征, 不断产生并上报到数据库. 以上数据具有时序特征, 对数据库的关键能力要求如下: 数据高速写入 高速按时间区间读取和分析, 目的是发现异常, 分析规律. 尽量节省存储空间 -
09.06 09:40:59发表了文章
2023-09-06 09:40:59
沉浸式学习PostgreSQL|PolarDB 10: 社交、刑侦等业务, 关系图谱搜索
业务场景1 介绍: 社交、刑侦等业务, 关系图谱搜索 - 营销、分销、流量变现、分佣、引爆流行、裂变式传播、家谱、选课、社交、人才库、刑侦、农产品溯源、药品溯源 图式搜索是PolarDB | PostgreSQL在(包括流计算、全文检索、图式搜索、K-V存储、图像搜索、指纹搜索、空间数据、时序数据、推荐等)诸多特性中的一个。 采用CTE语法,可以很方便的实现图式搜索(N度搜索、最短路径、点、边属性等)。 其中图式搜索中的:层级深度,是否循环,路径,都是可表述的。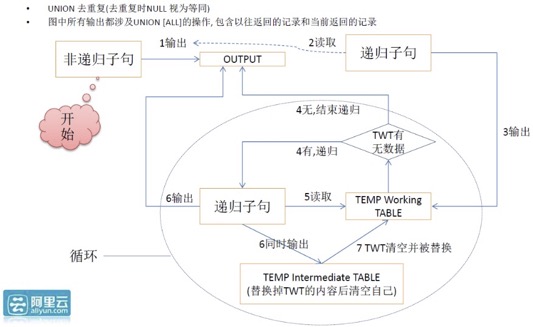
-
09.06 09:39:26发表了文章
2023-09-06 09:39:26
沉浸式学习PostgreSQL|PolarDB 9: AI大模型+向量数据库, 提升AI通用机器人在专业领域的精准度, 完美诠释柏拉图提出的“知识是回忆而不是知觉”
越来越多的企业和个人希望能够利用LLM和生成式人工智能来构建专注于其特定领域的具备AI能力的产品。目前,大语言模型在处理通用问题方面表现较好,但由于训练语料和大模型的生成限制,对于垂直专业领域,则会存在知识深度和时效性不足的问题。在信息时代,由于企业的知识库更新频率越来越高,并且企业所拥有的垂直领域知识库(例如文档、图像、音视频等)往往是未公开或不可公开的。因此,对于企业而言,如果想在大语言模型的基础上构建属于特定垂直领域的AI产品,就需要不断将自身的知识库输入到大语言模型中进行训练。 -
09.06 09:38:35发表了文章
2023-09-06 09:38:35
沉浸式学习PostgreSQL|PolarDB 8: 电商|短视频|新闻|内容推荐业务(根据用户行为推荐相似内容)、监控预测报警系统(基于相似指标预判告警)、音视图文多媒体相似搜索、人脸|指纹识别|比对 - 向量搜索应用
1、在电商业务中, 用户浏览商品的行为会构成一组用户在某个时间段的特征, 这个特征可以用向量来表达(多维浮点数组), 同时商品、店铺也可以用向量来表达它的特征. 那么为了提升用户的浏览体验(快速找到用户想要购买的商品), 可以根据用户向量在商品和店铺向量中进行相似度匹配搜索. 按相似度来推荐商品和店铺给用户. 2、在短视频业务中, 用户浏览视频的行为, 构成了这个用户在某个时间段的兴趣特征, 这个特征可以用向量来表达(多维浮点数组), 同时短视频也可以用向量来表达它的特征. 那么为了提升用户的观感体验(推荐他想看的视频), 可以在短视频向量中进行与用户特征向量的相似度搜索. -
09.06 09:37:35发表了文章
2023-09-06 09:37:35
沉浸式学习PostgreSQL|PolarDB 7: 移动社交、多媒体、内容分发、游戏业务场景, 跨地域多机房的智能加速
在移动社交、多媒体、内容分发业务场景中, 如果用户要交互的内容都在中心网络(假设深圳), 现在用户流动非常频繁, 当用户从深圳出差到北京, 因为网络延迟急剧增加, 他的访问体验就会变得非常差. 网络延迟对游戏业务的影响则更加严重. 为了解决这个问题, 企业会将业务部署在全国各地, 不管用户在哪里出差, 他都可以就近访问最近的中心. 由于标记用户的只有IP地址, 怎么根据用户的接入IP来判断他应该访问哪个中心呢? 通过这个实验, 大家可以了解到在数据库中如何存储IP地址范围和各中心IDC的映射关系, 以及如何根据用户的来源IP(接入IP)来判断他应该去哪个中心IDC访问. -
09.06 09:36:33发表了文章
2023-09-06 09:36:33
沉浸式学习PostgreSQL|PolarDB 6: 预定会议室、划分管辖区
会议室预定系统最关键的几个点: 1、查询: 按位置、会议室大小、会议室设备(是否有投屏、电话会议、视频会议...)、时间段查询符合条件的会议室. 2、预定: 并写入已订纪录. 3、强约束: 防止同一个会议室的同一个时间片出现被多人预定的情况. -
09.06 09:35:24发表了文章
2023-09-06 09:35:24
沉浸式学习PostgreSQL|PolarDB 5: 零售连锁、工厂等数字化率较低场景的数据分析
零售连锁, 制作业的工厂等场景中, 普遍数字化率较低, 通常存在这些问题: 数据离线, 例如每天盘点时上传, 未实现实时汇总到数据库中. 数据格式多, 例如excel, csv, txt, 甚至纸质手抄. 让我们一起来思考一下, 如何使用较少的投入实现数据汇总分析?
2023年08月
-
08.25 15:15:21发表了文章
2023-08-25 15:15:21
沉浸式学习PostgreSQL|PolarDB 4: 跨境电商场景, 快速判断商标|品牌侵权
很多业务场景中需要判断商标侵权, 避免纠纷. 例如 电商的商品文字描述、图片描述中可能有侵权内容. 特别是跨境电商, 在一些国家侵权查处非常严厉. 注册公司名、产品名时可能侵权. 在写文章时, 文章的文字内容、视频内容、图片内容中的描述可能侵权. 例如postgresql是个商标, 如果你使用posthellogresql、postgresqlabc也可能算侵权. 以跨境电商为力, 为了避免侵权, 在发布内容时需要商品描述中出现的品牌名、产品名等是否与已有的商标库有相似. 对于跨境电商场景, 由于店铺和用户众多, 商品的修改、发布是比较高频的操作, 所以需要实现高性能的字符串相似匹配功能. -
08.24 17:41:50发表了文章
2023-08-24 17:41:50
沉浸式学习PostgreSQL|PolarDB 3: 营销场景, 根据用户画像的相似度进行目标人群圈选, 实现精准营销
业务场景1 介绍: 营销场景, 根据用户画像的相似度进行目标人群圈选, 实现精准营销 在营销场景中, 通常会对用户的属性、行为等数据进行统计分析, 生成用户的标签, 也就是常说的用户画像. 标签举例: 男性、女性、年轻人、大学生、90后、司机、白领、健身达人、博士、技术达人、科技产品爱好者、2胎妈妈、老师、浙江省、15天内逛过手机电商店铺、... ... 有了用户画像, 在营销场景中一个重要的营销手段是根据条件选中目标人群, 进行精准营销. 例如圈选出包含这些标签的人群: 白领、科技产品爱好者、浙江省、技术达人、15天内逛过手机电商店铺 . -
08.22 18:01:10发表了文章
2023-08-22 18:01:10
沉浸式学习PostgreSQL|PolarDB 2: 电商高并发秒杀业务、跨境电商高并发队列消费业务
业务场景介绍: 高并发秒杀业务 秒杀业务在电商中最为常见, 可以抽象成热点记录(行)的高并发更新. 而通常在数据库中最细粒度的锁是行锁, 所以热门商品将会被大量会话涌入, 出现锁等待, 甚至把数据库的会话占满, 导致其他请求无法获得连接产生业务故障. 业务场景介绍: 高并发队列消费业务 在跨境电商业务中可能涉及这样的场景, 由于有上下游产业链的存在, 1、用户下单后, 上下游厂商会在自己系统中生成一笔订单记录并反馈给对方, 2、在收到反馈订单后, 本地会先缓存反馈的订单记录队列, 3、然后后台再从缓存取出订单并进行处理. -
08.21 18:07:37发表了文章
2023-08-21 18:07:37
沉浸式学习PostgreSQL|PolarDB 1: 短视频推荐去重、UV统计分析场景
本实验场景:短视频推荐去重、UV统计分析场景. 欢迎一起来建设数据库沉浸式学习教学素材库, 帮助开发者用好数据库, 提升开发者竞争力, 为企业降本提效. 本文的实验可以使用永久免费的云起实验室来完成. https://developer.aliyun.com/adc/scenario/exp/f55dbfac77c0467a9d3cd95ff6697a31 如果你本地有docker环境也可以把镜像拉到本地来做实验. -
08.05 10:30:04发表了文章
2023-08-05 10:30:04
PolarDB | PostgreSQL 高并发队列处理业务的数据库性能优化实践
在电商业务中可能涉及这样的场景, 由于有上下游关系的存在, 1、用户下单后, 上下游厂商会在自己系统中生成一笔订单记录并反馈给对方, 2、在收到反馈订单后, 本地会先缓存反馈的订单记录队列, 3、然后后台再从缓存取出订单并进行处理. 如果是高并发的处理, 因为大家都按一个顺序获取, 容易产生热点, 可能遇到取出队列遇到锁冲突瓶颈、IO扫描浪费、CPU计算浪费的瓶颈. 以及在清除已处理订单后, 索引版本未及时清理导致的回表版本判断带来的IO浪费和CPU运算浪费瓶颈等. 本文将给出“队列处理业务的数据库性能优化”优化方法和demo演示. 性能提升10到20倍.
2023年07月
-
07.26 11:06:58发表了文章
2023-07-26 11:06:58
用PolarDB|PostgreSQL提升通用ai机器人在专业领域的精准度
chatgpt这类通用机器人在专业领域的回答可能不是那么精准, 原因有可能是通用机器人在专业领域的语料库学习有限, 或者是没有经过专业领域的正反馈训练. 为了提升通用机器人在专业领域的回答精准度, 可以输入更多专业领域相似内容作为prompt来提升通用ai机器人在专业领域的精准度. PolarDB | PostgreSQL 开源数据库在与openai结合的过程中起到的核心作用是: 基于向量插件的向量类型、向量索引、向量相似搜索操作符, 加速相似内容的搜索. 通过“问题和正确答案”作为参考输入, 修正openapi在专业领域的回答精准度.
2023年03月
-
03.16 16:34:16
 回答了问题
2023-03-16 16:34:16
回答了问题
2023-03-16 16:34:16
开发者参与开源软件项目有哪些好处?
赞1 踩0 评论0 -
03.08 18:13:34发表了文章
2023-03-08 18:13:34
PolarDB-PG | PostgreSQL + 阿里云OSS 实现高效低价的海量数据冷热存储分离
数据库里的历史数据越来越多, 占用空间大, 备份慢, 恢复慢, 查询少但是很费钱, 迁移慢 怎么办? 冷热分离方案: - 使用PostgreSQL 或者 PolarDB-PG 存成parquet文件格式, 放到aliyun OSS存储里面. 使用duckdb_fdw对parquet文件进行查询. - duckdb 存储元数据(parquet 映射) 方案特点: - 内网oss不收取网络费用, 只收取存储费用, 非常便宜 - oss分几个档, 可以根据性能需求选择 - parquet为列存储, 一般历史数据的分析需求多,性能不错 - duckdb 支持 parquet下推过滤, 数据过滤性能不错
2023年01月
-
01.30 17:46:08发表了文章
2023-01-30 17:46:08
手把手教你如何参与开源项目的协作、贡献代码: 以PolarDB开源项目为例
开源协作是一种社会进化的体现吗? 昨天体验了一下ChatGPT, 对这几个回答深有感触, 开源协作一定是未来会长期存在的, 更大规模化的人类协作模式. 所以我想写一点东西, 来帮助更多人参与开源协作.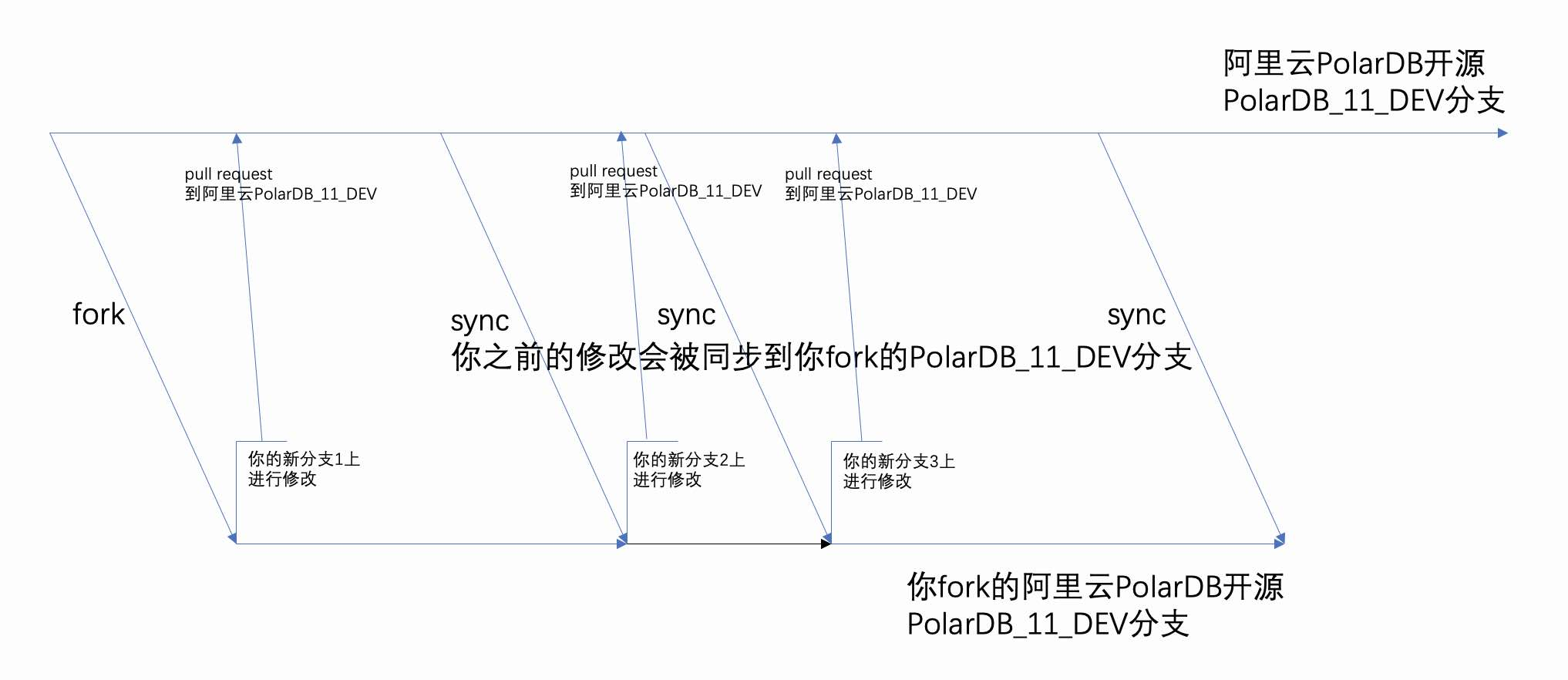
-
01.05 12:26:50发表了文章
2023-01-05 12:26:50
PolarDB 开源版 使用TimescaleDB 实现时序数据高速写入、压缩、实时聚合计算、自动老化等
PolarDB 开源版 使用TimescaleDB 实现时序数据高速写入、压缩、实时聚合计算、自动老化等 -
01.05 12:25:45发表了文章
2023-01-05 12:25:45
PolarDB 开源版 使用PostGIS 数据寻龙点穴(空间聚集分析)- 大数据与GIS分析解决线下店铺选址问题
寻龙点穴是风水学术语。古人说:三年寻龙,十年点穴。意思就是说,学会寻龙脉要很长的时间,但要懂得点穴,并且点得准则难上加难,甚至须要用“十年”时间。 但是,若没正确方法,就是用百年时间,也不能够点中风水穴心聚气的真点,这样一来,寻龙的功夫也白费了。 准确地点正穴心,并不是一件容易的事,对初学者来说如此,就是久年经验老手,也常常点错点偏。 寻龙点穴旨在寻找龙气聚集之地,而现实中,我们也有类似需求,比如找的可能是人气聚集之地。 PolarDB 开源版 使用PostGIS 数据寻龙点穴(空间聚集分析)- 大数据与GIS分析解决线下店铺选址问题
-
01.04 16:46:38发表了文章
2023-01-04 16:46:38
PolarDB 开源版 使用PostGIS 以及泰森多边形 解决 "零售、配送、综合体、教培、连锁店等经营"|"通信行业基站建设功率和指向" 的地理最优解问题
1、以KFC为例, 全国有很多家KFC连锁店, 每个店应该辐射哪些小区商圈? 开了新店之后, 与之相邻的老店辐射商圈应该怎么调整? KFC需要根据辐射小区商圈来预定销量、配置食材、配置多大的门店、多少营业员? 2、配送业务, 根据网点分布, 如何合理化每个网点负责的片区, 使得配送效率最高, 成本最低? 每一个写字楼有且只有一种选择到某个网点的距离最近. 3、基站建设, 每个基站应该对每个方向的功率调多大, 才能整体最优的解决网络质量和覆盖率问题. 以上其实都在回答一个问题: - 在有限的资源情况下, 如何整体最优的解决地理位置上的业务覆盖问题.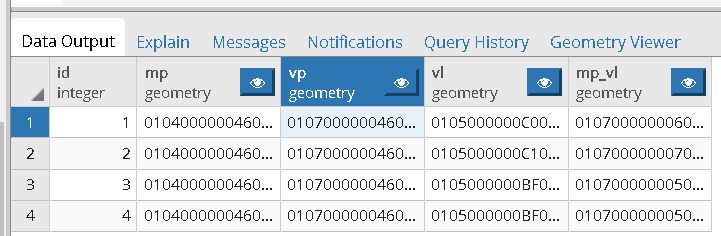
-
01.03 10:44:40发表了文章
2023-01-03 10:44:40
PolarDB 开源版 使用pgpool-II实现透明读写分离
PolarDB 开源版 使用pgpool-II实现透明读写分离. pgpool-II是PostgreSQL读写分离中间件, 由于PolarDB是计算存储分离架构, 和aws aurora一样, 只需要配置pgpool的负载均衡, 不需要配置它ha功能. ha功能建议采用polardb开源生态产品, 例如乘数科技的集群管理软件, 配置pgpool时使用rw, ro节点对应的vip即可(vip由乘数的集群管理软件来管理).
2022年12月
-
12.29 16:54:29发表了文章
2022-12-29 16:54:29
PolarDB 开源生态插件心选 - 这些插件让业务战斗力提升100倍!!!
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版插件生态, 通过插件给数据库加装新的算法和索引|存储结构, 结合PolarDB的大规模存储管理能力, 实现算法和存储双剑合璧, 是企业在数据驱动时代的决胜利器. -
12.29 16:53:35发表了文章
2022-12-29 16:53:35
PolarDB 开源版 轨迹应用实践 - 出行、配送、快递等业务的调度; 传染溯源; 刑侦
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版 轨迹应用实践, 例如: - 出行、配送、快递等业务的调度 - 快递员有预规划的配送轨迹(轨迹) - 客户有发货需求(时间、位置) - 根据轨迹估算最近的位置和时间 - 通过多个嫌疑人的轨迹, 计算嫌疑人接触的地点、时间点 -
12.29 16:51:06发表了文章
2022-12-29 16:51:06
PolarDB 开源版 通过rdkit 支撑生物、化学分子结构数据存储与计算、分析
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版 通过rdkit 支撑生物、化学分子结构数据存储与计算、分析 -
12.29 16:49:49发表了文章
2022-12-29 16:49:49
PolarDB 开源版 通过pgpointcloud 实现高效孪生数据存储和管理 - 支撑工厂、农业等现实世界数字化|数字孪生, 元宇宙相关业务的虚拟现实结合
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版 通过 pgpointcloud 实现高效孪生数据存储和管理 - 支撑工厂、农业等现实世界数字化|数字孪生, 元宇宙相关业务的虚拟现实结合 -
12.29 16:48:42发表了文章
2022-12-29 16:48:42
使用 PolarDB 开源版 部署 pgpointcloud 支撑激光点云数据的高速存储、压缩、高效精确提取
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 部署 pgpointcloud 支撑激光点云数据的高速存储、压缩、高效精确提取 -
12.29 16:47:23发表了文章
2022-12-29 16:47:23
使用 PolarDB 开源版 部署 pgrouting 支撑出行、快递、配送等商旅问题的路径规划业务
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 部署 pgrouting 支撑出行、快递、配送等商旅问题的路径规划业务 -
12.29 16:46:09发表了文章
2022-12-29 16:46:09
使用 PolarDB 开源版 部署 PostGIS 支撑时空轨迹|地理信息|路由等业务
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 部署 PostGIS 支撑时空轨迹|地理信息|路由等业务
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课18 通过pg_bulkload适配pfs实现批量导入提速
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课17 集成数据湖功能
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课16 接入PostGIS全功能及应用举例
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课15 集成DeepSeek等大模型
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课14 纯享单机版
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课13 单机版转换为集群版
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课12 集群版转换为单机版
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课11 激活容灾(Standby)节点
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课9 读写分离
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课10 计算节点全毁, 灾难恢复
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课8 任意时间点恢复(PITR)
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课7 实时流式归档
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课6 在线归档
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课5 在线备份
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课4 计算节点 Switchover
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课3 共享存储在线扩容
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课1 搭建共享存储集群
-
发表了文章
2025-02-21
PolarDB开源数据库进阶课2 创建容灾(standby)节点
-
发表了文章
2025-02-10
PolarDB 开源基础教程系列 9 开源社区合作和共建
-
发表了文章
2025-02-10
PolarDB 开源基础教程系列 8 数据库生态
滑动查看更多
-
回答了问题
2023-03-16
开发者参与开源软件项目有哪些好处?
1、使用开源项目, 帮助公司节省软件费用. 2、参与开源项目的社区活动, 了解前沿技术, 与社区专家建立连接, 提升职场人脉. 3、贡献开源项目, 提升自我技术能力, 如果这是个流行或者头部企业开源的重点开源项目, 通过贡献开源成就开源项目的同时, 自身的技术影响力也能得到飞跃成长. 提升职场竞争力. Linus Torvalds:Linux 操作系统的发明人和主要维护者,通过开源项目成为了世界上最有名的程序员之一。 Eric Raymond:自由软件运动的倡导者,主要贡献了众多的开源项目,如 Fetchmail、GNU Emacs 等。 Chris Wanstrath:GitHub 创始人之一,是 Ruby on Rails 开源项目的贡献者和核心开发者。 Jeremy Ashkenas:Backbone.js 框架的创建者,也是 CoffeeScript语言的创建者和 Backbone.js 开源项目的核心开发者。 总之,开发者参与开源项目可以获得很多好处,如提高个人技能、可见度和人际关系,同时也可以为未来的就业创造机会。通过开源项目,很多开发者也成为了知名的程序员和技术领袖。赞1 踩0 评论0 -
回答了问题
2019-07-17
PostgreSQL的高级SQL用法
https://github.com/digoal/blog/blob/master/201802/20180226_05.md 高级用法(《PostgreSQL SELECT 的高级用法(CTE, LATERAL, ORDINALITY, WINDOW, SKIP LOCKED, DISTINCT, GROUPING SETS, ...) - 珍藏级》)赞1 踩0 评论0 -
回答了问题
2019-07-17
PostgreSQL是否在PDB CDB方面进行了部分开发?是哪部分涉及了
https://github.com/digoal/blog/blob/master/201605/20160510_01.mdPG 除了不支持database级的wal,其他都比较完备了。赞0 踩0 评论0 -
回答了问题
2019-07-17
运行web工程报postgresql错误ERROR: permission denied to create extension "uuid-ossp"
你需要使用数据库超级用户创建EXTENSION;赞0 踩0 评论0 -
回答了问题
2019-07-17
PHP页面有一个浏览量统计每秒有200并发,造成insert给mysql造成很大压力
可以考虑PostgreSQLhttps://github.com/digoal/blog/blob/master/201711/readme.md赞0 踩0 评论0 -
回答了问题
2019-07-17
cmax,cmin在会话中更新数据后,变为0
cmin, cmax代表的是这条记录在一个事务中的第几条SQL被写入或更新赞1 踩1 评论0 -
回答了问题
2019-07-17
机器学习如何使用 阿里的myql 数据库
使用jdbc接口或者其他的应用开发接口。你也可以使用PostgreSQL赞0 踩0 评论0 -
回答了问题
2019-07-17
云服务器是否支持 Oracle 数据库?
你可以使用阿里云的RDS FOR PPAS数据库,高度兼容ORACLE的SQL语法和存储过程语法。甚至在某些方面性能超越了ORACLE。赞0 踩0 评论0 -
回答了问题
2019-07-17
云服务器上是否可以搭建数据库?
可以,但是你需要将整个数据库的生命周期管理起来。https://github.com/digoal/blog/blob/master/201711/20171125_01.md赞0 踩0 评论0 -
回答了问题
2019-07-17
elasticsearch5.6.4如何导入MySQL数据库
如果你需要使用搜索服务,可以考虑用RDS FOR POSTGRESQL,支持全文检索、模糊查询、相似查询、正则查询等功能。亿级别数据量,毫秒级响应。赞0 踩0 评论0 -
回答了问题
2019-07-17
关于大数据认证学习
https://github.com/digoal/blog/blob/master/201706/20170601_02.md你可以参考一下赞0 踩0 评论0 -
回答了问题
2019-07-17
您好,咨询一个问题:关于数据库或者产品选型的问题
推荐你使用HybridDB for PostgreSQL,或 rds pgsql,都支持直接读写OSS,通过OSS 外部表。阿里内部今年双十一也使用了RDG PGSQL和HDB PG。https://github.com/digoal/blog/blob/master/201706/20170601_02.mdhttps://github.com/digoal/blog/blob/master/201711/20171111_01.md赞0 踩0 评论0 -
回答了问题
2019-07-17
一个关于乐观锁的问题
秒杀例子,30万 tpshttps://github.com/digoal/blog/blob/master/201711/20171107_31.mdskip locked row例子https://github.com/digoal/blog/blob/master/201610/20161018_01.md赞0 踩0 评论0 -
回答了问题
2019-07-17
Postgres数据库文件在linux主机被删除后如何恢复
恢复手段优先级:1、如果有增量备份,建议从增量备份+归档文件进行时间点恢复。2、如果没有增量备份,建议使用dump文件逻辑恢复,恢复到某个备份的时间点。3、如果以上都没有,可以从文件系统层恢复,如果文件是在数据库停库状态下被删的,恢复后建议先备份一下数据文件。然后使用VACUUM 检查一下全库。3.1 如果文件是在数据库启动状态下被删,数据库处于不一致状态,或者数据文件没有完全恢复时,需要reset control file才能启动数据库。3.2 如果数据文件恢复程度不足以启动数据库,那么可以使用pg filedump,从仅有的数据文件中导出数据内容,并进行人为的恢复。赞0 踩0 评论0 -
回答了问题
2019-07-17
pipelinedb 安装时是否可选用已有postgresql库?
不可,暂时还没有插件化。赞0 踩0 评论0 -
回答了问题
2019-07-17
PG10支持建立默认分区表吗?
不支持,PG 11支持https://www.postgresql.org/docs/devel/static/sql-createtable.html如果你需要在PG 10支持这个语法,可以用insert on conflict插入,在遇到报错时do update,然后再目标表添加update rule,将update转成insert到default table。赞1 踩0 评论0 -
回答了问题
2019-07-17
postgresql内存一直增长,两个session占用150G内存
请参考:https://github.com/digoal/blog/blob/master/201607/20160709_01.md赞0 踩0 评论0 -
回答了问题
2019-07-17
oracle与postgresql数据存储过程的转换
例子 https://www.postgresql.org/docs/10/static/plpgsql-porting.html 或者你可以使用 阿里云RDS for PPAS产品,高度兼容Oracle大多数plsql函数不需要转换赞0 踩0 评论0 -
回答了问题
2019-07-17
如何调查解决postgresql死锁问题
不需要,这个是事务锁。你需要排查的是业务逻辑。这个文章对你会有帮助https://github.com/digoal/blog/blob/master/201705/20170521_01.md赞0 踩0 评论0 -
回答了问题
2019-07-17
安装imgsmlr 插件失败
你需要先编译安装imgsmlr插件。赞0 踩0 评论0
滑动查看更多
-
 我用PolarDB验证了“股神”巴菲特的投资理念!发布时间:2022-09-23 10:32:14 视频时长:15分38秒 播放量:21854巴菲特的投资理念是什么? 长线定投, 长线定投的理论支撑是什么?长期定投不是投机倒靶, 长期定投是有社会价值的, 可以帮助上市公司筹集资金, 加大研发投入和生产. 投资人则在这中间获取企业业务发展带来的红利.长线定投赚钱背后的逻辑(理论依据)是什么呢?1、首先是代际转移理论: 资源(生产资料、生产力)有限, 但是我们整个社区都假设并坚信通过未来的科技进步将获得更高的资源利用能力、生产效率; 例如石油、煤炭的过度开采虽然会造成环境破坏, 但是我们相信未来的科技进步会找到新的能源, 并填补过度开采造成的破坏. (这点和递弱代偿理论异曲同工)。2、第二个是经济周期, 以及宏观调控手段, 维持适度的通胀, 有利于经济的发展. 需要刺激经济的时候通常会有降低商业银行在央行的存款准备金率, 让商业银行可以贷出去更多钱, 可能引起通胀. (货币总量增加. 参考阅读:金融简史.). 但是有些国计民生相关商品并不是完全市场化的, 所以这些商品通胀率比较可控, 否则会引发动乱.银行放水时也需要有法律法规和相关监管配合, 防止投机倒把贷一堆钱去炒作钱滚钱. 失去了放水的意义. 放水可能希望的是去消费、投入研发或采购生产资料、促进生产....3、第三是数学支撑: 微笑曲线参考 《德说-第56期, 微笑曲线 - 基金定投》4、严格的止盈线. 可不要太贪, 过了止盈线就卖掉, 重新开始定投.5、不要过于分散, 例如就选一个投资对象(例如50, 500指数), 而且你的钱要能cover这只对象的整微笑周期.有了理论支撑, 我将使用真实数据以及PolarDB来证明巴菲特的投资理念.
我用PolarDB验证了“股神”巴菲特的投资理念!发布时间:2022-09-23 10:32:14 视频时长:15分38秒 播放量:21854巴菲特的投资理念是什么? 长线定投, 长线定投的理论支撑是什么?长期定投不是投机倒靶, 长期定投是有社会价值的, 可以帮助上市公司筹集资金, 加大研发投入和生产. 投资人则在这中间获取企业业务发展带来的红利.长线定投赚钱背后的逻辑(理论依据)是什么呢?1、首先是代际转移理论: 资源(生产资料、生产力)有限, 但是我们整个社区都假设并坚信通过未来的科技进步将获得更高的资源利用能力、生产效率; 例如石油、煤炭的过度开采虽然会造成环境破坏, 但是我们相信未来的科技进步会找到新的能源, 并填补过度开采造成的破坏. (这点和递弱代偿理论异曲同工)。2、第二个是经济周期, 以及宏观调控手段, 维持适度的通胀, 有利于经济的发展. 需要刺激经济的时候通常会有降低商业银行在央行的存款准备金率, 让商业银行可以贷出去更多钱, 可能引起通胀. (货币总量增加. 参考阅读:金融简史.). 但是有些国计民生相关商品并不是完全市场化的, 所以这些商品通胀率比较可控, 否则会引发动乱.银行放水时也需要有法律法规和相关监管配合, 防止投机倒把贷一堆钱去炒作钱滚钱. 失去了放水的意义. 放水可能希望的是去消费、投入研发或采购生产资料、促进生产....3、第三是数学支撑: 微笑曲线参考 《德说-第56期, 微笑曲线 - 基金定投》4、严格的止盈线. 可不要太贪, 过了止盈线就卖掉, 重新开始定投.5、不要过于分散, 例如就选一个投资对象(例如50, 500指数), 而且你的钱要能cover这只对象的整微笑周期.有了理论支撑, 我将使用真实数据以及PolarDB来证明巴菲特的投资理念. -
 PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率发布时间:2020-01-18 00:18:49 视频时长:88分51秒 播放量:2503MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率发布时间:2020-01-18 00:18:49 视频时长:88分51秒 播放量:2503MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率 -
PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询发布时间:2020-01-16 20:27:00 视频时长:45分48秒 播放量:3738MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等发布时间:2020-01-15 21:55:59 视频时长:33分58秒 播放量:2543MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第10课-任意字段维度组合搜索发布时间:2020-01-14 20:27:13 视频时长:52分54秒 播放量:5767MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)发布时间:2020-01-13 20:25:27 视频时长:47分22秒 播放量:2602MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第8课-PG时空GIS应用实践发布时间:2020-01-10 20:59:35 视频时长:54分51秒 播放量:1228MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第7课-PG并行计算发布时间:2020-01-09 21:00:49 视频时长:57分17秒 播放量:1345MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)发布时间:2020-01-08 23:03:10 视频时长:34分27秒 播放量:1323MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)发布时间:2020-01-07 20:12:27 视频时长:20分30秒 播放量:1521MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)发布时间:2020-01-06 20:44:20 视频时长:61分51秒 播放量:3774MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)发布时间:2020-01-03 20:42:46 视频时长:60分52秒 播放量:2177MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)发布时间:2019-12-31 23:07:06 视频时长:59分0秒 播放量:1172MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
-
PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明发布时间:2019-12-30 20:42:34 视频时长:45分32秒 播放量:3575MySQL是最流行的开源数据库,PG是最先进的开源数据库。 两者结合,发挥1+1大于2的超级效果,解决应用无法解决的问题。课程安排一期开课计划(MySQL结合PG使用,提升应用价值):PG+MySQL联合解决方案-第1课-PG介绍、联合应用场景说明PG+MySQL联合解决方案-第2课-PG连接(pgadmin,dms,psql)PG+MySQL联合解决方案-第3课-PG bench mark(压测,模拟测试,test case)PG+MySQL联合解决方案-第4课-PG与MySQL对比学习(面向开发者)PG+MySQL联合解决方案-第5课-MySQL同步到PG(采用DTS)PG+MySQL联合解决方案-第6课-PG外部表、归档存储、冷热分离应用(mysql_fdw,oss_fdw)PG+MySQL联合解决方案-第7课-PG并行计算PG+MySQL联合解决方案-第8课-PG时空GIS应用实践PG+MySQL联合解决方案-第9课-实时精准营销(精准圈选、相似扩选、用户画像)PG+MySQL联合解决方案-第10课-任意字段维度组合搜索PG+MySQL联合解决方案-第11课-多维向量相似搜索-图像识别等PG+MySQL联合解决方案-第12课-全文检索、中文分词、模糊查询、相似查询PG+MySQL联合解决方案-第13课-高级SQL学习-提升生产效率
滑动查看更多