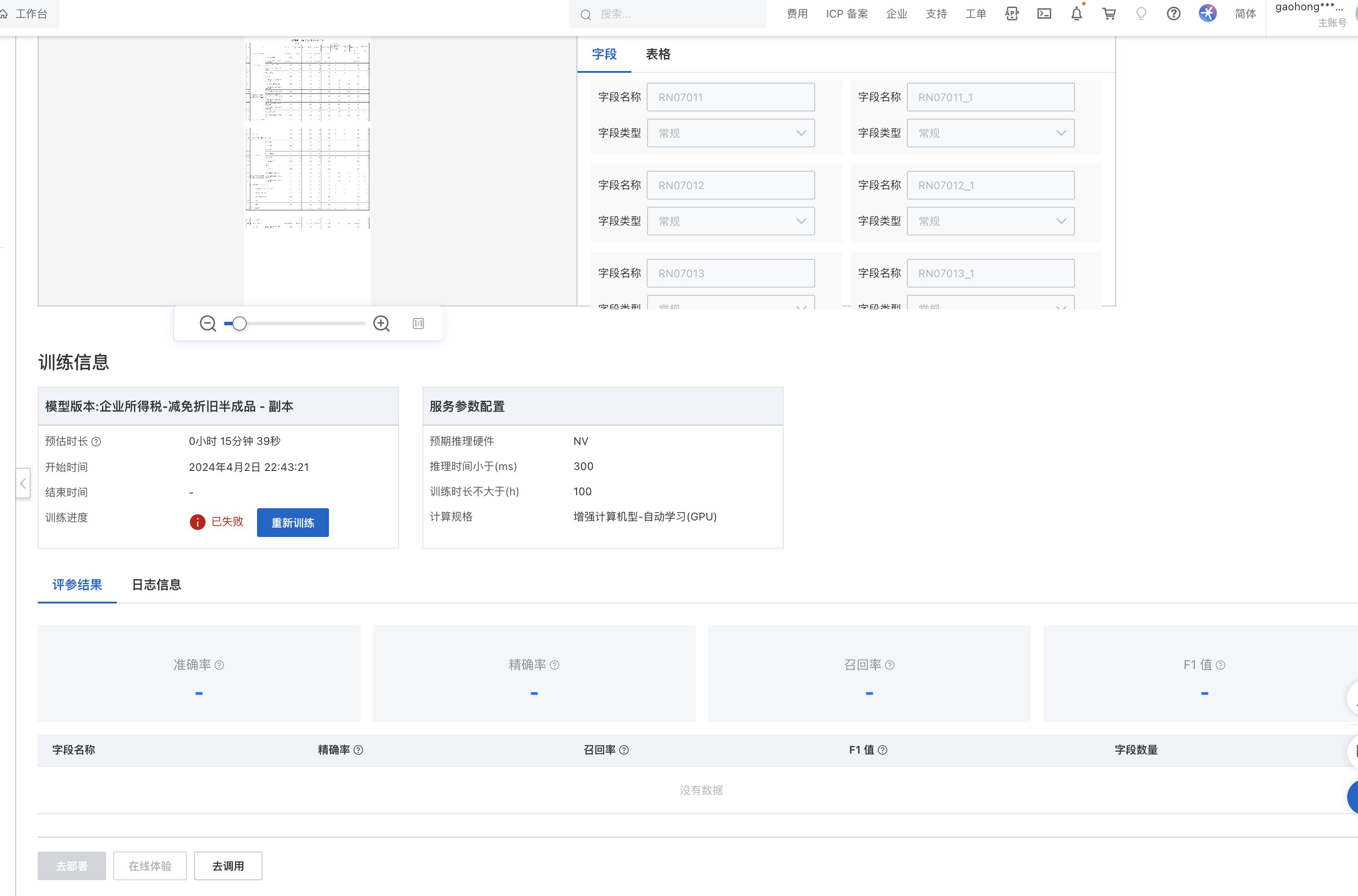
文字识别OCR模型训练失败可能由多种原因导致,以下是一些常见问题及解决方法,供您参考:
1. 检查数据集的完整性和质量
- 训练集和测试集的选择:确保训练集和测试集均为标注且质检完成的数据集,并且两者字段内容保持一致。如果字段不一致,可能导致模型无法正常训练。
- 数据量要求:
- 单据票证信息抽取建议至少20张有效数据进行训练,数据量越大效果越好,通常100+份数据会有较好的表现。
- 表格信息抽取同样建议至少20张有效数据,数据量越大,模型效果越优。
- 长文档信息抽取建议选择20张以上有效数据,数据量达到200+份时效果更佳。
- 数据标注质量:确保标注框贴合字段文字,避免漏标或错标。标注越精确,模型训练效果越好。
2. 确认字段配置是否正确
- 在「模型训练」配置环节,检查字段类型是否与业务需求匹配。删除不必要的字段或调整字段类型,可以提高训练精准度。
- 如果使用了「题目库」功能,请确保题目库中的字段定义与当前任务需求一致。修改题目库不会影响已发起的标注任务或模型,但需要重新创建新的标注任务以应用更改。
3. 检查机器资源和训练时长
- 模型训练时长受数据量、标注情况和机器资源等多种因素影响。例如:
- 单据票证信息抽取:20张图片约需1.5小时,200张图片约需3小时(基于V100机器)。
- 表格信息抽取:20张图片约需1小时,200张图片约需2小时(基于V100机器)。
- 长文档信息抽取:6万字数约需1分钟(基于V100机器)。
- 如果训练时间过长或失败,可能是由于机器资源不足或数据量过大导致。建议分批次处理数据或联系技术支持获取更多资源。
4. 算法评估与调优
- 整体指标:包括准确率、精确率、召回率和F1值。如果模型训练失败,可能是由于这些指标未达到预期。可以通过增加数据量、优化标注质量或调整字段类型来提升模型效果。
- 字段指标:针对单字段的精确率、召回率和F1值进行分析,找出表现较差的字段并重点优化其标注和字段类型配置。
- 表格指标(仅适用于表格信息抽取):关注表格字段的精确率、召回率和F1值,确保表格结构化识别的准确性。
5. 排查接口参数问题
- 如果训练过程中出现类似
illegalCutType的错误,请检查是否传入了必要的CutType参数,确保入参的完整性。
- 其他参数错误也可能导致训练失败,请参考接口文档逐一核对参数设置。
6. 联系技术支持
- 如果经过上述排查仍无法解决问题,建议加入官方钉钉群联系技术支持团队:
- 【官方】阿里云OCR文档自学习用户答疑群:26560014923
- 【官方】阿里云OCR公共云客户交流群:35208328
- 【官方】阿里云文档智能客户交流群:44854217
重要提醒
- 资源包状态:确保已开通文字识别OCR后付费服务,并优先抵扣资源包。如果资源包耗尽或过期,服务将自动切换为后付费模式,可能导致账户余额不足而停机。
- 欠费处理:如因欠费导致停机,API调用将直接受到影响。请及时结清费用以恢复服务。
通过以上步骤,您可以逐步排查并解决OCR模型训练失败的问题。如果仍有疑问,请随时联系技术支持团队获取进一步帮助。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。