
modelscope-funasronline模型单卡finetune好像会有oom,有遇到过么?
modelscope-funasronline模型单卡finetune好像会有oom,大家有遇到这种情况么?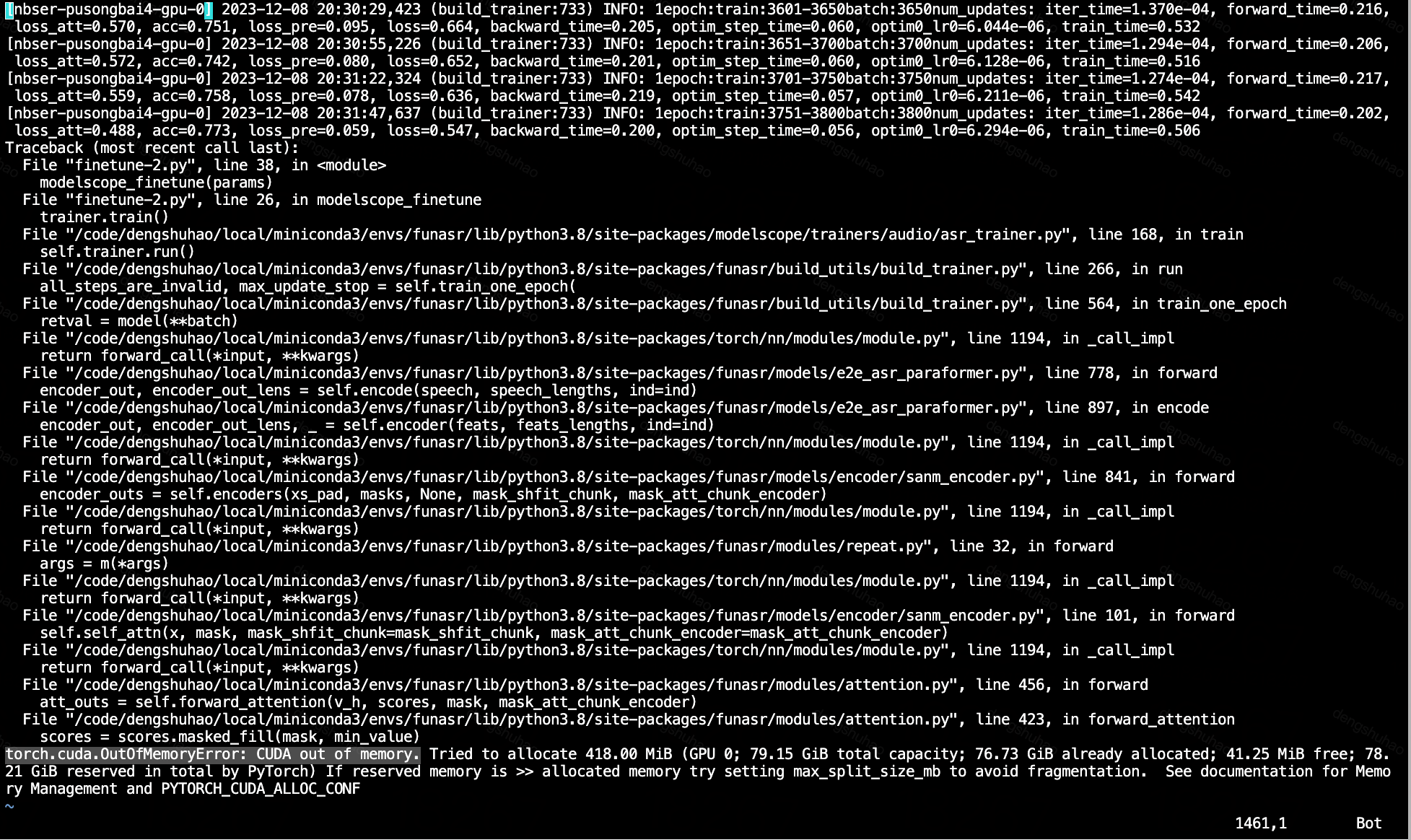
跑着跑着就torch.cuda.OutOfMemoryError: CUDA out of memory
展开
收起
阿里云 AI 助理回答
在使用ModelScope-FunASR的FunClip进行单卡微调(finetune)时,出现torch.cuda.OutOfMemoryError: CUDA out of memory的问题,通常是由于GPU显存不足导致的。以下是针对该问题的详细分析和解决方法:
1. 问题原因分析
- 显存不足:单卡微调时,模型参数、优化器状态、梯度缓存以及中间计算结果都会占用显存。如果数据量较大或模型较复杂,显存可能不足以支持整个训练过程。
- 未释放显存:在训练过程中,可能存在未及时释放显存的情况,例如未正确清理无用变量或未使用
torch.cuda.empty_cache()。 - Batch Size过大:较大的Batch Size会显著增加显存占用,尤其是在深度学习任务中。
2. 解决方案
2.1 调整Batch Size
- 降低Batch Size:减小每个批次的数据量可以有效减少显存占用。建议逐步尝试较小的Batch Size,直到显存能够容纳为止。
- 梯度累积:如果Batch Size过小影响了训练效果,可以通过梯度累积的方式模拟大Batch Size的效果。例如:
accumulation_steps = 4 # 梯度累积步数 optimizer.zero_grad() for i, data in enumerate(dataloader): outputs = model(data) loss = loss_fn(outputs, labels) loss = loss / accumulation_steps # 归一化损失 loss.backward() if (i + 1) % accumulation_steps == 0: optimizer.step() optimizer.zero_grad()
2.2 使用混合精度训练
-
启用AMP(Automatic Mixed Precision):通过混合精度训练,可以减少显存占用并加速训练。具体操作如下:
from torch.cuda.amp import GradScaler, autocast scaler = GradScaler() for data, labels in dataloader: optimizer.zero_grad() with autocast(): # 自动混合精度 outputs = model(data) loss = loss_fn(outputs, labels) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()- 注意:如果使用TorchAcc进行分布式训练,需确保在
scaler.unscale_之前调用xm.all_reduce。
- 注意:如果使用TorchAcc进行分布式训练,需确保在
2.3 显存优化
- 清理无用变量:在训练循环中,及时释放不再需要的变量,并调用
torch.cuda.empty_cache()清理显存。del variable_name torch.cuda.empty_cache() - 检查模型结构:确保模型中没有冗余的层或参数,避免不必要的显存占用。
2.4 分布式训练
- 如果单卡显存不足,可以考虑使用多卡分布式训练。通过
torch.distributed或TorchAcc进行分布式初始化:import torch.distributed as dist dist.init_process_group(backend='nccl', init_method='env://')- 说明:分布式训练可以将显存压力分摊到多个GPU上,但需要调整代码以支持多卡环境。
2.5 调整优化器
- 使用更高效的优化器,例如
syncfree optimizer,可以减少显存占用并提升训练速度:from torchacc.torch_xla.amp import syncfree optimizer = syncfree.AdamW(model.parameters(), lr=1e-3)
3. 其他注意事项
- 监控显存使用:使用
nvidia-smi命令实时监控显存占用情况,定位显存瓶颈。 - 升级硬件:如果上述方法仍无法解决问题,建议升级到显存更大的GPU设备。
- 拆分任务:对于特别大的模型或数据集,可以尝试将任务拆分为多个子任务分别训练。
4. 总结
通过调整Batch Size、启用混合精度训练、优化显存使用以及分布式训练等方法,可以有效缓解单卡微调时的显存不足问题。如果问题仍然存在,建议结合具体任务需求进一步优化模型结构或升级硬件配置。
希望以上解决方案能够帮助您解决问题!您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
有帮助
无帮助
AI 助理回答生成答案可能存在不准确,仅供参考
相关问答
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352
相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理