
请问ModelScope合成语音,200字要22秒,正常吗?能优化不?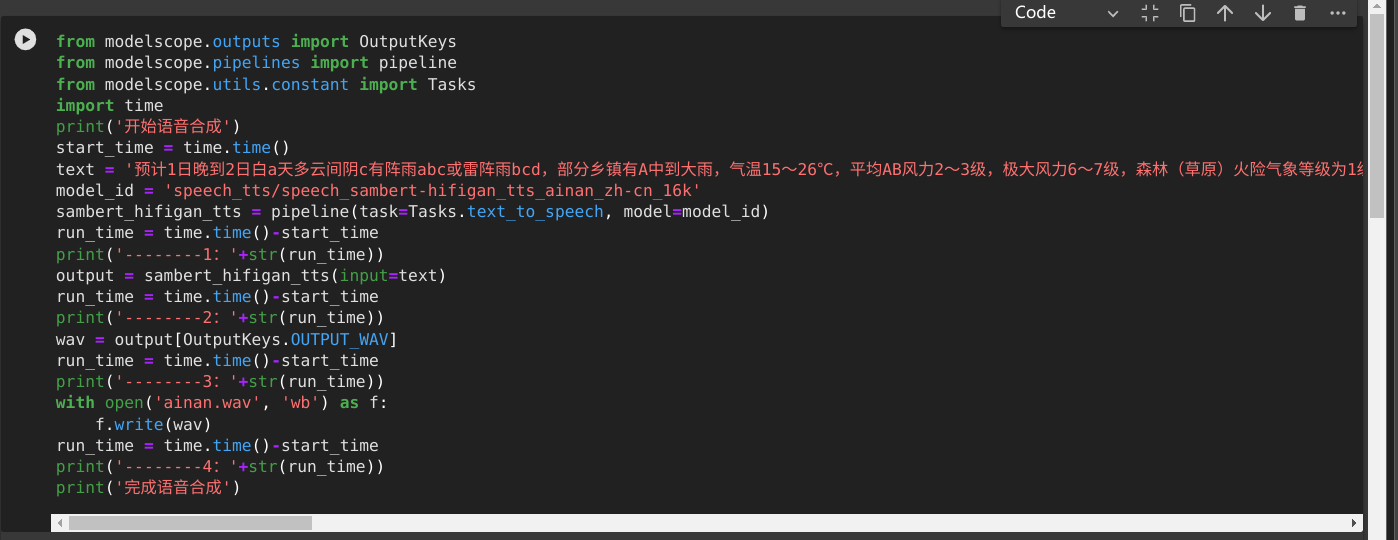
ModelScope的语音合成速度取决于多种因素,包括但不限于:
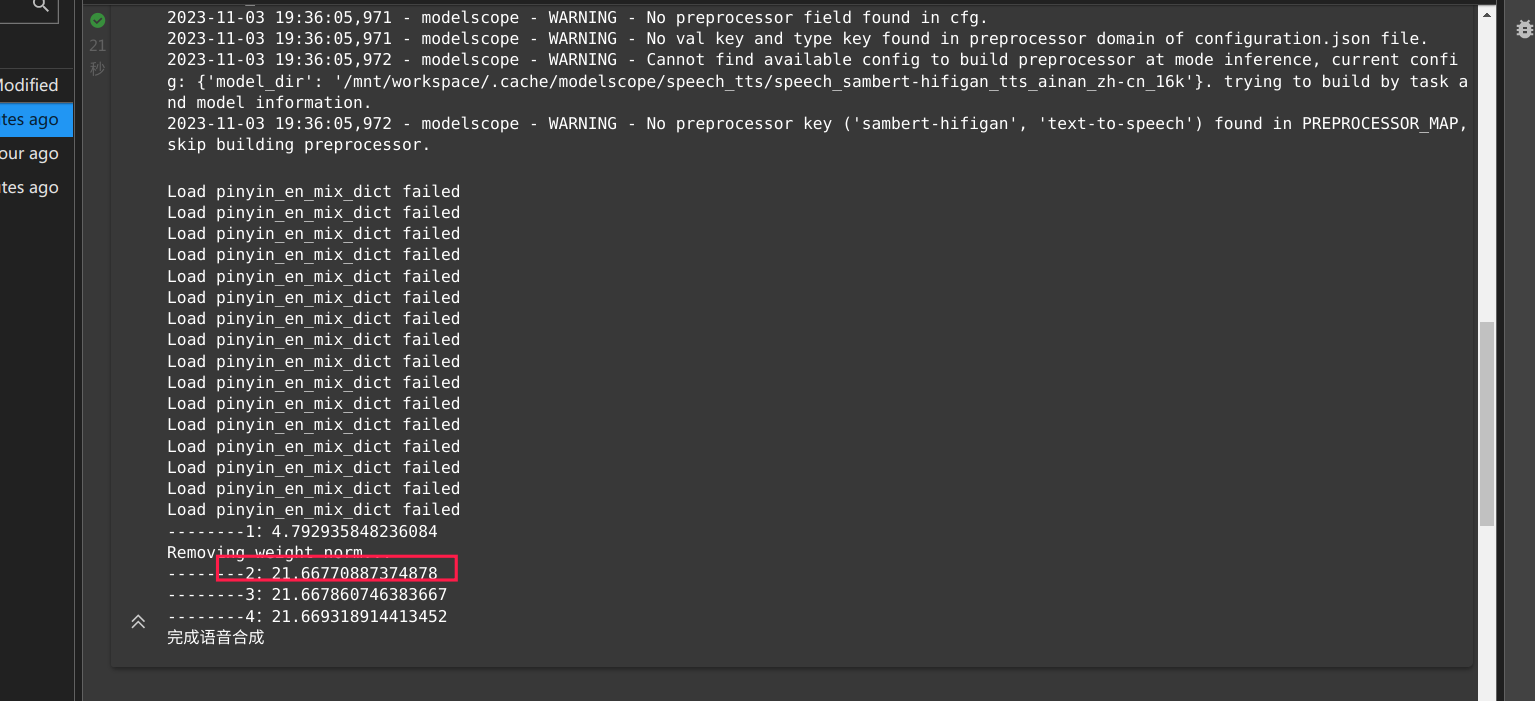
对于您提到的情况,如果使用ModelScope进行语音合成,将200字的文本转换为语音需要22秒,这似乎比预期要慢一些。通常情况下,合成时间应该在几秒钟内,而不是以分钟计算。以下是一些可能的优化方法:
利用GPU加速:
减少停顿时间:
并行化处理:
模型优化:
检查API调用方式:
代码优化:
联系ModelScope团队:
ModelScope合成语音的速度受多种因素影响,例如语音合成模型的大小、使用的推理设备以及推理的并发数等。因此,无法直接判断200字需要22秒是否正常。不过,达摩院已经开源了基于ModelScope的语音合成训练框架KAN-TTS和中文多人预训练模型,开发者可以使用这些工具在小规模数据集上定制自己的语音合成模型。此外,通过调用modelscope.trainers进行微调训练,可以优化pipeline推理速度,显著提升单条音频输入的推理速度。同时,这项语音合成技术背后是达摩院的显式韵律声学模型SAMBERT以及Hifi-GAN声码器的结合,它针对基频(pitch)、能量(energy)和时长(duration)三种韵律表征分别建模。如果你觉得语音合成的速度仍然不满意,可以尝试调整这些参数或者优化你的数据集以提高效果。

