
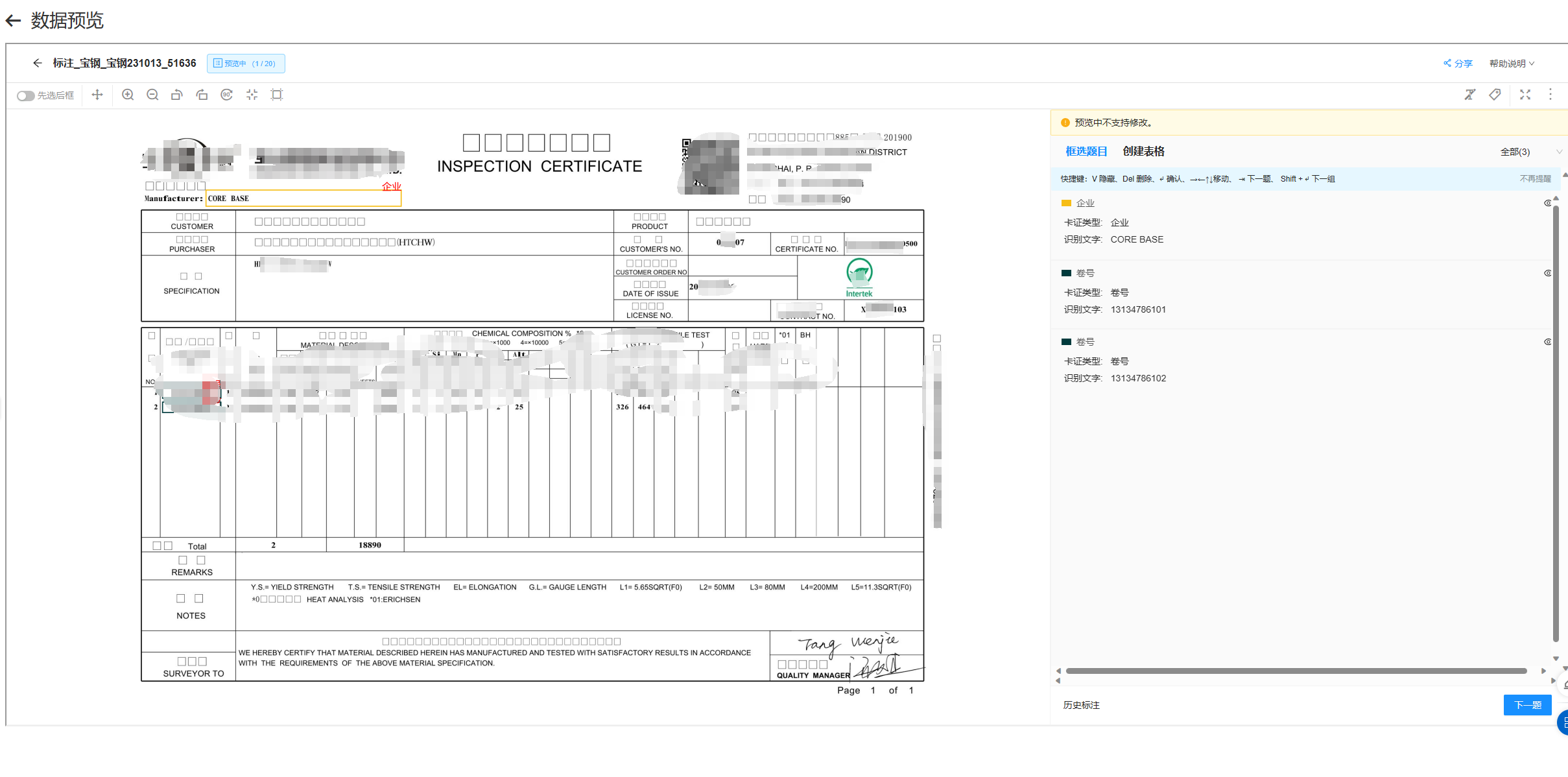
文字识别OCR有部份PDF无法识别出中文,看看技术有没有办法完善一下吧?
文字识别OCR有部份PDF无法识别出中文,看看技术有没有办法完善一下吧?

展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
3
条回答
写回答
-
从事java行业9年至今,热爱技术,热爱以博文记录日常工作,csdn博主,座右铭是:让技术不再枯燥,让每一位技术人爱上技术
您好,根据截图来看的话是您在进行pdf文件识别时部分文字识别不出来,识别为了框。目前OCR的文字识别包括万级常用汉字,以及相对常见的生僻字,若您出现生僻字识别不准确的情况,您可以直接通过钉钉群或者邮件的方式咨询技术,直接沟通可以帮助您快速定位问题
 2023-11-04 09:58:47赞同 1 展开评论
2023-11-04 09:58:47赞同 1 展开评论 -
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
很抱歉听到您的反馈。针对 PDF 文件中的中文字符无法识别的问题,我们建议您参考以下几个方面:
- 检查 PDF 文件质量:PDF 文件的质量可能会影响识别的效果。建议您检查文件是否清晰、无噪点和无破损。
- 检查 PDF 文件编码:确认 PDF 文件的编码是否正确,避免因编码不一致导致的识别错误。
- 使用自定义模板:您可以使用阿里云文字识别OCR的自定义模板功能,以适应特定场景的特殊字符识别需求。
2023-11-01 13:17:08赞同 展开评论 -
文字识别OCR技术在处理PDF文件时,有时可能无法正确识别出中文文本。这可能是由于多种原因导致的,例如PDF文件的质量、包含的文本类型和语言等。以下是一些可能有助于提高OCR技术在PDF中识别中文文本的方法:
- 预处理PDF文件:在进行OCR识别之前,先对PDF文件进行预处理,例如去噪、去阴影、旋转等操作,以改善图像质量,提高识别准确性。
- 选择合适的OCR引擎:不同的OCR引擎在处理不同类型和语言的文本时具有不同的优势和准确性。如果您的OCR引擎无法正确识别中文文本,可以尝试使用其他专门针对中文的OCR引擎,例如ABBYY FineReader、Adobe Acrobat等。
- 调整OCR参数:一些OCR软件允许用户调整参数,以优化识别效果。您可以尝试调整这些参数,例如字体、字号、字符间距等,以提高识别准确性。
- 手动校对:在OCR识别完成后,建议对识别结果进行手动校对和修正。这可以帮助您发现并纠正一些错误和不准确的识别结果。
- 训练OCR模型:一些OCR引擎允许用户训练模型,以提高识别准确性。如果您发现OCR引擎无法正确识别某些特定的中文文本,可以尝试使用训练功能,将这些文本作为训练数据提供给OCR引擎,以提高其对中文文本的识别能力。
总之,要提高文字识别OCR技术在PDF中识别中文文本的准确性,需要综合考虑多种因素和方法。您可以尝试以上提到的一些方法来改善OCR技术在处理PDF文件时的表现,并根据具体情况选择最适合您的解决方案。
2023-11-01 11:35:52赞同 展开评论

相关问答
