
文字识别OCR为什么跳到这里来了?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,单据票证信息抽取是基于深度学习的信息抽取自学习模型任务,可对版式相对固定的单据、证件、凭证等类型数据有较好的效果,具体看下图: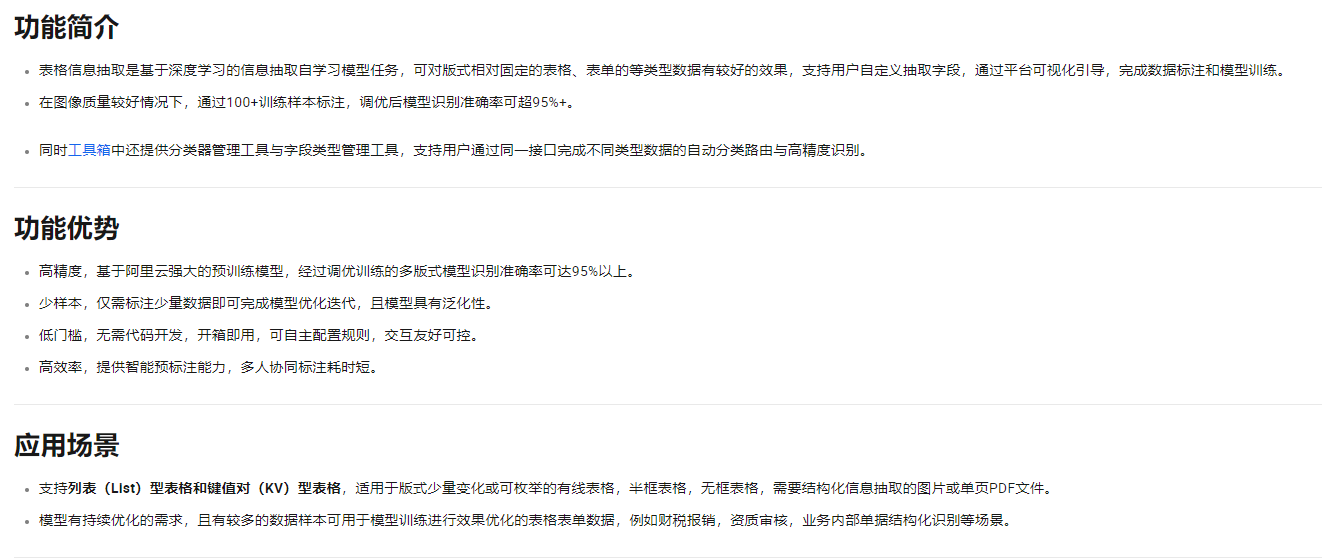
单据票证信息抽取(固定版式)是基于深度学习的信息抽取自学习模型任务,可对版式相对固定的单据、证件、凭证等类型数据有较好的效果,支持用户自定义抽取字段,通过平台可视化引导,完成数据标注和模型训练。
在图像质量较好情况下,通过100+训练样本标注,调优后模型识别准确率可超95%+。
同时工具箱中还提供分类器管理工具与字段类型管理工具,支持用户通过同一接口完成不同版式数据的自动分类路由与高精度识别。
数据标注划分为标注创建环节、标注环节、质检环节三大步骤;
标注任务创建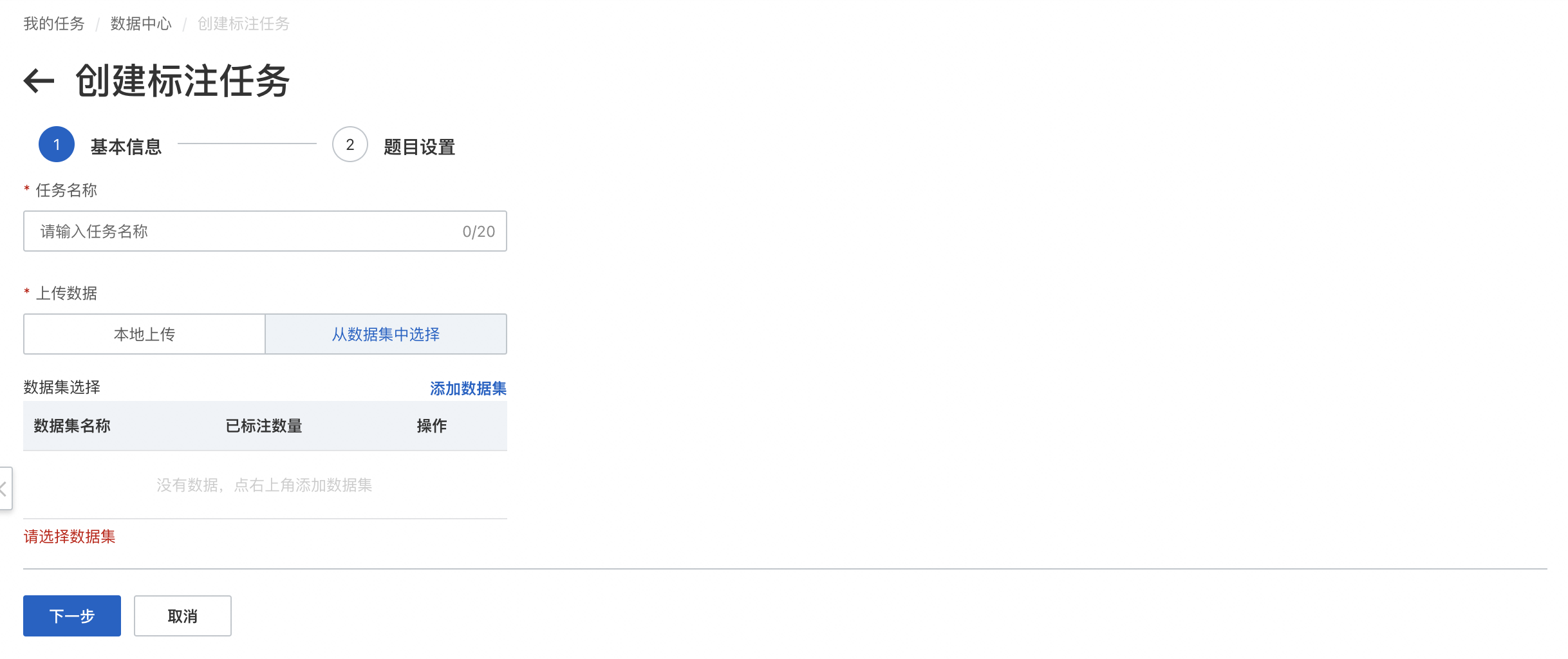
标注说明文档可以参考下这个文档哈https://help.aliyun.com/document_detail/479731.html?spm=a2c4g.601891.0.0.4863613eXEQfnp#986f838ea2nv4 此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”


