
文字识别OCR这里面后面的图片是自己手动一个个的弄吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,阿里云文字识别OCR中的图片可以是通过API上传的,也可以是通过手动上传的。如果您需要对图片进行处理,可以使用阿里云提供的SDK或API来集成OCR服务到您的应用程序中,实现自动化的图片文字识别。如果您需要手动上传图片,可以使用阿里云提供的控制台进行上传。
您好,文字识别OCR 文档自学习进入质检环节后您需要核验该任务所有图片以及其字段是否标注完善,若标注有误则需做更改或者「驳回」操作,若标注无误则点击「提交」完成质检工作。质检界面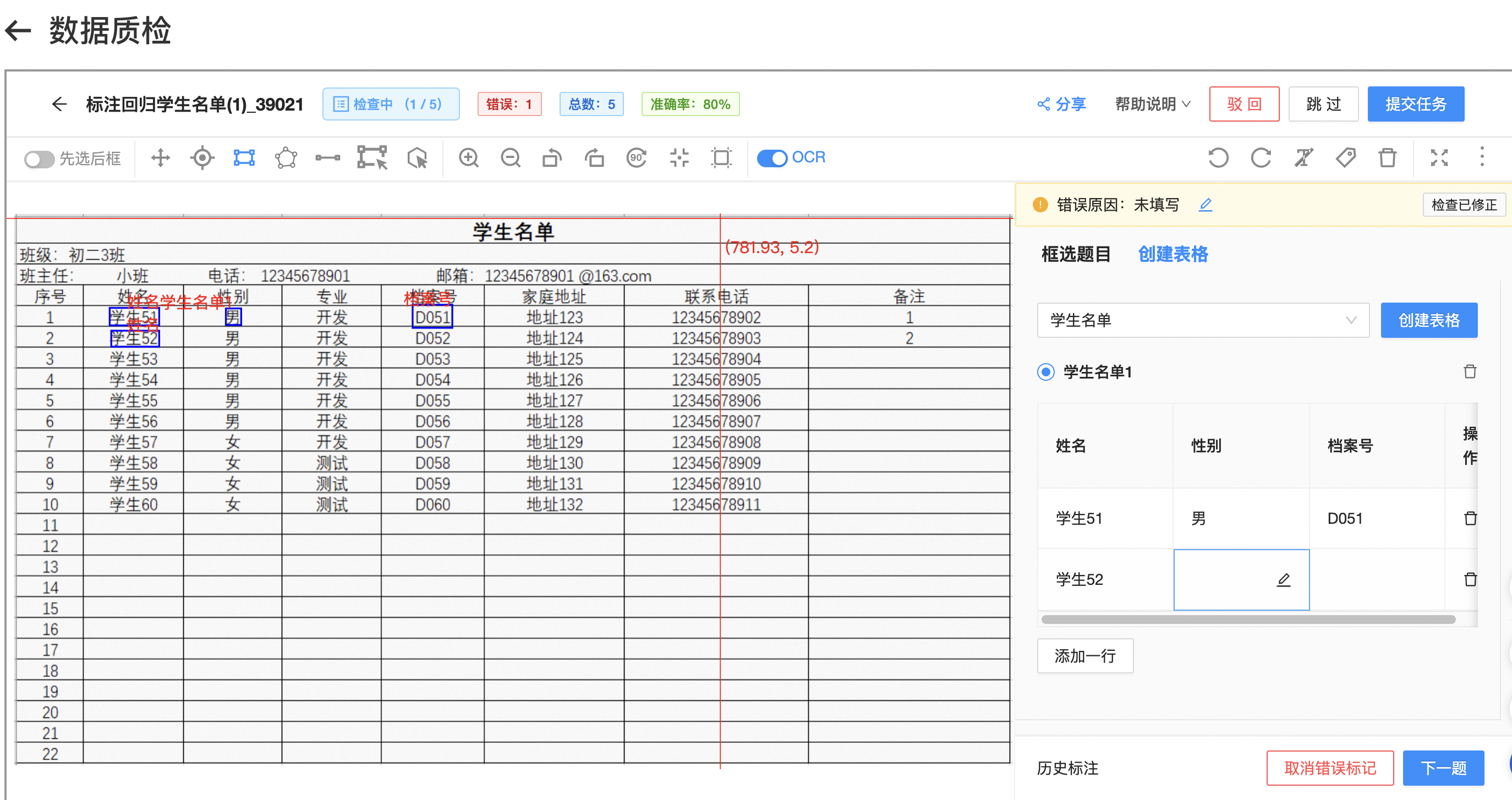
这个是需要人工逐个质检的,质检后的数据准确度更高,识别效果更好,训练之后的识别成功率会更好。
文字识别OCR技术通常需要输入图片数据进行识别,这些图片可以是从相机、扫描仪或者其他设备中获取的,也可以是从网络或本地存储中读取的。在实际应用中,图片的来源和获取方式可能因应用场景而异。
如果您需要对多张图片进行识别,可以通过编写程序或者调用文字识别OCR服务提供商提供的API来实现批量识别。例如,通过编写Python脚本调用百度OCR的API来实现批量识别:
python
Copy
import requests
import base64
url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic'
params = {'access_token': 'YOUR_ACCESS_TOKEN'}
with open('image.jpg', 'rb') as f:
img_data = f.read()
img_base64 = base64.b64encode(img_data).decode()
data = {'image': img_base64}
response = requests.post(url, params=params, data=data)
result = response.json()
print(result)
您好,1. 开通OCR服务前需进行实名认证,完成实名认证后,点击进入控制台选择开通所需的OCR产品服务。
选定服务类型后,勾选服务协议,点击【立即开通】,即可一键完成开通。
对于文字识别OCR,您需要提供待识别的图片作为输入。您可以手动准备这些图片,并将其上传到OCR服务进行处理。
通常情况下,您需要自己准备待识别的图片。这可以通过以下几种方式来实现:
手动拍摄:使用手机或相机拍摄待识别的文档、证件或图像,确保图像清晰可见,以提高识别的准确性。
扫描仪:使用扫描仪将纸质文档转换为数字形式,生成待识别的图像文件。
在线资源:在某些情况下,OCR服务可能支持从在线资源或URL加载图像进行识别。您可以提供图像的URL链接,使OCR服务能够直接访问和处理图像。


