
OCR表格返回的样式,请问应该修改哪个地方?这个我要返回!
OCR表格返回的样式,请问应该修改哪个地方?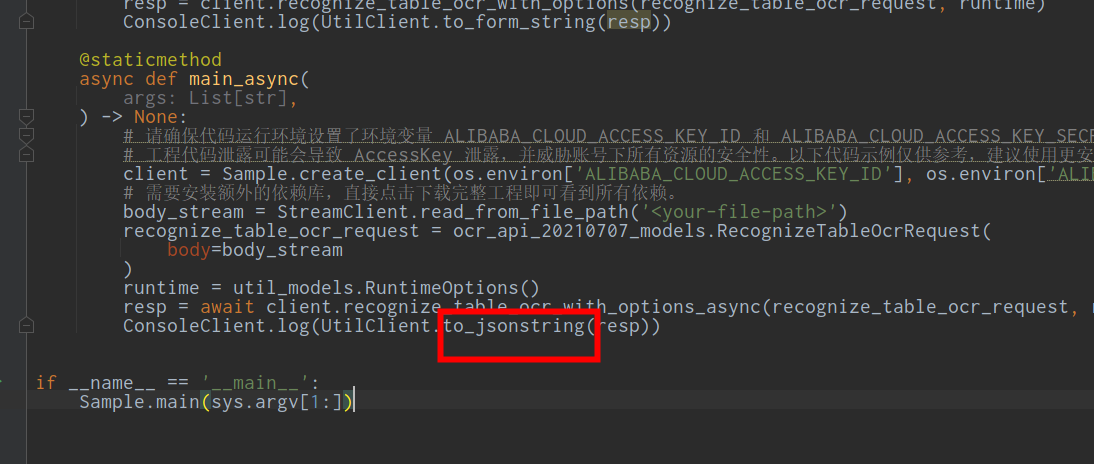 这个我要返回
这个我要返回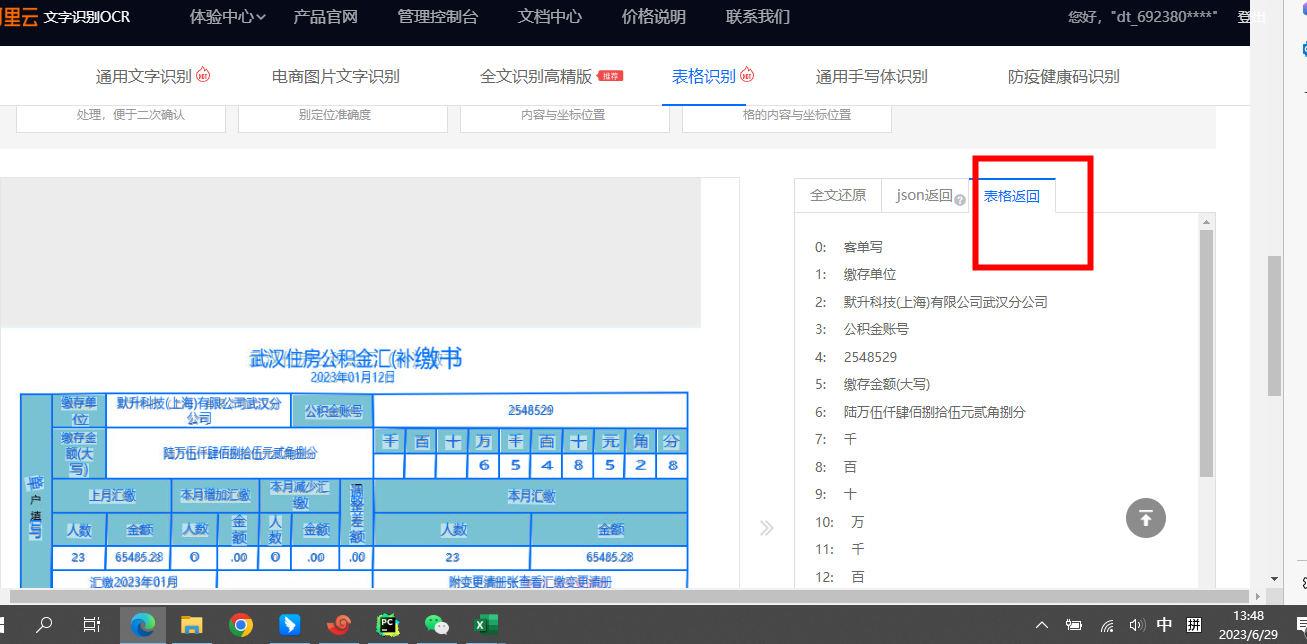
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
如果你想修改OCR表格返回的样式,通常需要在处理OCR结果后进行样式调整。以下是一些可能需要进行修改的地方:
表格布局:根据需要对表格的行列进行合并、拆分或调整。可以根据解析结果中识别到的数据进行适当的单元格合并或拆分,以改变表格的布局。
样式属性:调整表格的样式属性,如字体、字号、颜色、背景色等。这可以通过设置HTML、CSS或其他文档处理工具来实现。
边框和边距:添加或删除单元格之间的边框,调整单元格的边距和内外边距,以改变表格的边框样式和间距。
单元格内容格式:根据需要对单元格中的内容进行格式化,例如日期、货币、百分比等。可以使用相关的脚本或代码来处理解析得到的数据,并将其格式化为所需的样式。
2023-07-14 14:10:28赞同 展开评论 -
北京阿里云ACE会长
在混合票据 OCR 接口中,您可以使用参数 "outputFormat" 来指定返回的结果格式类型,其中包括 "excel"、"json" 和 "html" 等多种格式。如果您需要修改表格样式,可以尝试使用 "html" 格式,然后在 HTML 文件中进行样式的修改和调整。
除此之外,您还可以使用一些第三方的表格识别工具,例如 Tabula、Tesseract-OCR 等,这些工具也提供了一些表格样式调整和修改的功能,可以帮助您更好地满足识别需求。
2023-07-14 08:49:58赞同 展开评论 -
公众号:网络技术联盟站,InfoQ签约作者,阿里云社区签约作者,华为云 云享专家,BOSS直聘 创作王者,腾讯课堂创作领航员,博客+论坛:https://www.wljslmz.cn,工程师导航:https://www.wljslmz.com
阿里云OCR识别表格的返回样式,可以通过设置识别请求中的参数进行修改。具体来说,您可以在表格识别的请求参数中设置
output_word_block_coords参数为true,这样返回结果中就会包含表格每个单元格的坐标信息。您也可以设置output_excel_unformatted参数为true,这样返回结果就会是Excel文件格式,方便您进行后续的数据处理和分析。2023-07-06 15:51:31赞同 展开评论 -
天下风云出我辈,一入江湖岁月催,皇图霸业谈笑中,不胜人生一场醉。
自定义表格模板是针对固定版式的单页有框线表格表单数据提供的一款定制化产品。用户仅需通过一张模板数据的可视化拖拉拽配置参照字段、识别字段或表头&待识别的列表区域,字段属性等,无需进行数据标注和模型训练,即可实现相同版式数据的自定义结构化识别抽取。经过配置调优的模板识别准确率可达85%以上。https://help.aliyun.com/document_detail/603349.html?spm=a2c4g.270959.0.i3
2023-07-06 12:16:37赞同 展开评论 -
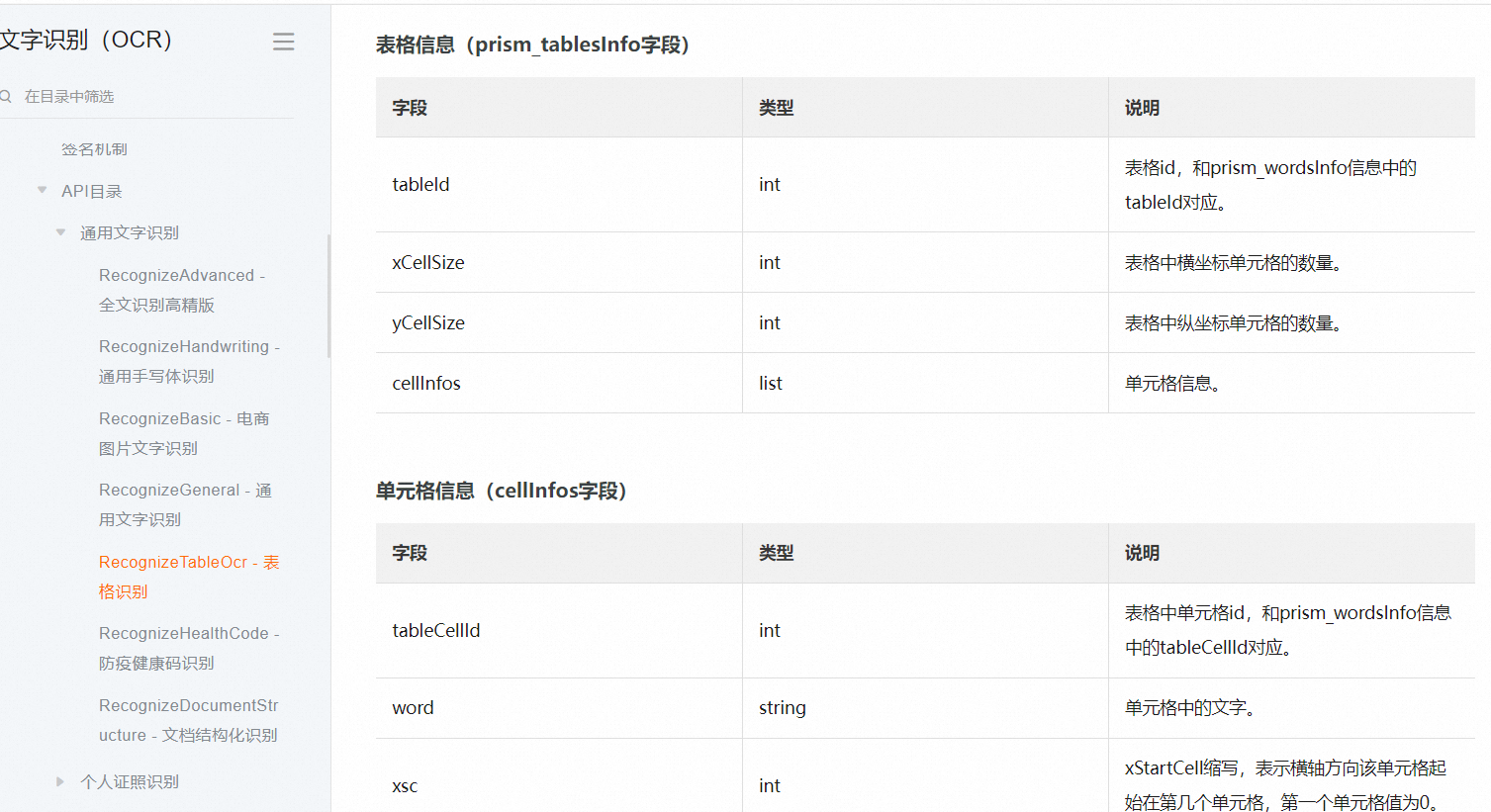 https://help.aliyun.com/document_detail/442251.html?spm=a2c4g.295350.0.0.38e2249e7NUU4G,此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”2023-07-03 11:19:25赞同 展开评论
https://help.aliyun.com/document_detail/442251.html?spm=a2c4g.295350.0.0.38e2249e7NUU4G,此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”2023-07-03 11:19:25赞同 展开评论

