
问题1:为什么ocr长文档识别,这样标注,一个字段都识别不了啊?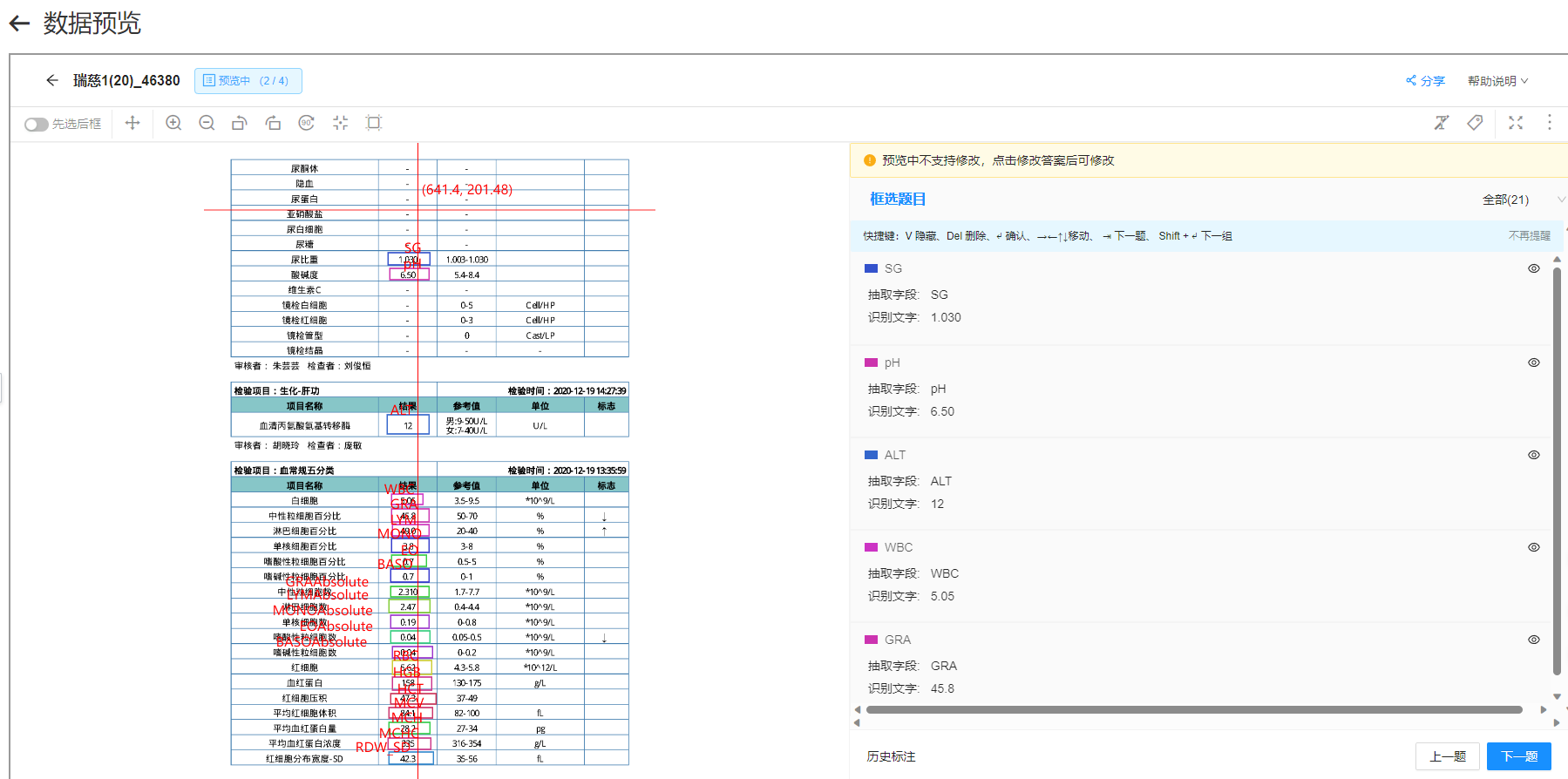 问题2:
问题2: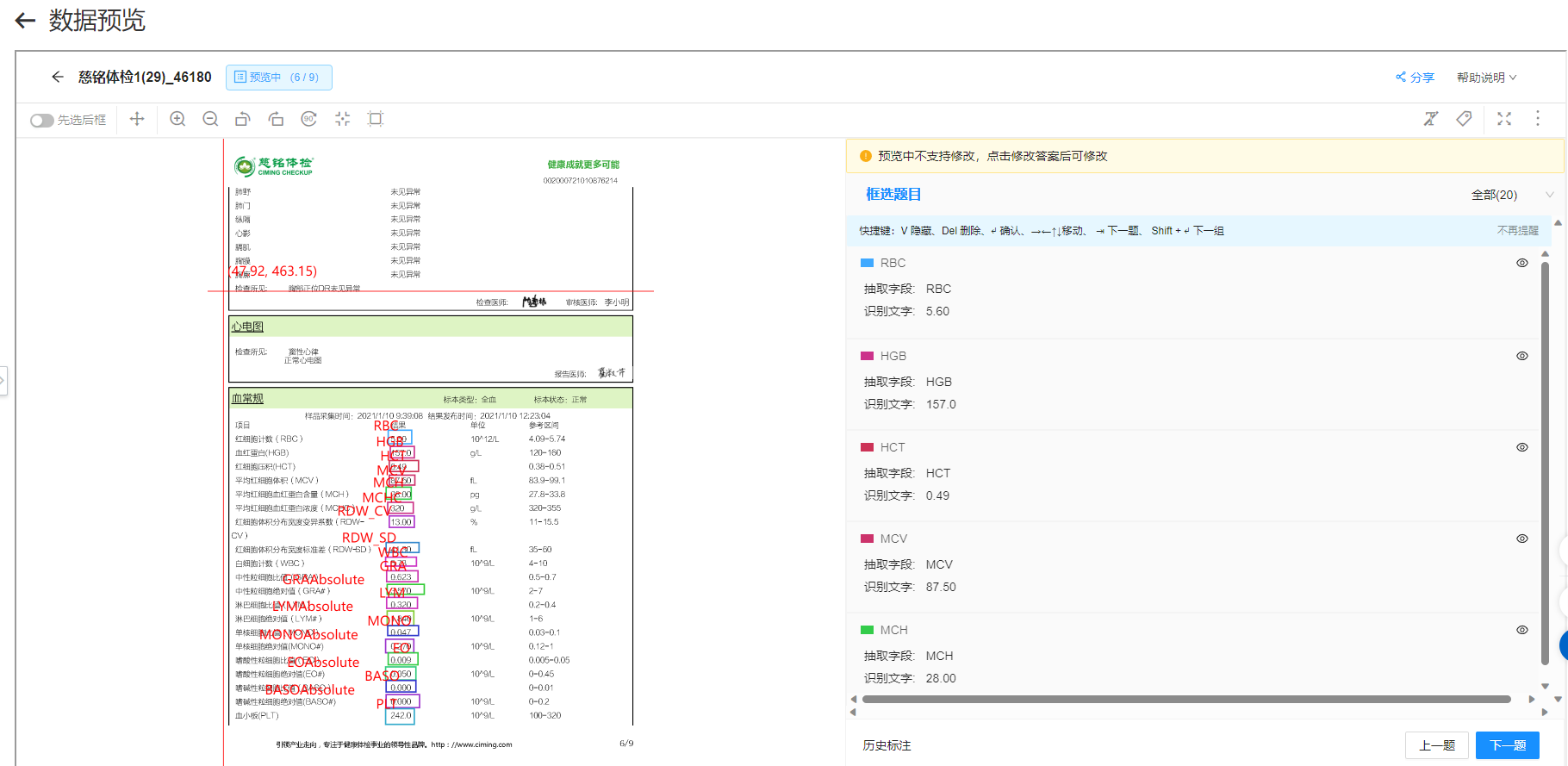 我们目前有两个模板都是没有一个字段识别的出来
我们目前有两个模板都是没有一个字段识别的出来
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云OCR长文档识别的准确性可能会受到多种因素的影响,导致某些字段无法被正确识别。以下是可能导致该问题的一些常见原因:
图像质量:对于长文档识别,图像的清晰度和质量对于准确性至关重要。如果图像模糊、有噪点或者过曝,可能会导致字段无法被正确识别。请确保图像清晰且质量良好。
字段特征:不同字段的特征和布局结构可能存在差异,某些字段可能比其他字段更容易被识别。识别算法可能会在处理复杂结构和行列布局等问题时出现一些困难。
字段类型:某些字段的类型可能比较特殊或复杂,例如手写字体、特殊符号或模糊的文本。这些情况可能导致算法难以准确地识别这些字段。
OCR算法限制:OCR算法并不是完美的,可能会有一些局限性。尽管算法经过了训练和优化,但仍然难以处理极端情况或某些复杂场景下的字段识别。
针对您遇到的问题,我建议您尝试以下方法来提高阿里云OCR长文档识别的准确性:
提供高质量的图像:确保图像清晰、无噪点,并且字体等细节可见。有时候,可以尝试调整图像的亮度、对比度或颜色平衡来改善图像质量。
进行字段校对和格式调整:如果某个字段没有被正确识别,可以检查该字段的特殊性并进行适当的调整。例如,确认字段的文本排列方式、字体类型或者是否包含特殊字符。
调整OCR配置参数:阿里云OCR提供了一些配置参数,例如指定语言、识别模式或字段类型等。根据具体情况,尝试调整这些参数,可能会提高字段识别的准确性。
尝试其他解决方案:如果在尝试以上方法后仍然不能满足需求,您可以考虑尝试其他OCR解决方案或第三方服务,以检查是否能够更好地满足您的需求。
回答1:标注的数据和测试的文件板式看着还是不太一样 应该是训练的有效样本太少了吧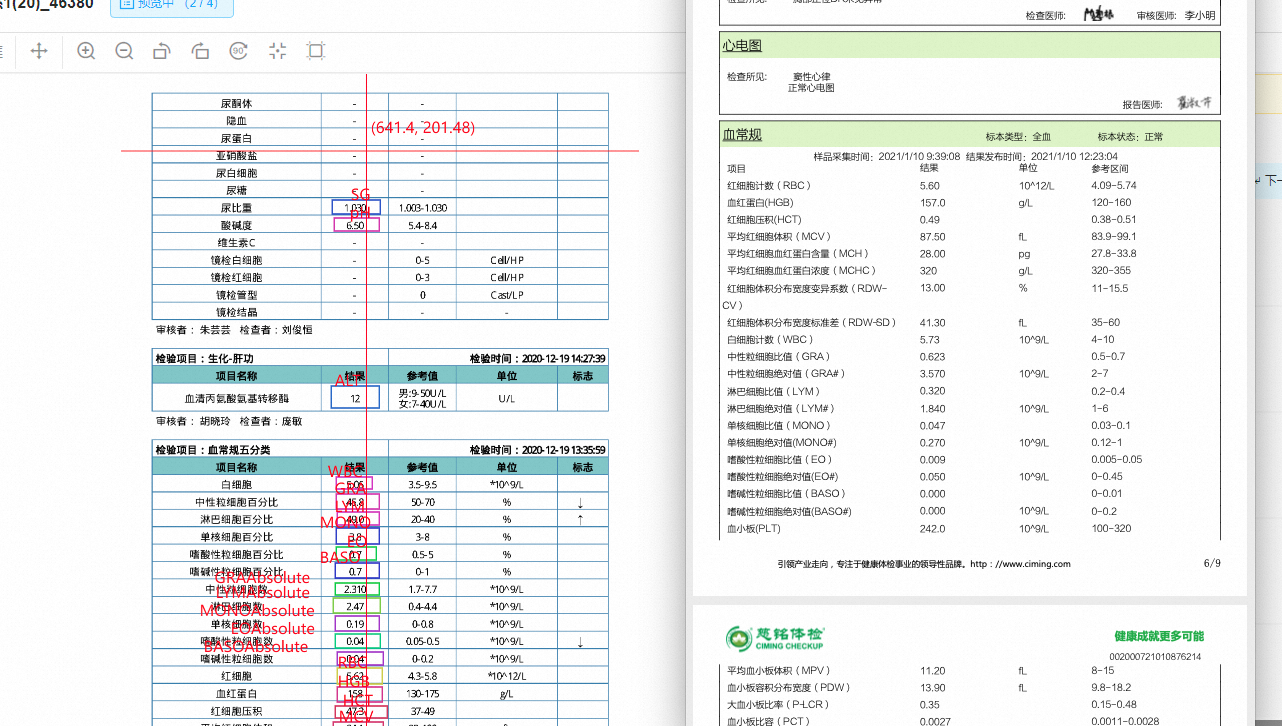 回答2:复制的没用的哈,进到模型的话还是1条样本,至少是需要20条不同的样本才行, 模型是一个见多才识广的,长文档信息抽取需要50份不同的标注好的数据才能获得比较好的结果 此前也给过一些其他建议,已经在群里说过很多了。 比如如果体检报告是很固定的,把文档按页拆开,用自定义表格模板也能完成信息抽取。模板配置很快,但同样对于样式也有限制。,此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
回答2:复制的没用的哈,进到模型的话还是1条样本,至少是需要20条不同的样本才行, 模型是一个见多才识广的,长文档信息抽取需要50份不同的标注好的数据才能获得比较好的结果 此前也给过一些其他建议,已经在群里说过很多了。 比如如果体检报告是很固定的,把文档按页拆开,用自定义表格模板也能完成信息抽取。模板配置很快,但同样对于样式也有限制。,此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
当使用 OCR 进行长文档识别时,有时可能会遇到字段无法正确识别的情况。这可能是由以下原因之一引起的:
图片质量问题:长文档中可能存在图片模糊、光照不足、角度偏斜或扭曲等问题,这会导致OCR识别错误或失败。确保长文档的每个图像都是清晰的、高分辨率的,并尽量避免阴影、反光或其他干扰。
字体和语言支持问题:OCR 可能对某些特殊字体或语言的支持有限。如果长文档中使用了特殊字体、非常规语言或特定领域的术语,可能会导致识别困难。请检查所使用的字体和语言是否在 OCR 的支持列表中,并选择正确的语言设置。
布局和结构问题:长文档通常包含多种布局和结构,例如表格、列、段落等。OCR 可能在处理复杂布局或结构化数据时遇到困难。确保长文档的结构清晰,并尝试使用适当的前处理技术(例如分割、校正)来减少布局和结构方面的问题。
文本重叠或干扰:长文档中的文本可能会相互重叠、交叉或受到其他干扰。这可能导致OCR无法正确划定字段边界或识别混合文本。如果长文档存在这样的问题,可以尝试使用图像处理技术(如分割、去噪、排除干扰线等)来减少干扰。
OCR算法限制:OCR 算法在处理长文档时可能存在一些局限性,例如对于长段落、手写字体或特殊符号的识别效果可能较差。这取决于所使用的OCR工具和算法的能力。在选择OCR工具或服务时,请确保其适用于您的特定场景和数据类型。
解决这些问题的方法包括改善图像质量、调整语言设置、优化布局和结构、使用图像处理技术以及选择更适合长文档识别的OCR工具和算法。根据实际情况,可能需要进行多次尝试和调整,以获得更好的识别结果。


