
OCR都是传图片地址,怎么传文件啊?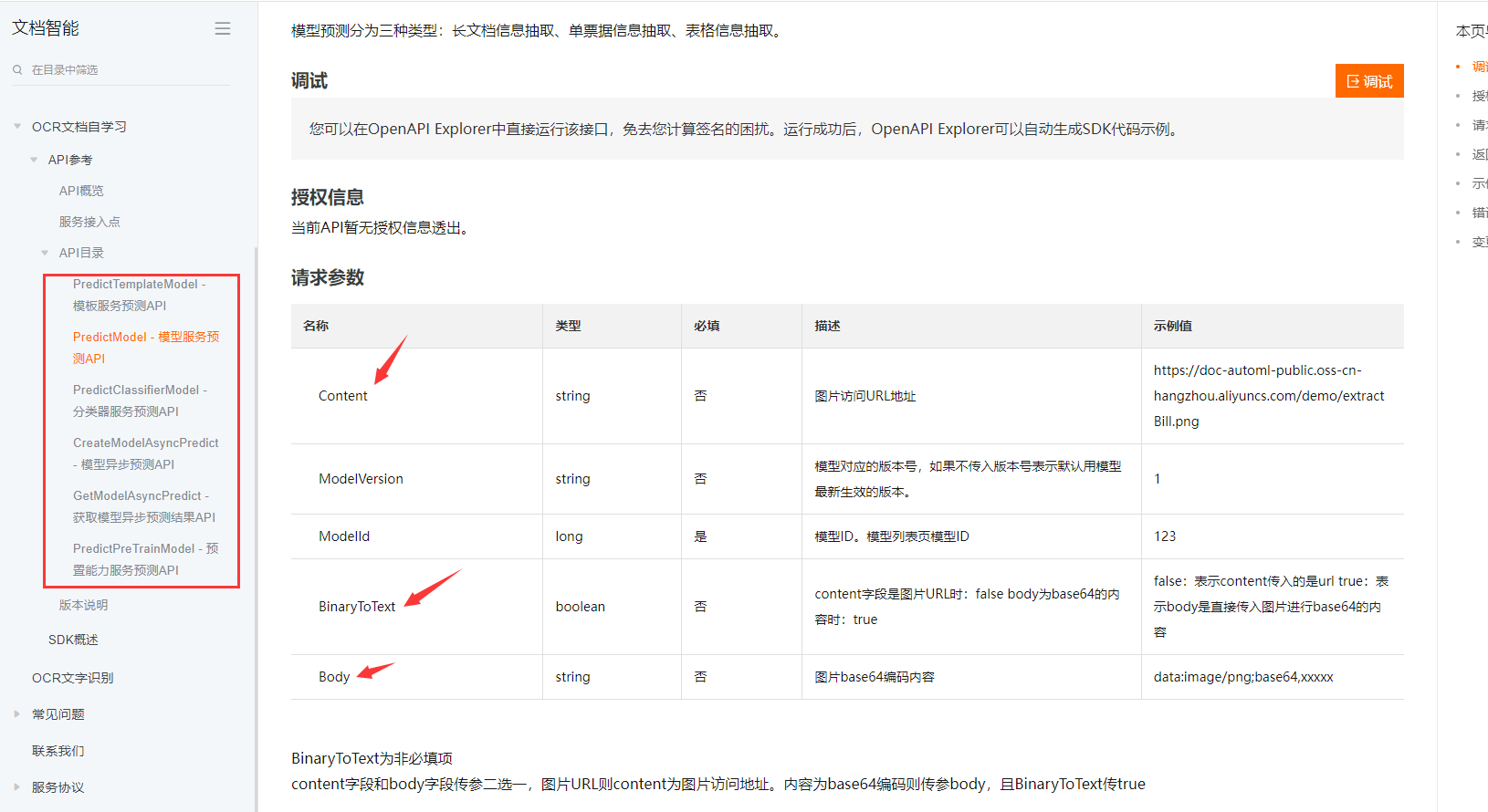
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
对于阿里云OCR接口,目前只支持传递图片地址进行识别,而不支持直接传递文件。
如果你想使用OCR接口处理PDF文件,可以按照以下步骤进行:
将PDF文件转换为图片:使用PDF处理工具或库,将PDF文件转换为图片格式,如JPEG、PNG等。可以使用第三方库,比如PyPDF2(Python)或iText(Java),将PDF文件逐页地转换为图片。
将转换后的图片上传到可公开访问的存储空间中,比如阿里云OSS(对象存储服务),或者其他类似的文件存储服务。确保获取到图片的公开访问链接。
调用OCR接口时,传递图片的链接参数进行识别。OCR接口会根据提供的图片链接进行处理和识别。
由于OCR接口对于文档的布局和格式有一定的要求,对于复杂的多页PDF文件,可能需要额外的处理来保证准确性。
在使用OCR技术时,通常需要将图片或文件传递给OCR引擎进行处理。可以通过以下几种方式来实现:
传递图片的URL地址:这是最常用的一种方式,即直接传递包含图片地址的URL链接。OCR引擎会根据提供的URL地址访问并获取对应的图片或文件,并进行识别。
上传文件到服务器:可以将待识别的图片或文件上传到服务器上,然后再通过服务器上的路径传递给OCR引擎进行处理。这种方式需要涉及文件上传和服务器端开发等技术,相对较为复杂。
Base64编码传输:将图片或文件进行Base64编码,然后再将编码后的字符串传递给OCR引擎。部分OCR服务提供商支持Base64编码传输,但需要注意传输文件大小限制,否则可能会导致传输失败或识别效果下降。
需要注意的是,不同的OCR服务提供商可能对文件传输方式有所要求和限制,可以根据具体情况选择合适的传输方式。同时,也需要考虑数据传输的安全和可靠性,避免数据泄漏和丢失等风险。
OCR里有个长文档信息抽取,支持用户自定义抽取字段,通过平台可视化引导,完成数据标注和模型训练,实现对非结构化、多版式的文档的高精度抽取。
高性能模型:适用于文档样式/格式较为简单的文档。例如仅包含标题、段落的文档;支持的文档格式包括PDF/图片。适用于证明、文书、文件、信件、公告等行业场景。
在数据准备中,数据集可上传图片、文档、压缩包;
文档,支持不超过20M且后缀为pdf的文件,仅支持单页pdf;


