
视觉智能平台这个怎么通过mask图片去分割了?
视觉智能平台这个怎么通过mask图片去分割了?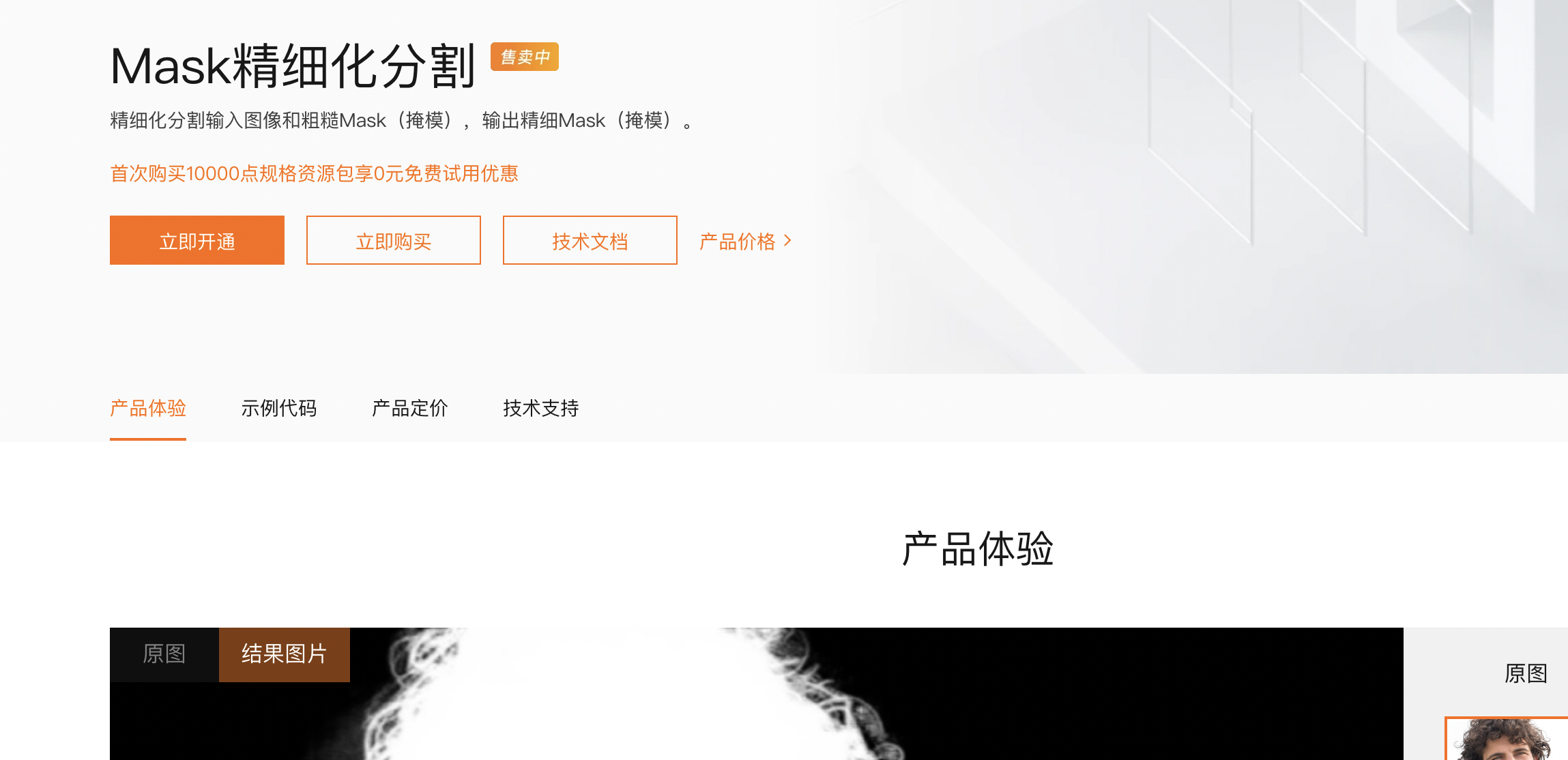
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
2
条回答
写回答
-
视觉智能平台可以通过以下步骤通过mask图片进行分割:
-
准备数据:将需要分割的图像和对应的mask图像准备好。
-
加载数据:使用Python中的图像处理库,如OpenCV或Pillow,将图像和mask图像加载到内存中。
-
数据预处理:将图像和mask图像进行预处理,如缩放、裁剪、旋转等。
-
创建模型:使用深度学习框架,如TensorFlow或PyTorch,创建分割模型,如U-Net、Mask R-CNN等。
-
训练模型:使用训练集对模型进行训练,调整参数,优化模型。
-
测试模型:使用测试集对模型进行测试,评估模型的性能。
-
应用模型:将模型部署到视觉智能平台上,使用模型对新的图像进行分割。
在模型应用过程中,可以使用模型预测出的分割结果与原始图像进行对比,进行后处理,如去除噪声、填充空洞等,以得到更准确的分割结果。
2023-06-12 14:52:01赞同 展开评论 -
-

问答分类:
相关问答


相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理