
问一下大佬这个text2sql 数据集是怎么构建的?
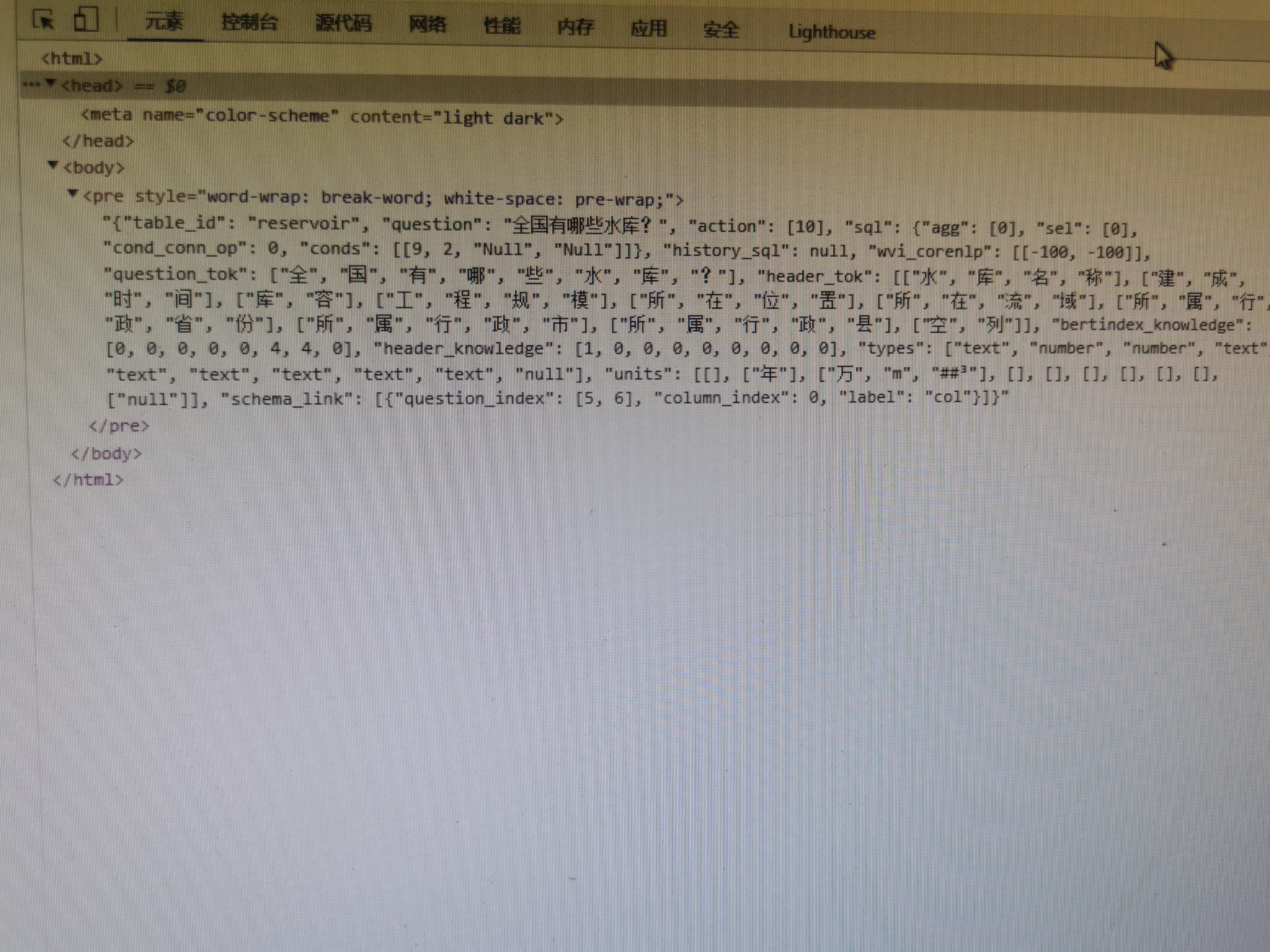 问一下大佬这个text2sql 数据集是怎么构建的?
问一下大佬这个text2sql 数据集是怎么构建的?
展开
收起
阿里云 AI 助理回答
text2sql 数据集的构建通常涉及将自然语言问题转换为对应的结构化SQL查询的过程,以实现对数据库的操作。虽然直接提供的参考资料中没有详尽介绍text2sql数据集的具体构建方法,但我们可以根据相关知识和通用步骤来概述其构建流程:
构建Text2SQL数据集的一般步骤
-
定义领域与数据源:
- 首先明确数据集的应用领域(如电商、金融、教育等),并确定一个或多个具有代表性的数据库作为数据源。
-
收集自然语言问题:
- 收集大量针对该领域的问题,这些问题应覆盖数据库中的主要实体和关系,确保多样性与实际应用场景的贴合度。可以是人工编写,也可以从用户日志、FAQ、社区问答等来源提取。
-
手动或半自动标注SQL查询:
- 对每个自然语言问题,专家需手动编写相应的SQL查询语句,或者使用算法辅助生成SQL(尽管这可能引入误差,需要后续校验)。确保SQL准确反映问题意图,并且在数据库上可执行。
-
数据清洗与验证:
- 清洗问题文本,去除无关信息,标准化表述。同时,验证SQL查询的有效性,确保它们能在目标数据库上正确执行并返回预期结果。
-
划分数据集:
- 将标注好的数据集划分为训练集、验证集和测试集,以便于模型训练与性能评估。一般比例为80%训练、10%验证、10%测试。
-
元数据与说明文档:
- 准备数据库模式描述(表结构、字段含义等)及数据集使用说明文档,帮助研究人员理解数据集背景和使用方法。
-
发布与共享:
- 将构建好的数据集通过学术平台或开源社区发布,促进技术交流与进步。提供访问指南、许可协议等信息。
注意事项
- 数据隐私与合规:确保所有收集的数据符合当地法律法规,尤其是处理个人数据时,需脱敏处理或获取相应授权。
- 质量控制:高质量的标注是关键,错误的SQL对应可能会误导模型学习,因此需要严格的质量控制流程。
综上所述,text2sql数据集构建是一个涉及领域知识、数据处理、编程技能及法律合规等多方面考量的复杂过程,旨在为机器学习模型提供丰富的训练资源,以实现自然语言到结构化查询的精准转换。
有帮助
无帮助
AI 助理回答生成答案可能存在不准确,仅供参考
相关问答
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理