Join过程
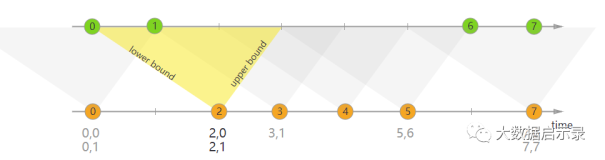
只是在流处理模式下,join的两个表是流式的,这就涉及到两边相互等待的问题了:例如左表来了⼀条数据,join 右表时发现没有匹配的记录,这时会直接放弃join吗?还是会等待⼀段时间呢再次join呢?会⽆限等待下去吗?
答案是,两边表⾥的数据都会在状态中保存⼀段时间,直到join上为⽌,默认是⽆限保存,可以设置过期时间(过期 时间类似于session,只要有join上的情况出现就会⾃动延期):
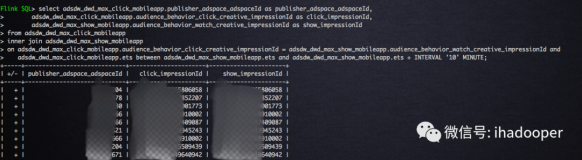
双流join的语法没什么特殊的
SELECT*FROMOrdersINNERJOINProductONOrders.product_id=Product.id; SELECT*FROMOrdersLEFTJOINProductONOrders.product_id=Product.idSELECT*FROMOrdersRIGHTJOINProductONOrders.product_id=Product.idSELECT*FROMOrdersFULLOUTERJOINProductONOrders.product_id=Product.id
实例代码:
packagecom.blink.sb.join; importcom.blink.sb.beans.Orders; importcom.blink.sb.beans.Product; importorg.apache.flink.configuration.Configuration; importorg.apache.flink.streaming.api.datastream.DataStream; importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment; importorg.apache.flink.table.api.bridge.java.StreamTableEnvironment; /*** 这里演示下Flink的join*/publicclassFlinkJoin { publicstaticvoidmain(String[] args) throwsException { //1、获取Stream执行环境StreamExecutionEnvironmentenv=StreamExecutionEnvironment.getExecutionEnvironment(); //2、创建表执行环境StreamTableEnvironmenttEnv=StreamTableEnvironment.create(env); //设置空闲状态清理时间,默认0标识永不清理// tEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5));//也可以用这种方式设置Configurationconfiguration=tEnv.getConfig().getConfiguration(); configuration.setString("table.exec.state.ttl", "5s"); //3、读入订单数据DataStream<Orders>ordersStream=env.socketTextStream("localhost", 8888) .map(event-> { String[] arr=event.split(","); returnOrders .builder() .user(arr[0]) .productId(Long.parseLong(arr[1])) .amount(Integer.parseInt(arr[2])) .orderTp(Long.parseLong(arr[3])) .build(); }); //4、读取产品数据DataStream<Product>productStream=env.socketTextStream("localhost", 9999) .map(event-> { String[] arr=event.split(","); returnProduct .builder() .id(Long.parseLong(arr[0])) .name(arr[1]) .build(); }); tEnv.createTemporaryView("orders",ordersStream); tEnv.createTemporaryView("product",productStream); //5、双流JointEnv.sqlQuery("select * from orders o join product p on o.productId=p.id") .execute() .print(); } }