接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
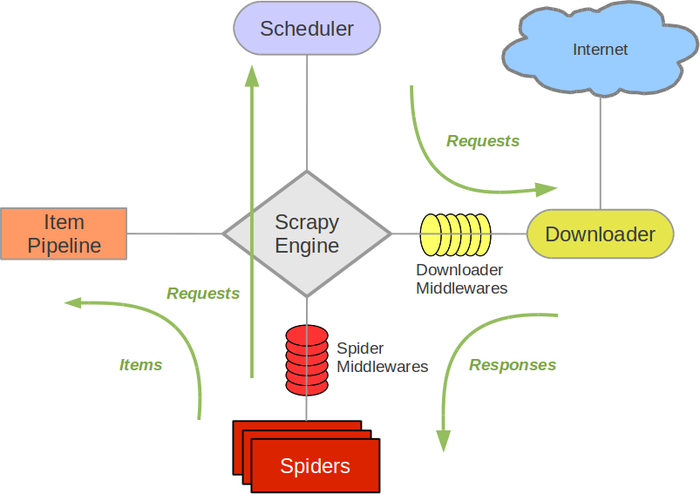
来源于https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html
知识在于点滴积累接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
来源于https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html
知识在于点滴积累

