摘要:本文主要介绍Tuple库的使用,并指导读者用自己的方式来重新实现这个库,以此帮助其学习模板元编程的一些技巧。
推广:数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
本场技术沙龙回顾链接:C++:std::tuple与模板元编程
陶云峰,阿里云高级技术专家,上海交通大学理论计算机科学博士,专注数据存储、分布式系统与计算等领域,写了20多年程序。2000年参加ACM/ICPC大赛,实现亚洲队伍进World Final前十的突破。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要围绕以下三个方面:
一、std::tuple使用介绍
二、实现自己的std::tuple
三、总结
一、std::tuple使用介绍
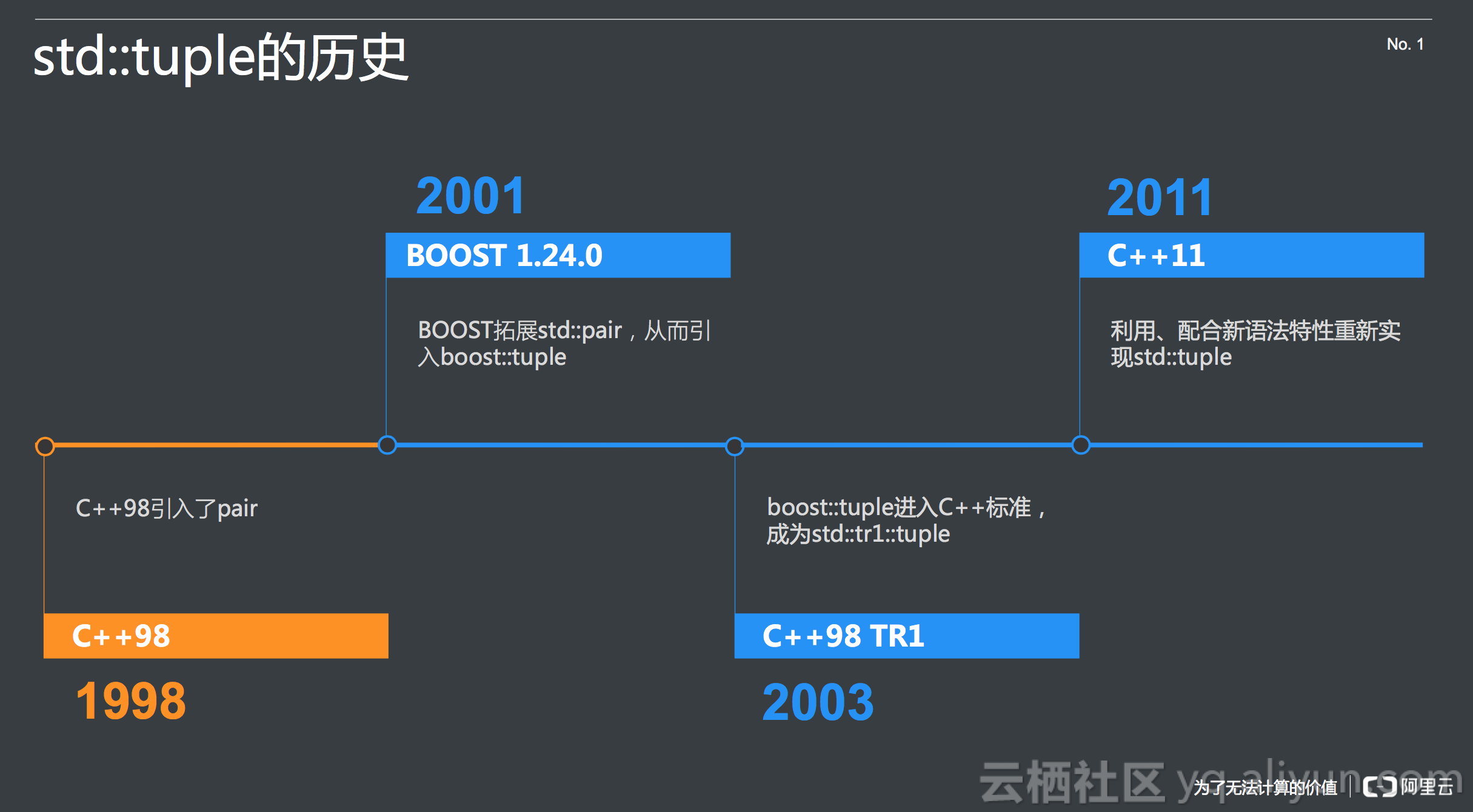
tuple这个库其实历史很悠久,C++ 98标准出来以后,没过几年就有人觉得BOOST标准库中的std::pair的实现有问题,从而在2001年引入了boost::tuple,并且于2003年后进入C ++ 98 TR1标准,成为std::tr1:tuple。C++ 98 TR1有一个别号,也叫做C++ 03,需要特别关注一下,因为对于很多用C++ 98的同学,目前主流的编译器已经增加到了对C++ 98 TR1的支持。然后在2011年,C++ 11发布,利用、配合新语法特性重新实现了std::tuple,相对于之前的版本,C++ 11中的tuple在很多地方是很不一样的,如各种函数名等。
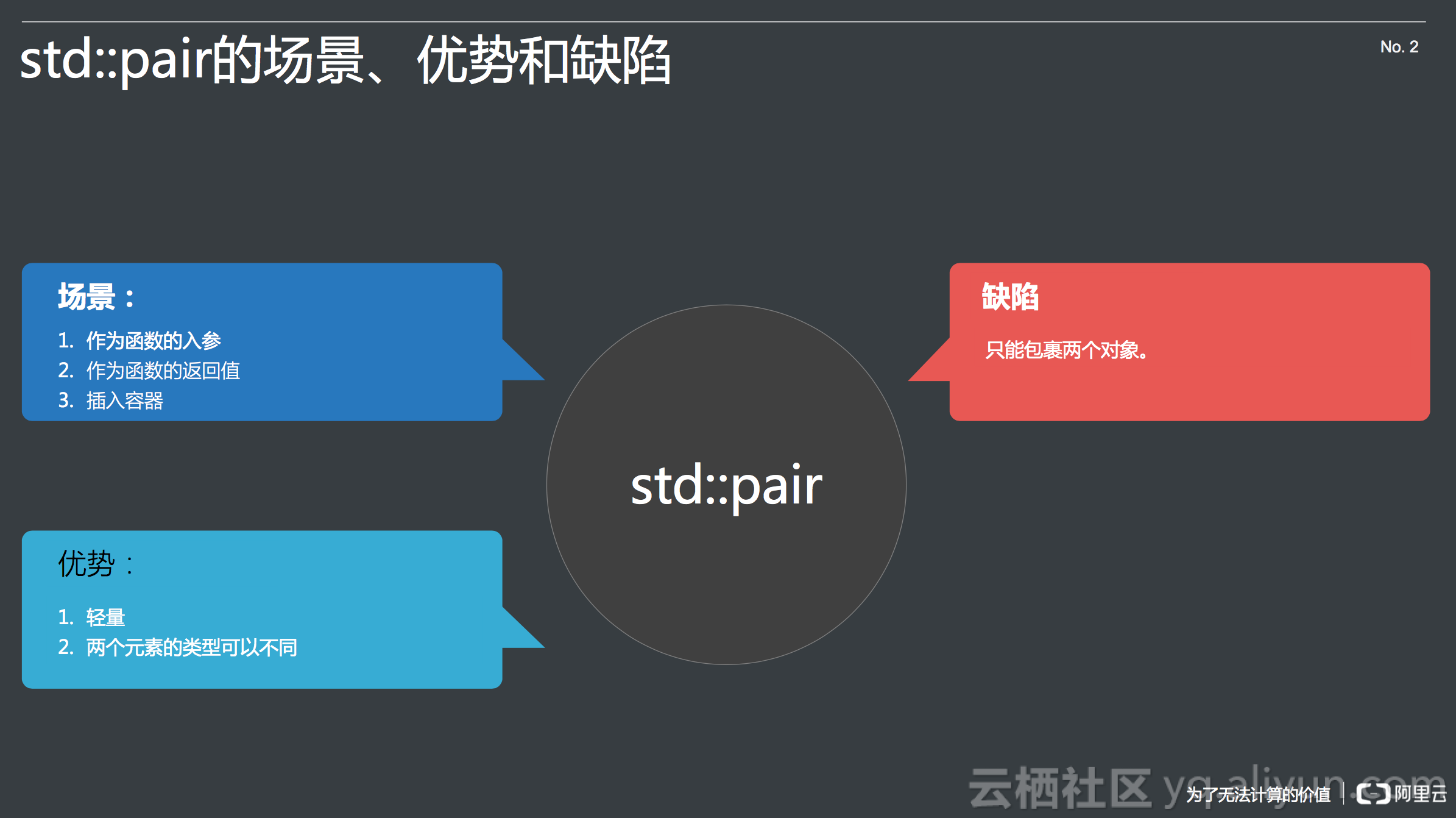
std::pair的三个使用场景分别是作为函数的入参,作为函数的返回值和插入容器。它的优势是很轻量,基本上没有overhead;然后两个元素的类型可以不同,这点和std::vector不一样。但它有一个缺点是只能包裹两个对象,如果需要三元或四元,如图形学里经常用到的三维或四维向量,这时候就无法使用std::pair了。
C++ 11中tuple的使用方法非常简单,如下所示。
std::tuple 取元素
#include
using namespace std;
void f() {
tuple t0;
tuple t1(1, 0.1, "s");
t0 = t1;
get<1>(t1) = 0.2;
cout << tuple_size::value<< endl;
}其中,tuple后面想声明几个类型直接声明即可,然后它提供一个默认构造函数,如果里面每个元素都有一个构造函数,那它也是默认构造的,构造过程中可以传值,也可以对tuple进行赋值,t1赋给t0的话,这样t0就有了1、0.1和s对应位置值,当然前提是t1对应位置的每个值都是可以拷贝的。然后可以获取某个位置的元素,get<1>(1)=0.2就是将0.2赋给t1的第二个元素(0是第一个)。我们也可以通过tuple_size<decltype(t0)>获得tuple的长度,
std::tuple构造
std::tuple的构造如下所示:
tuple<int, double> t0;
tuple<int, double> t1(1, 3.14);
double d = 5;
tuple<double&> t2(d);
tuple<const double&> t3(d+3.14);构造比较简单,都是基础类型和相应的值。需要注意的是tuple类型中可以是引用的形式,可以是非const的引用,也可以是const的引用,可以传一个临时值。
make_tuple()
很多时候填tuple的类型参数,会觉得很麻烦,这时候可以使用和make_pair()类似的函数make_tuple(),使用方法如下所示。
int a = 1;
double b = 2.0;
const tuple<int,double>& t0 = make_tuple(a,b);
int& c = a;
double& d = b;
auto t1 = make_tuple(c,d); // tuple<int,double>!make_tuple会自动识别类型,但它的识别并不总是准的,比如说引用类型会识别成无引用的类型,即值类型,这不是我们想要的。这个时候就要使用cref()来解决这个问题(如下所示),其中的c代表const,cref(a)代表a的const引用,而ref(a)代表a非const引用。
A a; const A ca = a;
make_tuple(cref(a)); // tuple<const A&>
make_tuple(cref(ca)); // tuple<const A&>
make_tuple(ref(a)); // tuple<A&>tie()
介绍一个很有用的功能,即tie()。任何一个函数返回一个tuple,tuple的取值有两种解决方法,一种是将tuple存下来,然后用get()一个一个去拿,这种方法比较麻烦;另一种是可以用tie(),将必要的元素事先声明好,然后将make_tuple()的结果直接赋值给tie()。如下,tie(i, c, d)被赋值之后,相应的值都有了。
int i; char c; double d;
tie(i, c, d) = make_tuple(1, ’a’, 5.5);
cout << i << “ ” << c << “ ” << d; // 1 a 5.5tie()还有一个有意思的功能,即ignore。如果不想要某个值,可以直接ignore掉。比如说如下的例子,是一个数学上有意义的事情,假设有两个数a和b,要求这两个数的最大公约数,计算方法(欧几里得算法)大家应该都知道。该方法还可以求欧几里得公式,即,使得ax+by=d成立的整系数x,y,其中d是a和b的最大公约数。欧几里得算法扩展一下可以将x和y也计算出来,这就是具体实现的方法。然后将其作为一个tuple返回,第一个参数是最大公约数d,第二个参数是a的系数x,第三个参数是b的系数y。以8和12为例,算出的最大公约数d是4,x=-1,y=1,换句话说是(-1)*8+1*12=4。但通常我们只需要最大公约数,不需要x和y这两个系数,这时候可以放std::ignore忽略掉,这样就可以很方便地在需要的时候算欧几里得公式,不需要的时候直接拿到最大公约数。这就是tie()配合ignore可以实现的很有意义的功能。

二、自己动手实现tuple
接下来介绍如何自己动手实现tuple,当然这里的tuple主要以学习为目的,所以我们可以将其简化。具体的需求如下:
1) 实现一个Tuple类,可以接受多个值参数,不用处理引用这么复杂的事情
2) 实现一个类Length去求长度
3) 实现fetch()。改个名字为了避免和标准库的get()同名
注意:tie()和ignore这种功能作为学习来讲太过复杂,在此不做实现。
准备工作
首先需要学习一点数学知识,即利用二元组和空集可以实现任意维元组。
- 零维元组:⌀ (空集)
- 一维元组:(a, ⌀)(一个pair,a是第一个元素,第二个元素放空集)
- 二维元组:(a, (b, ⌀))(一维的元组前面再加一个pair)
- 三维元组:(a, (b, (c, ⌀)))(二维的元组前面再加一个pair)
pair的两个元素习惯上有两个特别的名称,以三维元组为例,a称为Head,(b, (c, ⌀))称为Tail。
具体在写过程中,经常想要知道具体是什么类型,或者是一个模板变量,或者是一个物理上具体实现出来的变量,当然你可以选择typeinfo,但是typeinfo有一些缺点,在此不做展开。最好的方法是让编译器告诉你这是什么类型,这又是一个小技巧,我们可以实现一个只有声明没有实现的类,然后让编译器告诉你的时候只需要直接打:

遇到编译的时候编译器会告诉你,声明了但是没有实现出来,这时候类型信息我们就可以拿到。主流的编译器不管是GCC、Clang还是VC,我们都可以拿到这些有用的信息,虽然每个编译器的错误信息不一样。
Variadic Template
C++ 11引入了一个特性,叫做Variadic Template(变长模板),我们可以看一下,这个tuple一定是变长的,它可以是零元的,一元的或者二元的甚至更高元的。变长的模板的声明方式如下,class后面三个点,Ts是变长模板的名字,可以接受零元的t0,一元的t1,二元的t2。
template<class... Ts>
struct Tuple
{
};
Tuple<> t0;
Tuple<int> t1;
Tuple<int,double> t2;需要指出的是,Ts并不是一个变量的类型,它是一包类型,类型的包本身是不支持声明变量的,因为编译器不知道怎么样把它转换成可以声明的类型。类型包必须要进行unpack后转换成编译器可以识别的类型,具体的转换方法后面会介绍。
接下来介绍如何实现数学上的空集Nullary和Pair,pair有两个子类型,一个是Head,另一个是Tail,指令如下:
然后可以将Variadic Template包装成一组pair,需要一个辅助的类WrapIntoPair,帮助我们将Variadic Template转换成pair套pair的形式,首先需要声明,声明方式如下。然后还需要另一个辅助的类ShrinkVariadic,它的作用是将Variadic Template中一包类型中的第一个(Head)给切下来,尾部继续调WrapIntoPair。

可以看到,对于Variadic Template,C++只允许我们做三个操作,第一个操作是将它的Head切出来,第二个操作取它的长度,第三个操作是将Ts中剩下的操作一个一个贴在上面。
下图是WrapIntoPair的具体实现,这个实现其实是很简单了,因为我们已经将它的头和尾都切出来了,直接把它包一下即可。可以看到WrapIntoPair调用了ShrinkVariadic,而ShrinkVariadic又调用了WrapIntoPair,实际上这是一个递归的过程。既然是递归,就要有边界,递归的终止条件是当Ts的长度为0的时候,什么都不需要做了,这时候它的Type是Nullary(空集)。

下面来看一个具体的例子WrapIntoPair<2, int, char>,它的Type应该是一个Pair,首先是拿到它的Head和Tail,它的Head是int,所以这里可以直接填进来,而Tail是一个递归,就变成了WrapIntoPair<1,char>,然后WrapIntoPair<1,char>的类型又是一个Pair,这时候是ShrinkVariadic<char>的Head和Tail,分别是char和WrapIntoPair<0>,而WrapIntoPair<0>的类型是空集,所以最后的结果是Pair<int, Pair<char, Nullary>>。我们可以看到已经有一个二元组,空集和char组成一个一元组,再加上前面的int组成一个二元组。

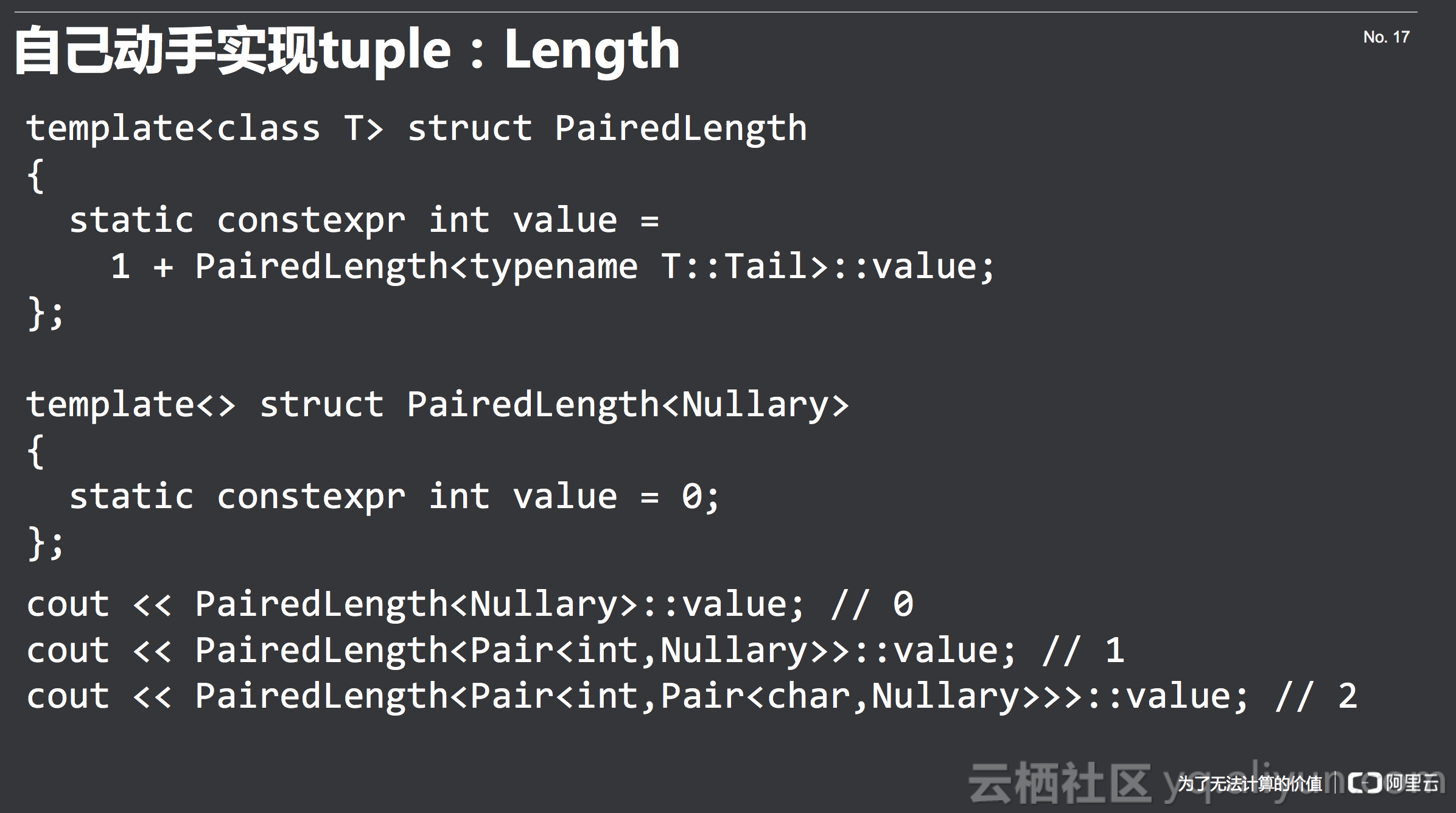
Length
类型我们上面已经搞定了,接下来看下如何求pair的长度。我们可以定义一个辅助类,这个辅助类仍然是递归的,如果是空集,那么长度一定为0,如果不是空集,那么一定有Head和Tail,Head的长度为1,然后Tail的长度加Head的长度便是整个Pair的长度。这个过程又是一个递归。可以看一下Nullary的长度为0,Pair<int,Nullary>的长度是1,Pair<int,Pair<char,Nullary>>的长度是2.
最后是完整的Tuple的类型,这个类型我们已经知道了,通过WrapIntoPair打包成一组类型Paired,然后长度通过PairedLength也很容易计算出来。我们可以想到,既然已经变成类型,那么就可以声明变量了,通过Paired mPaired实现变量的声明。

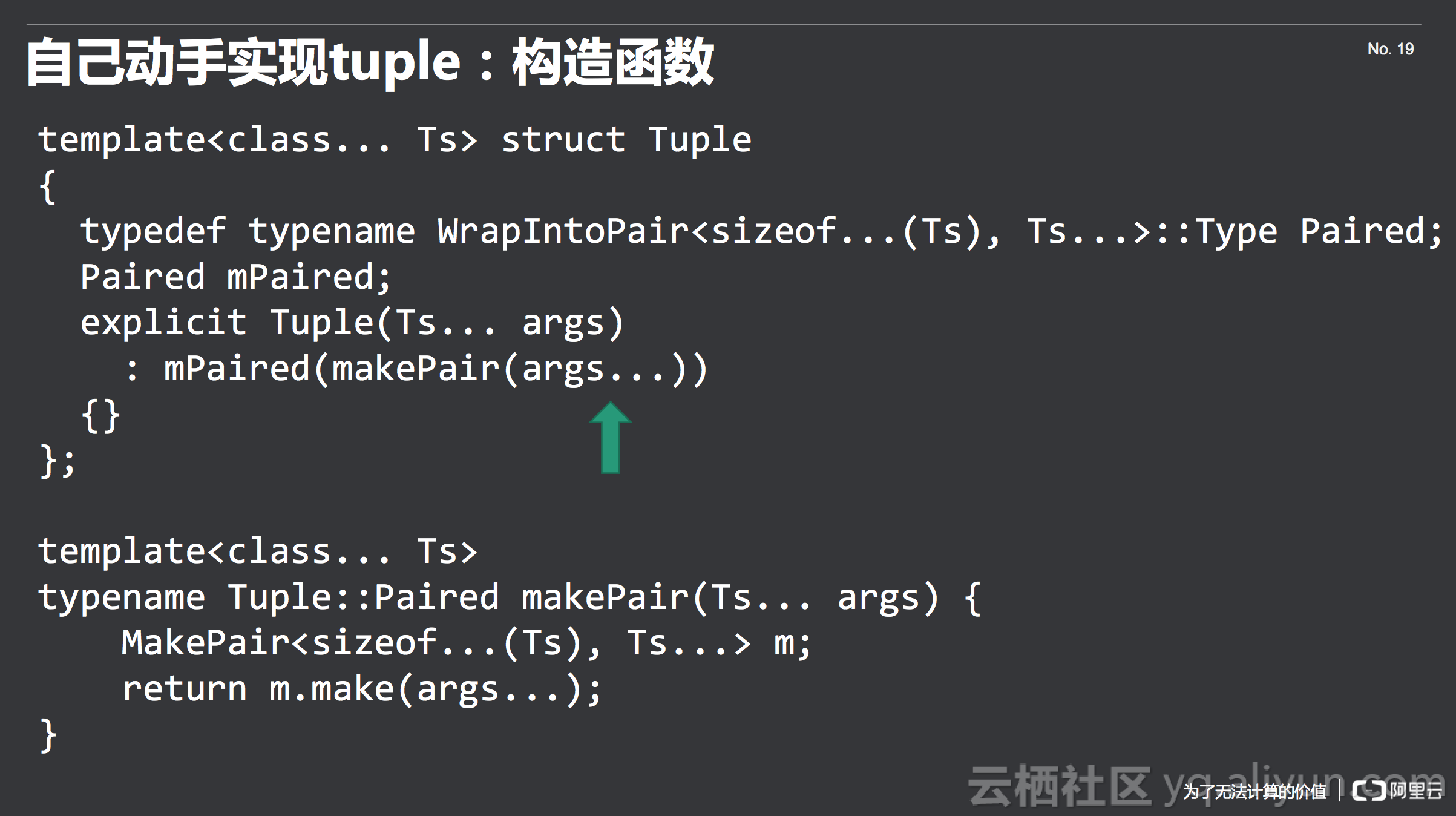
构造函数
接下来的问题是变量mPaired怎么构造,我们看一下Tuple的构造函数,如下所示,构造函数里面如果要用Variadic Template,通过Ts... args,跟Ts一样,args也不是一个变量的名字,而是一组变量,要用的时候和Ts一样,后面加三个点(args...)做unpack。这边用到了一个辅助函数来帮助做这件事情,辅助函数弄到一个辅助类中,在辅助类里面有一个make方法,由这个方法来实际做这件事情。为什么要用到辅助类呢,这实际上是个人偏好,当然这不是必须的,但是我一般喜欢用辅助类来做模板的运算,因为辅助类可以实现模板部分特化,而函数不能用做部分特化。
下面我们看MakePair具体应该怎么做,首先声明一下,很显然这是一个递归的过程,所以要先声明。递归的边界是空集,当是零元的时候,需要返回一个Nullary。
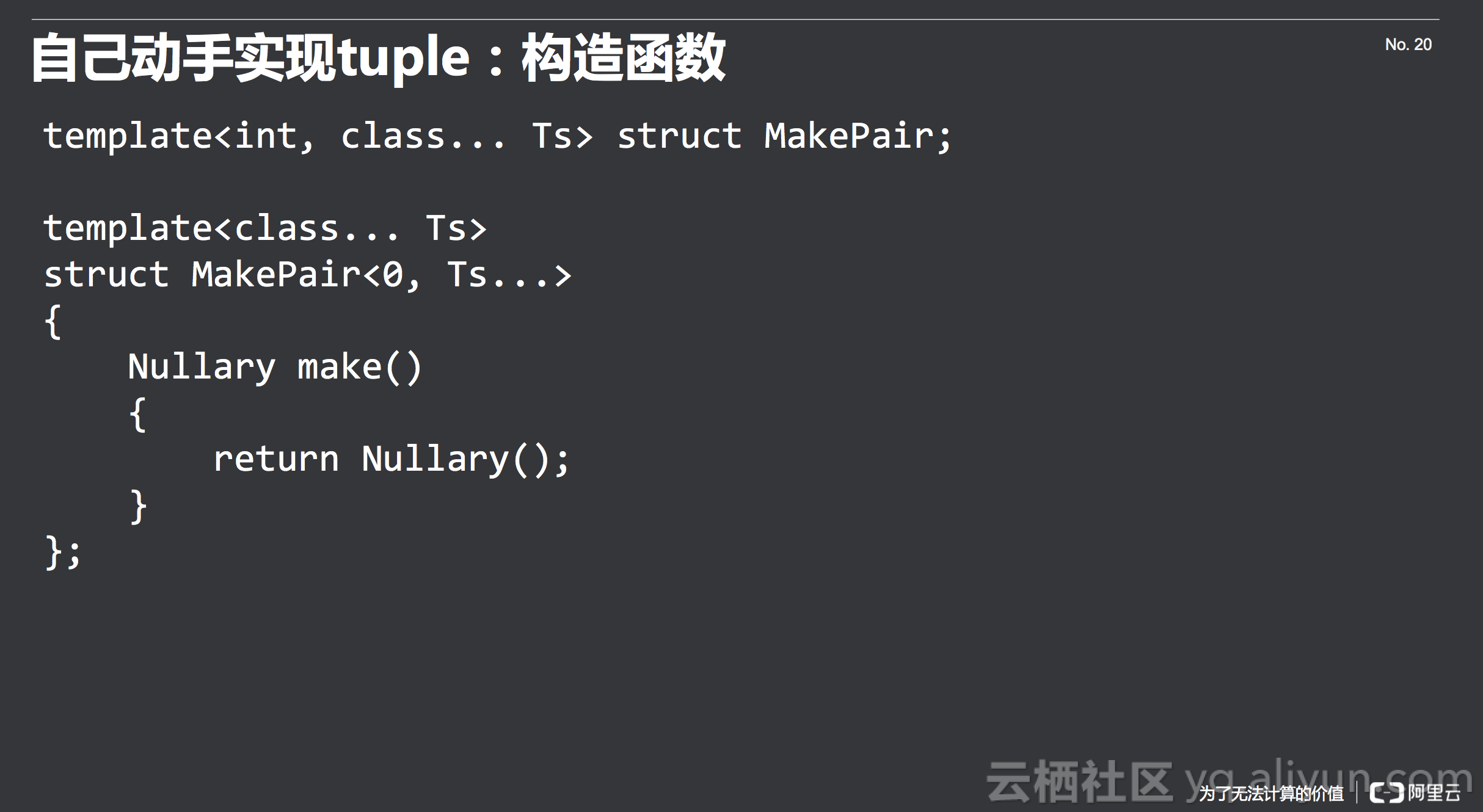
递归的过程如下所示:首先传入一个长度大于零的参数列表,将它的Head切下来,然后就知道这个Head已经是一个真正的变量,当然Tail不是,所以可以将Head直接拿来构造,放到构造函数中。接下来对Tail递归的实现刚才的过程,
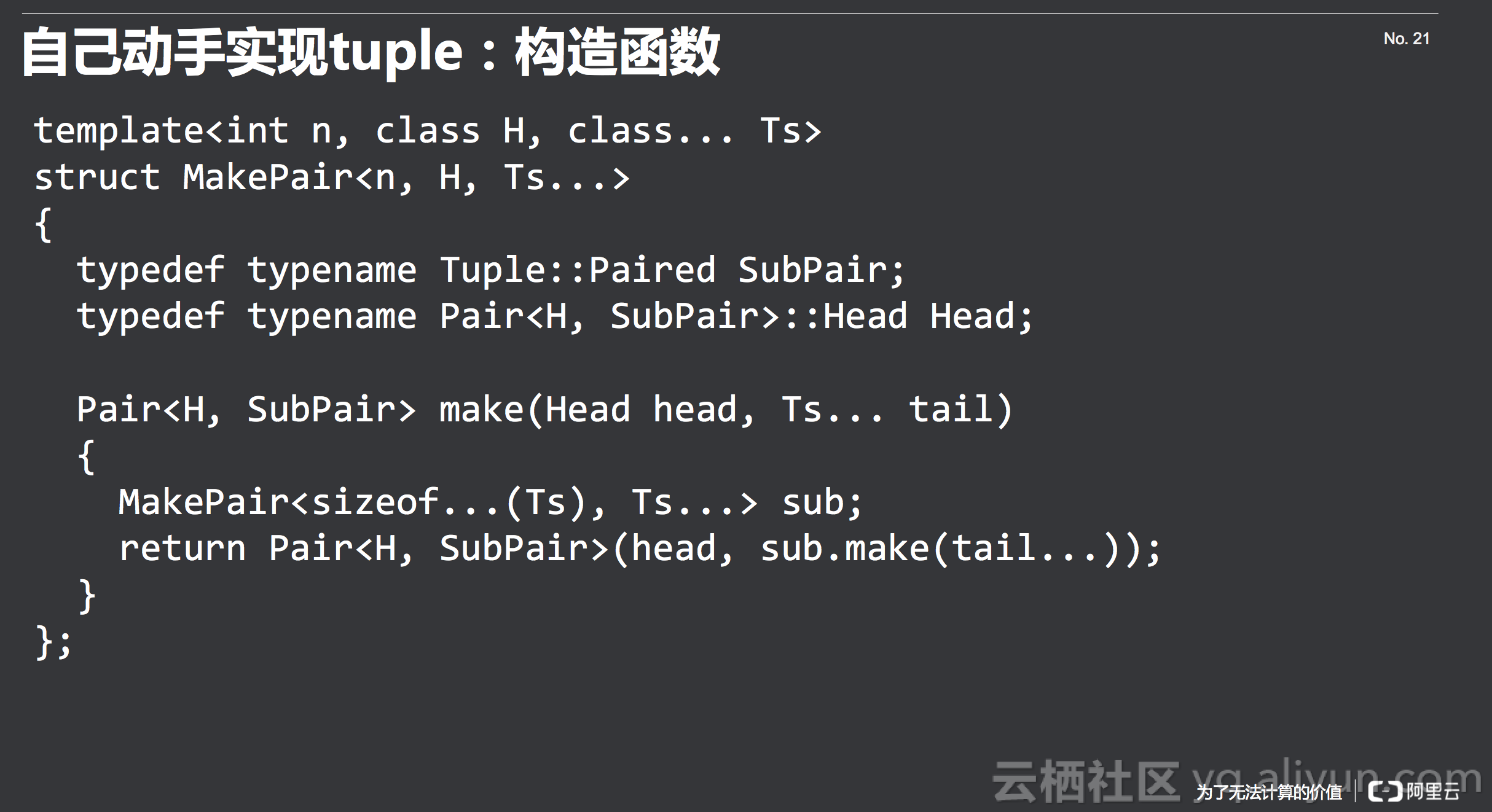
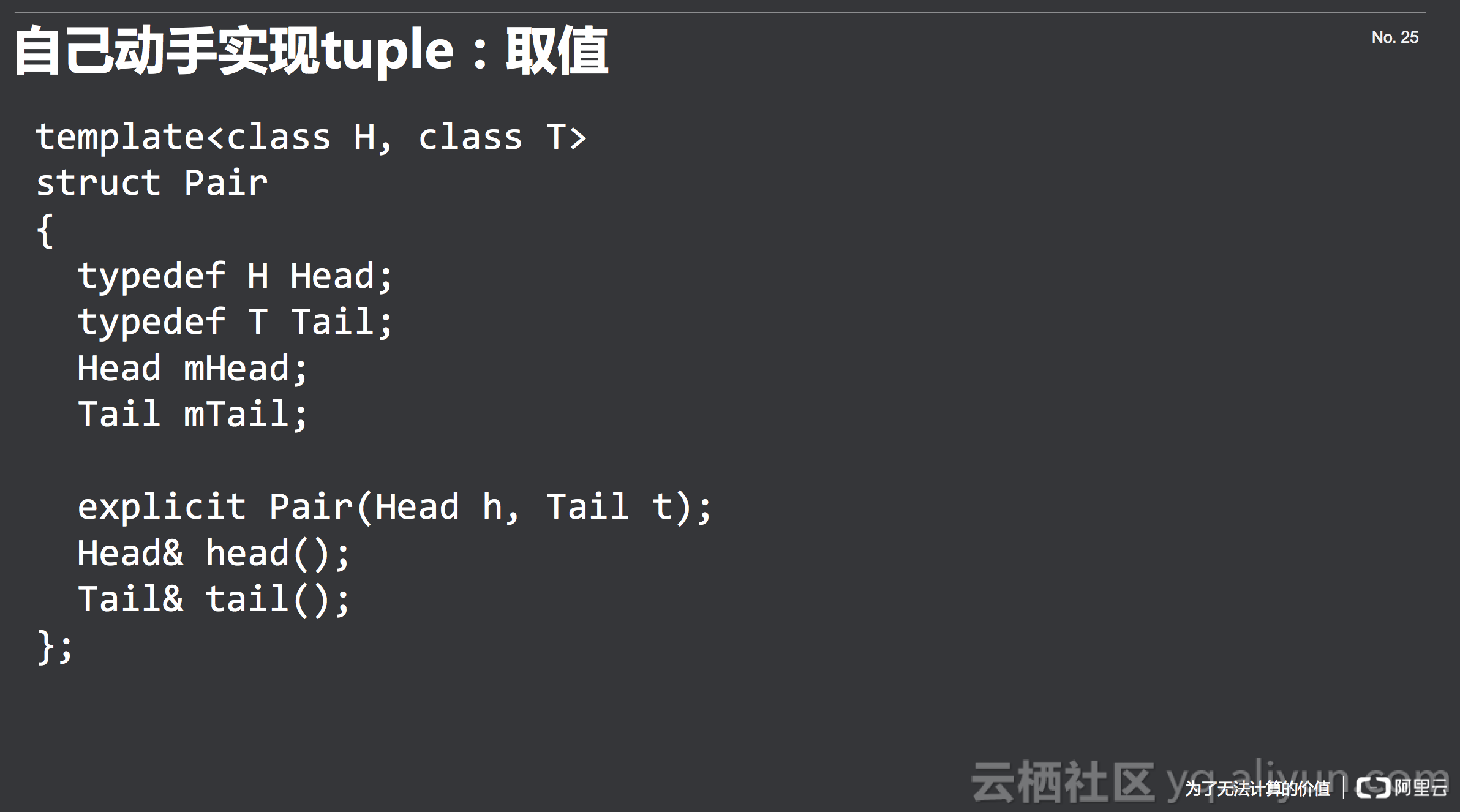
取值
接下来到取值的过程,怎么样实现fetch呢?首先声明一个二元的t,第一个是int,第二个是double,当然可以取第一个元素,也可以取第二个元素,我们现在取第二个元素,取出来的元素是一个引用,引用的是t本身的值。然后修改引用后,t的值也对应的改动了。最后我们要实现的功能和函数的接口是这样的。同样,我们将其最后转换成一个辅助类来做模板上的运算,这在刚才也是介绍过的。这个辅助类要做两件事情,第一件事情是把类型切出来,这里传入一个Tuple,有很多不同的类型,当我fetch<1>的时候,需要能返回相应的类型;第二件事情是要将对应的值取出来,要提供一个fetch的方法。
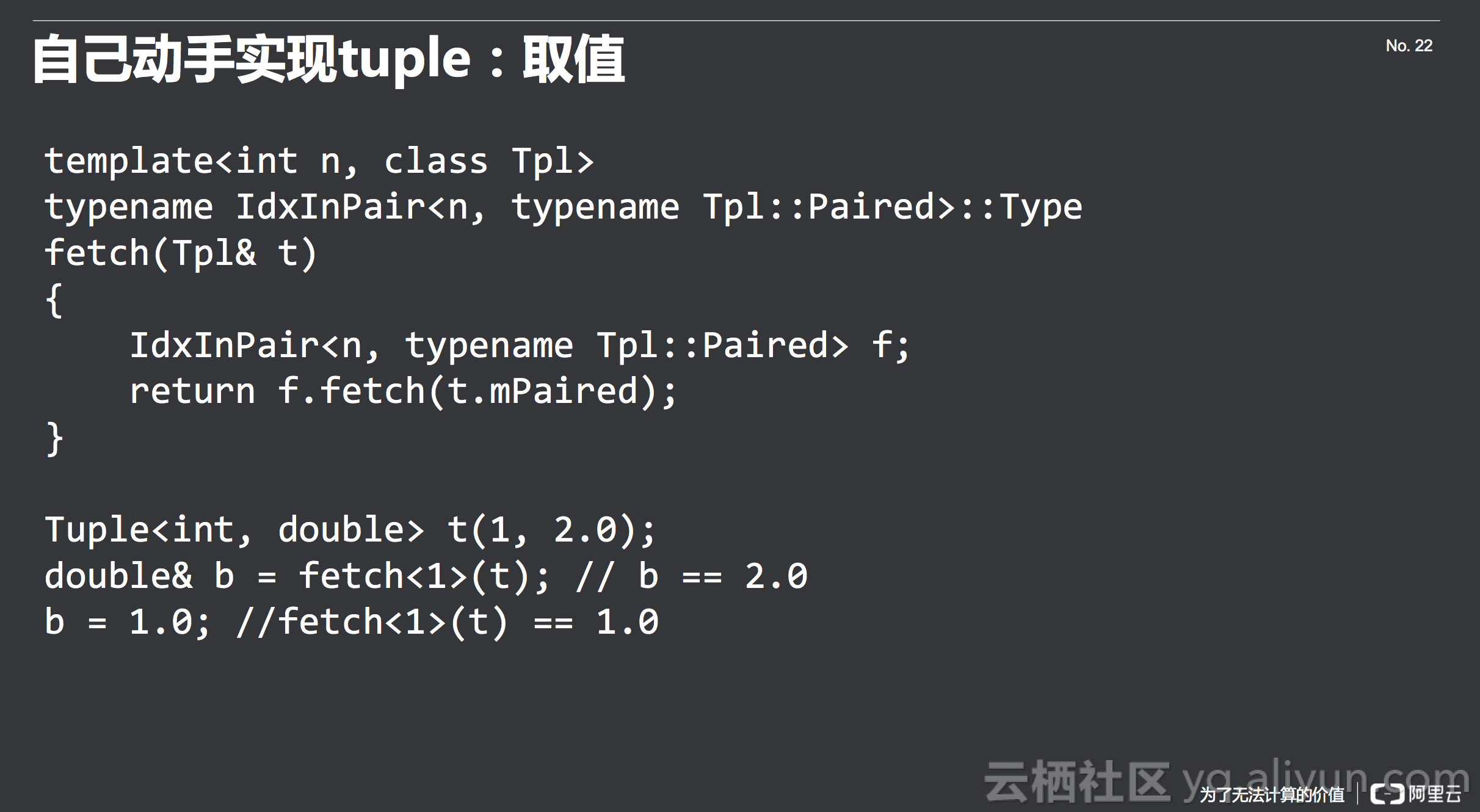
和刚才一样,来看一下递归的边界情况,是要取的下标为0的时候,将值丢出来,否则下标一路减下去,做fetch(n-1)。
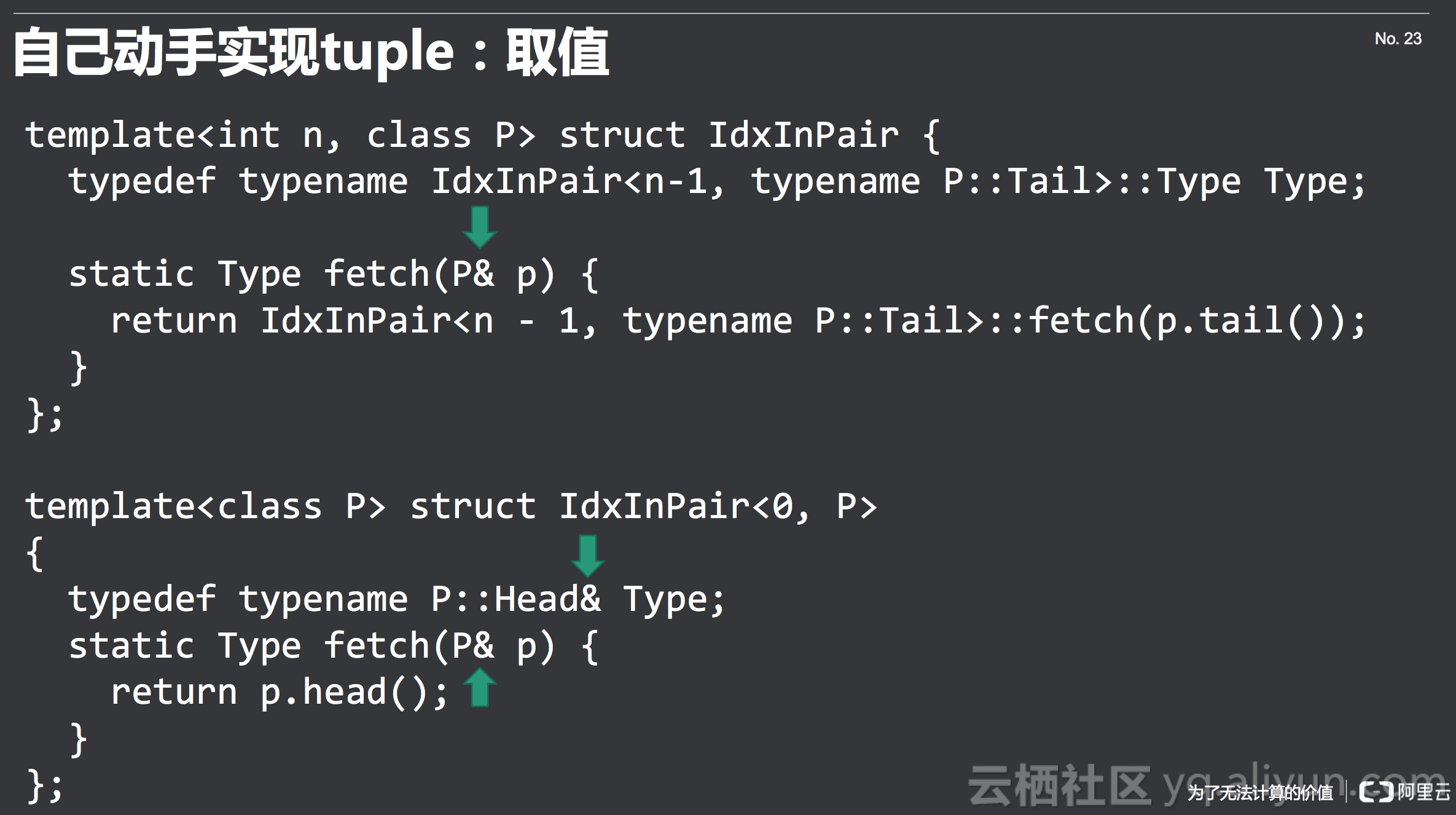
这时候我们可以看到pair就已经非常简单了,如下所示,不再细说。
三、总结
这节课的内容就到此为止,总结一下:
1)首先std::tuple是一个方便易用且久经考验的工具;
2)然后我们学习了模板元编程的一些技巧,尤其是Variadic Template。对于模板元编程,不管是不是Variadic Template,首要问题一定都是先搞清楚类型,类型梳理清楚了,类型上的运算做好了,后面便是水到渠成的;
3)C++的模板元编程可以看做是编译期的计算,从Length可以看出,C++的模板虽然仅仅是简单的擦除复写,但是配合constexpr evaluation,可以达到相当强大的计算能力;
4)C++ 11开始引入的新特性变长模板参数Variadic Template给C++带来更多的语言灵活性,只是需要牢记,pack过的类型/变量不是类型/变量。它只能做三件事情,第一件事情是将头切出来,第二件事情是算长度,第三件事情unpack。
本文由云栖志愿小组李杉杉整理,编辑百见

