定义
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
public abstract class AbstractMap<K,V> implements Map<K,V>
HashMap实现了Map接口,继承AbstractMap。其中Map接口定义了键映射到值的规则,而AbstractMap类提供 Map 接口的骨干实现,以最大限度地减少实现此接口所需的工作,其实AbstractMap类已经实现了Map。
数据结构
我们知道在Java中最常用的两种结构是数组和指针引用。实际上HashMap是一个“链表散列”,如下是它数据结构:
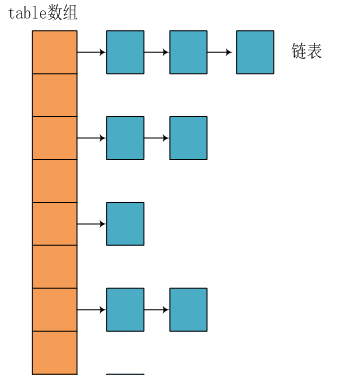
从上图我们可以看出HashMap底层实现还是数组,只是数组的每一项都是一条链。其中参数initialCapacity就代表了该数组的长度。下面为HashMap构造函数的源码://jdk7把有些过程方法put的时候去做了,在读写解析上会体现。
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init(); }
此段代码做了一些变量赋值和参数初始化,早期JDK给table赋值也是在构造器中的,即每次新建一个HashMap时,都会初始化一个table数组。table数组的元素为Entry节点。。
读写实现
public V put(K key, V value) { //jdk新版本,创建数组的时机在这了 if (table == EMPTY_TABLE) { inflateTable(threshold); } //hashmap允许放key为NULL的数据 if (key == null) return putForNullKey(value); //计算此key的hash值 int hash = hash(key); //根据hash值找到此key在数组的中下标 int i = indexFor(hash, table.length); //遍历此下标处的Entry链表 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果此key已存在则覆盖 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; //添加新key到此下标中 addEntry(hash, key, value, i); return null; } private void inflateTable(int toSize) { int capacity = roundUpToPowerOf2(toSize); threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); //此处表名HashMap是数组加链表的结构存储的 table = new Entry[capacity]; initHashSeedAsNeeded(capacity); } //key为NULL的值始终在数组下标0的位置 private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; } //计算hash值 final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } //通过hash值计算此key在数组中的下标 static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); } void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { //扩容数组,比较耗时 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); } //创建链表 void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; //把新加的放在原先在的前面,原先的是e,现在的是new,next指向e table[bucketIndex] = new Entry<>(hash, key, value, e);//假设现在是new size++; }
代码中很多思想用到了数学里的一些概念,为了性能优化数据分配平均和合理性的保证。譬如数组大小啥的,都用2的指数来玩,这方面不是很懂,就不献丑了。
下面的get代码比较好理解就不解释了。
public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); } final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
