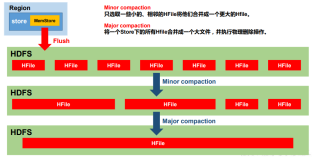
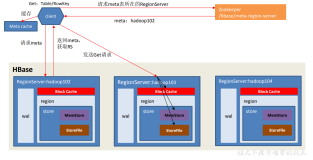
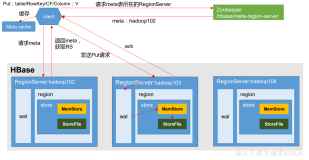
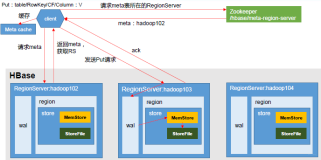
hbase scan客户端服务端流程
一:基础知识了解:
scanner可分为两种InternalScanner和KeyValueScanner,区别如下
1.InternalScanner,可以理解为包含其他scanner的scanner,它的主要接口为next(),作用是从其包含的scanner中获取下一个KeyValue,它的角色可以理解为雇佣KeyValueScanner
2.KeyValueScanner,从内存或文件中获取KeyValue的scanner,
大致:
scanner, RegionScanner、StoreScanner属于InternalScanner,
而MemstoreScanner、StoreFileScanner、StoreScanner属于KeyValueScanner
二:hbase中client端rpc服务定义:
service ClientService {
rpc Get (GetRequest) returns (GetResponse);
rpc Mutate (MutateRequest) returns (MutateResponse);
rpc Scan (ScanRequest) returns (ScanResponse);
rpc BulkLoadHFile (BulkLoadHFileRequest) returns (BulkLoadHFileResponse);
rpc ExecService (CoprocessorServiceRequest) returns (CoprocessorServiceResponse);
rpc ExecRegionServerService (CoprocessorServiceRequest) returns (CoprocessorServiceResponse);
rpc Multi (MultiRequest) returns (MultiResponse);
}
关于PB的rpc具体实现可以看源代码。
三:直接代码跟踪了解流程。scan-client客户端源码跟踪
从客户端scan-api代码开始:
table.getScanner(scan)
然后进入HTable的getScanner(final Scan scan)方法
if (scan.getBatch() > 0 && scan.isSmall()) {
throw new IllegalArgumentException("Small scan should not be used with batching");
}
if (scan.getCaching() <= 0) {
scan.setCaching(getScannerCaching());
}
if (scan.getMaxResultSize() <= 0) {
scan.setMaxResultSize(scannerMaxResultSize);
}
if (scan.isReversed()) {
if (scan.isSmall()) {
return new ClientSmallReversedScanner(getConfiguration(), scan, getName(), this.connection, this.rpcCallerFactory, this.rpcControllerFactory, pool, connConfiguration.getReplicaCallTimeoutMicroSecondScan());
} else {
return new ReversedClientScanner(getConfiguration(), scan, getName(), this.connection, this.rpcCallerFactory, this.rpcControllerFactory, pool, connConfiguration.getReplicaCallTimeoutMicroSecondScan());
}
}
if (scan.isSmall()) {
return new ClientSmallScanner(getConfiguration(), scan, getName(), this.connection, this.rpcCallerFactory, this.rpcControllerFactory, pool, connConfiguration.getReplicaCallTimeoutMicroSecondScan());
} else {
return new ClientScanner(getConfiguration(), scan, getName(), this.connection, this.rpcCallerFactory, this.rpcControllerFactory, pool, connConfiguration.getReplicaCallTimeoutMicroSecondScan());
}
根据不同条件执行不同操作,接着进入ClientScanner的构造函数中,
先是属性的取值;再是initializeScannerInConstruction();
进入initializeScannerInConstruction(),发现是一个nextScanner(this.caching, false),初始化scanner;
进接着进入nextscanner;
关闭之前的scanner;下个scanner开始key;判断是否在表的末尾;接着:
callable = getScannerCallable(localStartKey, nbRows);
// Open a scanner on the region server starting at the
// beginning of the region
call(callable, caller, scannerTimeout);
this.currentRegion = callable.getHRegionInfo();
if (this.scanMetrics != null) {
this.scanMetrics.countOfRegions.incrementAndGet();
}
生成一个ScannerCallableWithReplicas;
然后利用生成的ScannerCallableWithReplicas通过call函数用来在RS上的region的开始打开一个scanner,扫描数据
进入call方法:
try {
callable.prepare(false);
return callable.call(callTimeout);
}
请求由ScannerCallable.call()发起,
this.scannerId = openScanner();
ScanResponse response = getStub().scan(controller, request);
long id = response.getScannerId(); scannerID存在的话:
获取服务观返回的数据结果集:
response = getStub().scan(controller, request);
nextCallSeq++;
long timestamp = System.currentTimeMillis();
setHeartbeatMessage(response.hasHeartbeatMessage() && response.getHeartbeatMessage());
// Results are returned via controller
CellScanner cellScanner = controller.cellScanner();
rrs = ResponseConverter.getResults(cellScanner, response);
四:scan-server服务端源码跟踪
1.进入HRegion的getScanner(Scan scan, List<KeyValueScanner> additionalScanners, long nonceGroup, long nonce)开始
列族的判断添加及检查
然后返回初始化的RegionScanner: instantiateRegionScanner(scan, additionalScanners, nonceGroup, nonce);
实现在RegionScannerImpl中,初始化scanner
initializeScanners(Scan scan, List<KeyValueScanner> additionalScanners)
根据列族获取对应store:
Store store = stores.get(entry.getKey());
KeyValueScanner scanner;
try {
scanner = store.getScanner(scan, entry.getValue(), this.readPt);
} catch (FileNotFoundException e) {
throw handleFileNotFound(e);
}
instantiatedScanners.add(scanner);
if (this.filter == null || !scan.doLoadColumnFamiliesOnDemand() || this.filter.isFamilyEssential(entry.getKey())) {
scanners.add(scanner);
} else {
joinedScanners.add(scanner);
}
}
initializeKVHeap(scanners, joinedScanners, region);
通过memstore,snapshot,所有的storefiles打开一scanner,并且不处于compact情形;
然后为一个scan构造一个ScanQueryMatcher
然后根据ScanQueryMatcher执行
seekScanners(scanners, matcher.getStartKey(), explicitColumnQuery && lazySeekEnabledGlobally, parallelSeekEnabled);
包括定位起始row的所有scanner,布隆过滤器的检查删除标记等;
最后会将所有的scanner放入堆中;
2.接着对于客户端的scanner的next()函数服务端实现;
在storesanner中的next:
从store中获取下个row数据;
do {
// Update and check the time limit based on the configured value of cellsPerTimeoutCheck
if ((kvsScanned % cellsPerHeartbeatCheck == 0)) {
scannerContext.updateTimeProgress();
if (scannerContext.checkTimeLimit(LimitScope.BETWEEN_CELLS)) {
return scannerContext.setScannerState(NextState.TIME_LIMIT_REACHED).hasMoreValues();
}
}
if (prevCell != cell)
++kvsScanned; // Do object compare - we set prevKV from the same heap.
checkScanOrder(prevCell, cell, comparator);
prevCell = cell;
ScanQueryMatcher.MatchCode qcode = matcher.match(cell);
其中包含:MatchCode的状态 {
INCLUDE,
SKIP,
NEXT,
DONE,
SEEK_NEXT_ROW,
SEEK_NEXT_COL,
DONE_SCAN,
SEEK_NEXT_USING_HINT,
INCLUDE_AND_SEEK_NEXT_COL,INCLUDE_AND_SEEK_NEXT_ROW;
} while ((cell = this.heap.peek()) != null);
if (count > 0) {
return scannerContext.setScannerState(NextState.MORE_VALUES).hasMoreValues();
}
// No more keys
close();
return scannerContext.setScannerState(NextState.NO_MORE_VALUES).hasMoreValues();
最终返回匹配的resultsanner,中间含有数据结果集;