分层持久存储
超融合是指在同一套单元设备(x86服务器)中不仅仅具备计算、网络、存储和服务器虚拟化等资源和技术,而且还包括云管理软件,数据重构,多副本,快照技术等元素,而多节点可以通过网络聚合起来,实现模块化的无缝横向扩展,形成统一的资源池。与传统存储方案相比,超融合存储弥补了传统存储横向扩展能力不足的问题。
众所周知,相较于传统的机械硬盘,SSD 具有很好的弹性,并提供对数据的快速访问,但其拥有写入次数限制。结合两者的优缺点,联想超融合存储系统采取SSD+HDD的混合存储方式,将所有物理服务器上的硬盘组成一个存储资源池。其中所有机械硬盘组成存储容量层,SSD闪存盘组成存储性能层,两者一起构建了分层持久存储。(TPC:Tiered Persistence Store)
联想超融合存储把混合存储成本效益最大化,最大限度地提高性能。LHS从数据中分离出元数据,为实际的数据提供关键信息,并将元数据存储在高性能设备中(SSD),这种方式大大加速了元数据的读取和写入操作。
SSD存储了一些关键的组件,包括:LHS Home(VSC虚拟存储控制器核心)、Metadata(元数据)、OpLog(写缓存)、Cache(缓存)和Persistence Store(持久存储)。下图展示了SSD的存储分解:
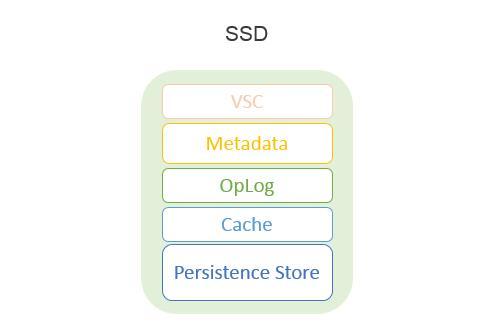
HDD只作用于持久存储,分解更简单:

数据分片存储
联想超融合系统利用分片机制来解决单个服务器不能满足的大量数据存储和大吞吐量的系统读写等问题。分片是一种水平扩展方式,把一个大的数据集分散到多个服务器上,所有的服务器将组成一个逻辑上的数据库来存储这个大的数据集。分片对用户是透明的。
数据从虚拟机的文件系统写入物理存储设备时,分片机制会涉及到如下概念:block、object。block 是一块磁盘当中最小的单位,其大小取决于不同的操作系统。一个object由n个连续的block组成,并被保存在磁盘上。
下图展示了文件写入物理存储设备时各部分的组成关系:
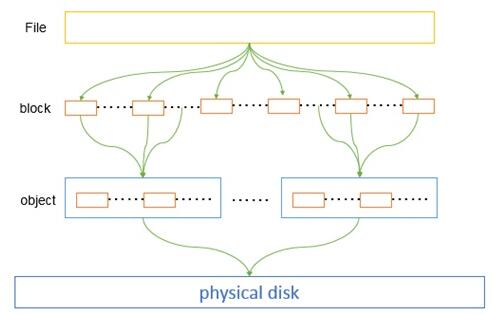
如上图,虚拟机上的文件系统写入物理存储设备时,文件被磁盘的最小单位block所划分,n个连续的block又组成一个object,并直接存入磁盘。
数据多副本机制
联想超融合存储使用复制因子(RF:Replication Factor)来保证当节点或硬盘失效时,数据的冗余度和可用性。当数据写入本地TPS时,数据被同步复制到另1个或者2个节点(取决于RF设置),当这个操作完成后,此处写操作才被确认(Ack),以此来保证数据至少存在于2个或3个独立的节点上,保证数据的冗余度。
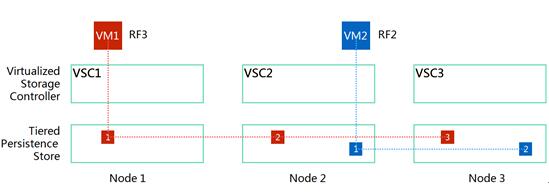
多副本机制
在同一集群中可以为不同的工作负载配置不同的容错等级(RF1/2/3…)。当RF=1时,表示系统中仅有1个副本,则系统不能承受任何节点或硬盘故障;当RF=2时,表示系统中有2个副本,即系统可以承受一个节点或硬盘故障;同理,RF=n时,表示系统中有n个副本,即系统可以承受n-1个节点或硬盘故障。
联想超融合存储具有硬盘/节点/机柜的感知能力,以此来保证最大的可用域,尽可能的把多个副本分散到多个硬盘/节点/机柜,提供硬盘级、节点级、机柜级的高可用。一般来说,随着集群规模的增长,具有多个机架时,才会提升到机柜感知,尽可能的把副本分散到多个机柜。
联想超融合存储还具有系统自我修复能力,无需运维人员介入。当发生节点或硬盘失效时,且RF>1时,可用数据块会重新在所有节点间进行复制,以满足RF的设置。
关于联想超融合
联想超融合,是利用分布式存储和计算虚拟化技术整合服务器集群、对外提供计算、存储和网络等资源的IT基础架构。联想超融合简化客户的IT基础设施建设、降低硬件配置和管理成本以及基础设施交付成本,同时改善系统平台的可靠性,提供水平扩展的能力,帮助客户大幅度降低各种规模数据中心的复杂性。联想超融合在虚拟化和分布式存储领域有超过十年的技术储备,积累了全球70多项国际技术专利。
联想作为中国超融合联盟的发起者和第一届理事长单位,将致力于推进超融合市场的发展和成熟,引领互联网时代IT架构的革新。目前,联想超融合在医疗、政府、教育、企业中有着广泛的应用,未来,联想超融合解决方案将继续凭借持续的技术创新和深入的行业洞察,为合作伙伴和客户提供更优质、更有针对性的全新IT体验。



