

在分布式系统中,有效应对节点故障、网络分区延迟和数据一致性等挑战至关重要。本文将剖析保障分布式系统可靠性的核心机制:数据分片实现水平扩展,冗余副本保障数据高可用,租约(Lease)机制优化节点状态共识与资源管理,多数派(Quorum)原则确保操作的一致性,Gossip等去中心化协议高效同步集群状态。这些成熟机制为构建稳健、高效的分布式系统提供了方法论支撑。
分布式系统
任何计算机系统都需要完成两项基本任务,即计算(Computation)和存储(Storage)。问题始于处理规模的需要,大多数事情在小规模上都是微不足道的——一旦超过了一定的大小、体积或其他物理受限的东西,同样的问题就会变得更加困难。 当数据量级攀升至亿万级别,并发请求激增时,单个计算或存储节点的物理极限便会凸显。此时,无论如何优化单点性能,也难以独立承载如此巨大的处理需求。
假设拥有无限的资源(如资金、人员、研发时间等),那么理论上所有的计算和存储任务都可以在一个单一的高性能、高可靠节点上完成。然而,现实世界中资源总是有限的,因此必须在成本与收益之间找到最佳平衡点。在小规模场景下,通过纵向扩展(Scale-up),即升级单个节点的硬件,是一种直接的策略。但随着规模的持续增长,硬件升级会遭遇瓶颈:要么不存在满足需求的单点硬件,要么其成本高昂到不切实际。
为突破单点瓶颈,分布式系统(Distributed System) 应运而生。它通过将庞大的计算或存储任务分解,并将其分散到由网络连接的多个独立计算节点(通常是商用计算机)集群上协同处理。这种横向扩展(Scale-out)的方式,通过聚合众多节点的计算和存储能力以应对大规模问题。
从本质上看,分布式系统可以视为操作系统中计算与存储管理理论在多节点协作环境下的延伸和扩展。操作系统在单机内管理进程、线程、内存、文件系统等资源;而分布式系统则在此基础上,引入了跨节点的数据分片、任务调度、一致性协议、容错机制等复杂问题。
单机性能与整体性能的关系
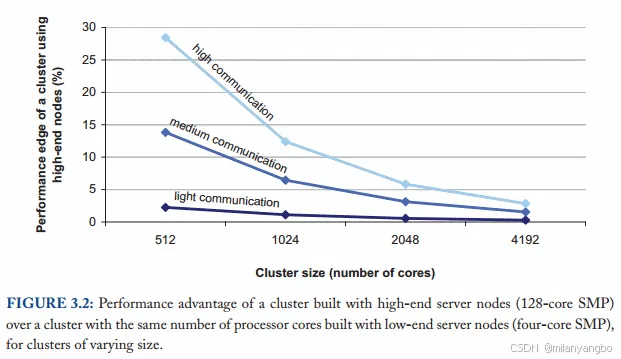
数据显示,当集群规模较小时,采用高性能硬件能够显著提升系统的整体性能。然而,随着集群规模的持续扩大,高端硬件带来的边际效益会逐渐递减,其与普通商用级硬件在集群整体性能上的差距会缩小。
从理论上讲,理想情况下,每增加一台机器,分布式系统的计算和存储能力应能够线性增长。然而,实际情况远非如此。
1)网络开销与协调开销: 在大规模集群中,数据需要在不同节点间网络传输,任务的执行需要跨节点协调。这些通信和同步的开销往往成为新的瓶颈,而非单个节点的计算能力。即使计算和存储在同一节点,进程间的协调也会引入开销。
2)Amdahl定律的启示: 系统整体性能的提升受限于系统中无法并行化部分的比例。在分布式系统中,串行部分(如某些一致性协议的决策阶段、共享资源的争用)会限制并行带来的收益。
3)成本效益: 高端硬件成本高昂。采用性价比更高的中档商用级硬件,结合精心设计的容错机制,通常能以更低的总体拥有成本(Total Cost of Ownership,TCO)获得理想的系统性能和可靠性。
因此,现代分布式系统设计倾向于使用大量相对廉价的商用硬件,依赖软件层面的智能调度和容错机制来保证系统的整体表现。
节点
在分布式系统中,节点是指一个能够独立执行特定逻辑功能的程序实体。在工程实践中,一个节点通常对应一个操作系统上的进程,它承载一组明确定义的任务,如数据存储、计算处理、元数据管理等。一个进程通常被视为一个逻辑上不可分割的节点单元。
然而,若一个进程内部包含多个高度独立、可分别承担不同角色的组件,从架构设计的角度,有时也会将其细化为多个逻辑节点,即使它们物理上运行在同一个进程或机器内。
拜占庭问题
拜占庭问题(Byzantine Problem)是分布式系统中的一个经典难题,由Leslie Lamport等人在1982年提出。其名称源于一个比喻:拜占庭帝国的多位将军率军围攻一座城市,需通过信使来协商进攻或撤退的策略。然而,将军(节点)中可能存在叛徒,发送错误消息(甚至恶意信息)以破坏计划。问题的核心在于,如何在存在叛徒的情况下,让忠诚的将军们达成一致并执行正确决策。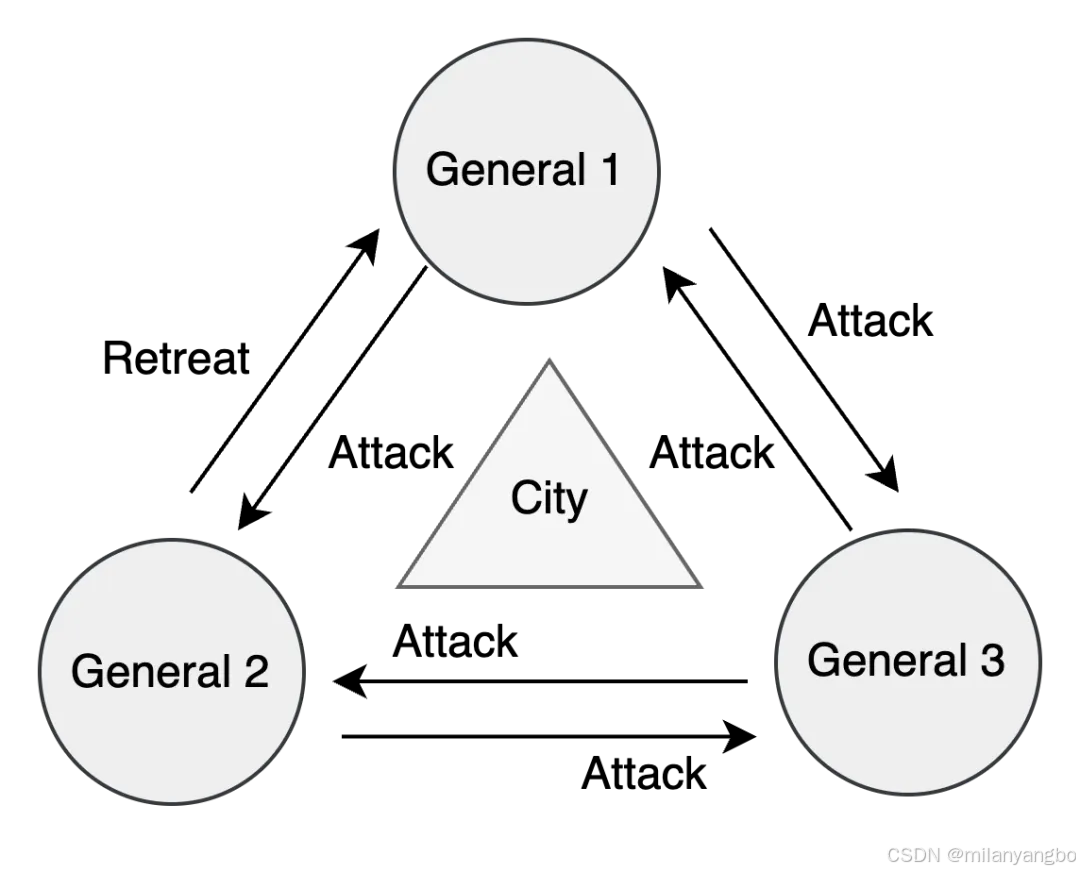
在分布式系统中,这种发送任意错误、不一致或恶意数据的节点故障被称为拜占庭故障(Byzantine Fault)。解决此类问题的算法统称为拜占庭容错(Byzantine Fault Tolerance, BFT) 算法,其中最著名的实用算法是PBFT (Practical Byzantine Fault Tolerance)。BFT算法通常要求在总共 N 个节点中,恶意节点的数量 f 必须小于 N/3(即 N ≥ 3f+1),才能保证系统正确达成共识。这类算法因其高昂的通信开销(通常需要多轮消息交换和数字签名)和复杂性,性能相对较低。
拜占庭问题在对安全性要求极高的领域至关重要,例如航空航天、金融交易以及区块链技术。比特币的工作量证明(Proof of Work, PoW) 和以太坊等采用的权益证明(Proof of Stake, PoS) 等共识机制,其本质上都是为了在开放、无需信任的环境中解决拜占庭问题,确保全网对交易记录的一致性和不可篡改性。
崩溃故障
在许多常见的分布式应用场景中,尤其是在受控的企业内部环境(如私有云、公司数据中心),节点通常被认为是“诚实但可能出错”的。这意味着节点不会故意发送错误或矛盾的信息,它们可能发生的故障主要是崩溃故障(Crash Fault),即节点突然停止工作并不再响应。这种简化的故障模型允许使用更高效的容错机制。
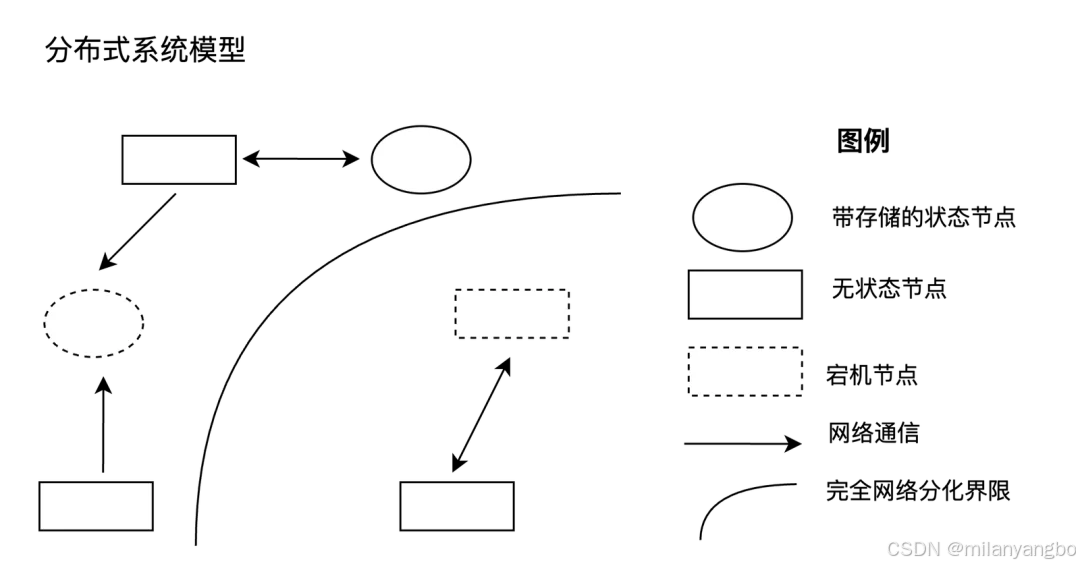
针对崩溃故障的容错设计,即崩溃故障容错(Crash Fault Tolerance, CFT),它涉及处理分布式系统的各种异常(Failure)情况。
1)不可靠网络与分布式三态:当节点A向节点B发起远程过程调用(RPC)后,在预设时间内未收到响应,节点A无法确定节点B是否已处理该请求。RPC的执行结果存在三种状态:“成功”、“失败”、“超时(未知)”,称之为分布式系统的三种状态。
这种不确定性是分布式编程的主要难点之一。最简单的做法是,将执行步骤设计为可重试的,即具有所谓的幂等性(Idempotence)。幂等操作是指无论执行一次还是多次,其产生的效果都相同。例如,覆盖写(SET key = value)是幂等的;基于唯一ID的创建操作(CREATE IF NOT EXISTS item_id)也是幂等的。通过重试超时的幂等操作,可以简化错误处理逻辑。
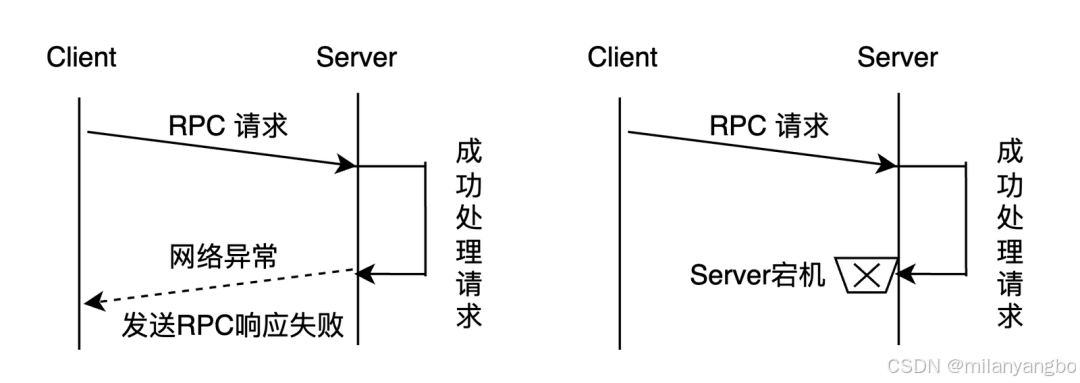
2)节点故障:虽然单个节点的平均无故障时间(Mean Time Between Failure,MTBF)可能较长,但在拥有成百上千个节点的集群中,节点故障成为常态事件(所谓“墨菲定律”的体现)。系统必须能够自动检测到故障节点,并将其负责的计算和存储任务平滑地迁移到其他健康节点。
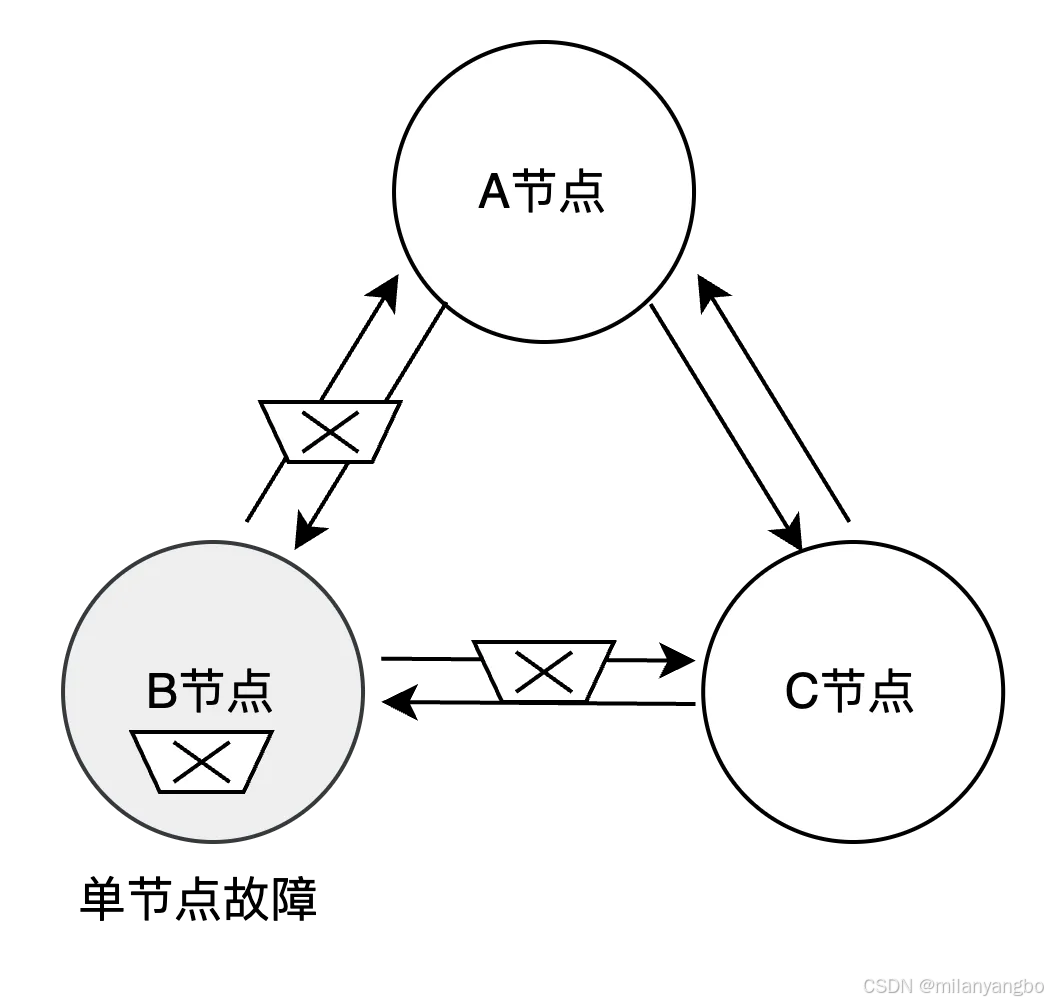
3)数据丢失:节点存储的数据可能因硬件损坏(尤其是机械硬盘)、软件缺陷或操作失误而变得不可读或数据错误。对于有状态服务而言,数据丢失意味着状态丢失。
4)时钟偏移:分布式系统中的每个节点都拥有独立的物理时钟。由于硬件差异、温度变化、网络同步(Network Time Protocol,NTP)的精度限制等因素,这些本地时钟之间难以完全同步,会产生时钟偏移。这给确定跨节点事件的全局偏序关系带来了挑战,可能导致逻辑错误。
总而言之,分布式系统的核心挑战源于各种异常带来的不确定性,而系统的规模会显著放大这种不确定性发生的概率和影响。研究和应用成熟的分布式算法与协议,不仅为具体问题提供了行之有效的解决方案,更重要的是,它们揭示了在特定约束条件下什么是可能实现的、正确实现的最小代价是什么,以及哪些目标是理论上不可达的。
未完待续
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!!!



