语法分析
记号流=》语法分析器=》语法树
if ((x > 5) y = "hello" else z = 1 ,
上述代码执行之后应该报错
Syntax Error : line 1, missing ) Syntax Error : line 2, missing ; Syntax Error : line 4, expecting ; but got ,
- 语法树的构建
上代码可以表现成如下语法树

路线图
- 数学理论:上下文无关文法(CFG)
- 描述语言语法规则的数学工具
- 自顶向下分析
- 递归下降分析算法(预测分析算法)
- LL分析算法
- 自底向上分析
- LR分析算法
上下文无关文法
- 上下文无关文法G是一个四元组 G = (T, N, P, S)
- 其中T是终结字符集合
- N是非终结字符集合
- P是一组产生式规则
- S是唯一的开始符号(非终结符)
推导
- 给定文法G,从G的开始符号S开始,用产生式的右部替换左侧的非终结符
- 此过程不断的重复,知道不出现非终结符为止
- 最终的串称为句子
最左推导和最右推导
- 最左推导:每次都是选择最左侧的符号进行替换
- 最右推导:每次都是选择最右侧的符号进行替换
给定文法G和句子S,语法分析要回答的问题:是否存在对句子S的推导?
分析树和二义性
分析树
- 推导可以表达成树状结构
- 和推导所有的顺序无关
- 特点
- 树的每个内部节点代表非终结符
- 每个叶子节点代表终结符
- 每一步推导代表如何从双亲节点生成它的直接孩子节点
分析树的含义取决于树的后续遍历
二义性文法
- 给定文法G,如果存在句子S,他有两颗不同的分析树,那么称G是二义性文法
- 从编译器角度,二义性文法存在问题:
- 同一个程序会有不同的含义
- 因此程序运行的结果不是唯一的
- 解决方案:文法重写 - 具体问题具体分析
自定向下分析的算法
- 基本算法思想:从G的开始符号出发,随意推导出某个句子t,比较t和s
- 若t==s则回答是
- 拖t!=s则?
因为这是从开始符号出发推出句子,因此称为自顶向下分析
- 对应于分析树自顶向下的构造顺序
算法的讨论:
- 算法需要用到回溯
- 给分析效率带来问题
- 而就这部分而言,编译器必须高效
- 编译上千万行的内核等程序
- 因此,实际上我们需要线性时间算法
- 避免回溯
- 用前看符号避免回溯
- 引出递归下降分析算法和LL(1)分析算法
递归下降分析算法
- 也被称为预测分析
- 分析高效 - 线性时间
- 容易实现 - 方便手工编码
- 错误定位和诊断信息准确
- 被很多开源和商业的编译器所采用
- 算法的基本思想
- 每个非终结符构造一个分析函数
- 用前看符号指导产生规则的选择
一般算法框架
parse_x() token = nextToken() switch (token) case ...: ... default : error("...");
LL(1)分析算法
- 从左(L)向右读入程序,最左(L)推导,采用一个(1)前看符号
- 分析高效
- 错误定位和诊断信息准确
- 以后很多开源或者商业的生成工具:antlr,bison等
- 算法基本思想
- 表驱动分析算法
表驱动分析算法
FIRST集
FIRST[N] = 从非终结符N开始推导得出句子开头的所有可能终结符的集合
foreach (nonterminal N) FIRST(N) = {} while(some set is changing) foreach(productuon p : N->β1...βn) if(β1 == a) FIRST(N) U= {a} if(β1 == M) FIRST(N) U= FIRST(M)
构造LL(1)分析表
使用句子的每个非终结符规则的变化填写到表汇总
冲突检测:如国对N的两条产生式规则N=》β和N到γ,要求FIRST_S(β)∩FIRST_S(γ) = {}
一般条件分析表构造
- FIRST_S(X Y Z)
- 一般情况下需要知道某个非终结符是否可以推出空串
- NULLABLE
- 并且需要知道在某个非终结符号后面跟的是什么符号
- 跟随集FOLLOW
NULLABLE集合
- 当终结符X属于NULLABLE,当且仅当:
- 基本情况
- X=>
- 归纳情况
- X=>Y1…Yn
- Y1…Yn是n个非终结符,且都属于NULLABLE集合
FOLLOW集合不动点算法
foreach (nonterminal N) FOLLOW(N) = {} while (some set is changing) foreach (productuin p : N->β1...βn) temp = FOLLOW(N) foreach(βi form βn downto β1) if(βi == a) temp = {a} if(βi == M) FOLLOW(M) U= temp if(M is not NULLABLE) temp == FIRST(M) else temp U= FIRST(M)
FIRST集完整计算公式
- 基于归纳的计算规则
基本情况
X=》a FIRST(X) U= {a}
归纳情况
X=》Y1…Yn
FIRST(X) U= FIRST(Y1)
if(Y1 ∈ NULLABLE) FIRST(X) U= FIRST(Y2)
if(Y1 Y2 ∈ NULLABLE) FIRST(X) U= FIRST(Y3) …以此类推
自底向上分析算法
- LR(0)分析算法
- 算法运行高效
- 有现成的工具可以使用
- 这也是目前应用最广泛的一类语法分析器的自动生成器中采用的算法
- YACC,Bison,CUP,C#yacc等
LR(0)分析算法
- 从左向右读入程序,最右推导,不用前看符号来决定产生式的选择
优点:容易实现
缺点:能分析的文法有限
对每个X=》 α .的项目
直接把α归约为X,紧跟一个goto
尽管不会漏掉错误,但是会延时错误发现时机
LR(0)分析表中可能包含冲突
SLR分析算法
- 基于LR(0),通过进一步判断一个前看符号,来决定是否执行归约动作
- X=》α.归约,当且仅当y∈FOLLOW(x)
- 优点:
- 有可能减少需要归约的情况
- 可能去除需要移进-归约冲突
- 缺点
- 仍然有冲入出现的可能
对二义性文法处理
- 二义性文法无法使用LR分析算法分析
- 不过,有几类二义性文法很容易理解,因此在LR分析器生成工具中,可以对他们特殊处理
- 优先级
- 结合性
- 悬空else
- …等
语法分析器的实现方法
- 手工方式
- 递归下降分析器
- 使用语法分析器自动生成器
- LL(1),LR(1)等
- 两种方式在实际编译器中都有广泛的应用
- 自动的方式更适合快速对系统进行原型
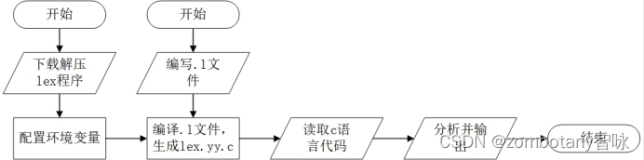
YACC的使用
%{ #include <stdio.h> #include <stdlib.h> int yylex(); void yyerror(); %} %left '+' %% lines: line | line lines ; line: exp '\n'; exp:n | exp '+' exp ; n: '1' | '2' | '3'; %% int yylex() { return getchar(); } void yyerror(char *s) { fprintf(stderr, "%s\n", s); return; } int main(int argc, char **argv) { yyparser(); return 0; }
使用bison 编译该文件
之后使用gcc编译生成的c代码