EVA存储结构&原理:
EVA是虚拟化存储,在工作过程中,EVA存储中的数据会不断地迁移,再加上运行在EVA上的应用都比较繁重,磁盘负载高,很容易出现故障。EVA是通过大量磁盘的冗余空间和故障后rss冗余磁盘动态迁移保护数据。但是如果磁盘掉线数量到达一个临界点,EVA存储就会崩溃。
EVA存储内部的结构组成不同于普通的基于RAID的存储,内部称之为VRAID。
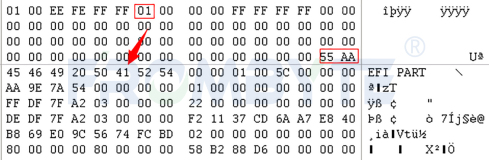
EVA对每个物理磁盘(PV)进行签名(写在每个磁盘的0扇区),签名后将物理磁盘分配到不同的DISK GROUP。在DISK GROUP中,每个PV会按一定大小划分为若干存储单元(PP),PP的大小为2的整数次幂,大小在2-16M之间。
每个PV中有一定数量的PP,这些PP一起形成整个DISK GROUP的可用空间。
所有的PV按照5-15的数量组成若干组RSS,每组RSS就是一个冗余组,但RSS不等同于常规RAID。常规RAID是基于磁盘的RAID算法,而RSS是基于PP的RAID算法。
为提高性能,EVA存储会有倾向地轮流分配不同的RSS组,这些RSS之间的数据存储是基于JBOD的,每个RSS组成的stripe的成员是不同PV中不同位置的PP。
无论RSS中成员数量有多少个,对于VRAID5,一个stripe中的PV数总是5个;对于VRAID6,一个stripe中的PV数总是6个。
当一个RSS中某个PV离线,控制器会从同一个RSS组中其他磁盘中寻找可用的PP,在逻辑上实现每个stripe的rebuild,从而保证整个存储的安全性。
当一个RSS中损坏的磁盘数量少于等于6个的时候,EVA会合并此RSS到另一个RSS中,这样可用的冗余空间就是共享的了,空间就可以从另一个较安全的RSS中迁移过来。
为了保证有足够的空间提供冗余保护,在创建DISK GROUP时,EVA会提供一个Protection Level的保护级别:single表示用2个磁盘的空间做冗余,double表示用4个磁盘的空间做冗余,但这个冗余不同于hotspare,这个冗余空间仅会预留到每个PV的尾部。
EVA存储常见故障:
1、RSS中多个磁盘掉线,超过冗余保护级别。
2、加入新磁盘迁移数据时,新磁盘存在物理故障。
3、删除VDISK或EVA初始化。
4、主机与存储无法连接。
EVA存储数据恢复原理:
EVA存储核心结构部分来自于所有vdisk的运算pp map表,这个pp map表会因为磁盘的不断迁移而迁移,所有故障均可通过此map表恢复。
如果pp map表不存在,根据不同的条带之间的冗余关系,可通过优化算法对所有PP进行条带性集合,形成若干组正确的条带数据,然后基于文件系统结构、数据结构等特征重组若干条带。
EVA存储数据恢复方案:
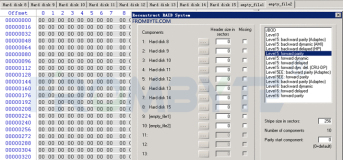
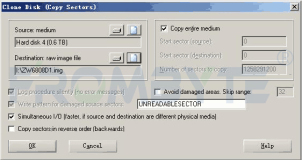
1、将EVA主机一端的连线拔出,直接接到主机hba卡上,认出所有物理硬盘。将磁盘以只读方式做完整镜像(eva主机与扩展柜之间多是铜线连接,可能需要在扩展柜上增加光纤收发模块,再通过光链路接到hba卡上。也可以将所有硬盘拆下来放入其他光纤通道柜中进行镜像)。
使用EVA扩展柜进行镜像:
2、通过北亚企安自主研发的frombyte recovery for hp eva程序重组vdisk,直接写入成镜像文件或目标物理磁盘。
3、解释镜像文件或目标磁盘,然后迁移镜像或导出内部文件。