C生万物 | 从浅入深理解指针【最后部分】(一):https://developer.aliyun.com/article/1426836
字符数组
- 接下来我们来看字符数组
int main() { char arr[] = { 'a','b','c','d','e','f' }; printf("%d\n", sizeof(arr)); printf("%d\n", sizeof(arr + 0)); printf("%d\n", sizeof(*arr)); printf("%d\n", sizeof(arr[1])); printf("%d\n", sizeof(&arr)); printf("%d\n", sizeof(&arr + 1)); printf("%d\n", sizeof(&arr[0] + 1)); return 0; }
- 数组名单独放在了sizeof内部,计算的是整个数组的大小,字符有6个,所以结果就是
6
printf("%d\n", sizeof(arr));
- arr是数组首元素的地址,arr+0 还是首元素的地址 是地址大小就是
4/8个字节
printf("%d\n", sizeof(arr + 0));
- arr是数组首元素的地址,*arr就是首元素,就占一个字符大小就是
1个字节
printf("%d\n", sizeof(*arr));
- arr[1]就是数组的第二个元素,大小是1个字节
printf("%d\n", sizeof(arr[1]));
- &arr 是数组的地址,数组的地址也是地址,大小就是
4/8
printf("%d\n", sizeof(&arr));
- &arr+1 是跳过整个数组,指向f的后面
4/8
printf("%d\n", sizeof(&arr + 1));
- &arr[0]是首元素的地址,&arr[0]+1就是第二个元素的地址
4/8
printf("%d\n", sizeof(&arr[0] + 1));
- 我们来看32平台下

- 再来看64位平台下的

- 我们继续来看第二个
char arr[] = { 'a','b','c','d','e','f' }; printf("%d\n", strlen(arr)); printf("%d\n", strlen(arr+0)); printf("%d\n", strlen(*arr)); printf("%d\n", strlen(arr[1])); printf("%d\n", strlen(&arr)); printf("%d\n", strlen(&arr+1)); printf("%d\n", strlen(&arr[0]+1));
- 这个数组是没有\0的,strlen是计算
\0之前的元素个数所以就是随机值
printf("%d\n", strlen(arr));
- 这个数组名也是首元素的地址,+0也就相当于没有加,结果是
随机值~~
printf("%d\n", strlen(arr+0));
- 这里arr是首元素的地址,然后*arr解引用就是字符
a,ASCLL码值是97,97传给strlen,会把97当成个地址,会非法访问,结果会报错
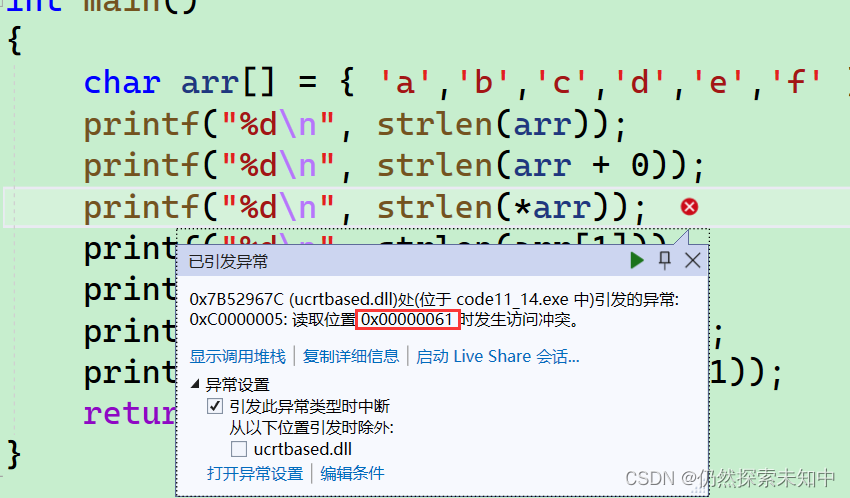
printf("%d\n", strlen(*arr));
- 这个代码与上个代码相似,访问的是第二个元素的ASCLL码值,会当地址传过去,也会
报错
printf("%d\n", strlen(arr[1]));
- &arr就是取出这个数组的地址,也就是起始位置向后数,结果也是
随机值
printf("%d\n", strlen(&arr));
- 这个&arr就是首元素的地址,然后+1,跳过整个数组的地址,内存放的什么也不知道,结果也就是
随机值
printf("%d\n", strlen(&arr+1));
- &arr[0]是首元素的地址,+1就是第二个元素的地址,然后向后数,结果也是
随机值
printf("%d\n", strlen(&arr[0]+1));

- 这里我们初始化
abcdef\0,这里面有\0~~
char arr[] = "abcdef"; printf("%d\n", sizeof(arr)); printf("%d\n", sizeof(arr+0)); printf("%d\n", sizeof(*arr)); printf("%d\n", sizeof(arr[1])); printf("%d\n", sizeof(&arr)); printf("%d\n", sizeof(&arr+1)); printf("%d\n", sizeof(&arr[0]+1));
- 这里算的是arr元素的大小,结果是
7
printf("%d\n", sizeof(arr));
- arr表示数组首元素的地址,arr + 0 还是首元素的地址,大小就是
4/8个字节
printf("%d\n", sizeof(arr+0));
- arr表示数组首元素的地址,*arr就是首元素,大小就是
1字节
printf("%d\n", sizeof(*arr));
- arr[1]是第二个元素,大小也是
1字节
printf("%d\n", sizeof(arr[1]));
- &arr是数组的地址,但是也是地址,是地址大小就是
4/8个字节
printf("%d\n", sizeof(&arr));
- &arr是数组的地址,&arr+1就是跳过整个数组的那个地址,结果是
4/8个字节
printf("%d\n", sizeof(&arr+1));
- 第二个元素的地址,大小
4/8个字节
printf("%d\n", sizeof(&arr[0]+1));
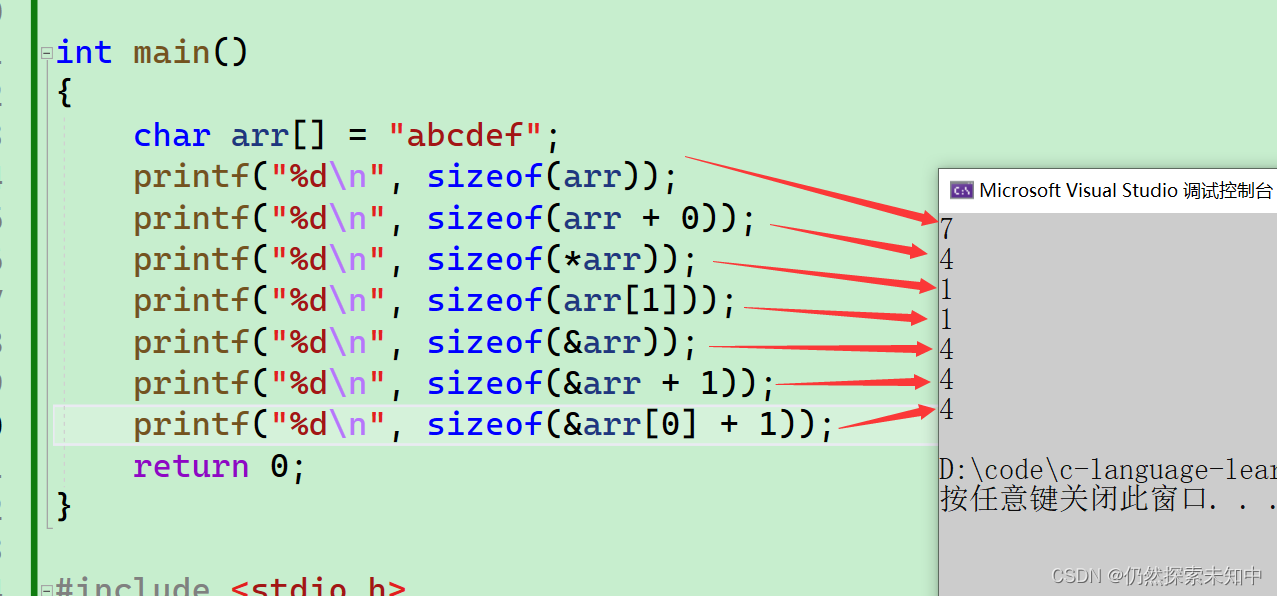
- 我们再把sizeof换成strlen~~
char arr[] = "abcdef"; printf("%d\n", strlen(arr)); printf("%d\n", strlen(arr+0)); printf("%d\n", strlen(*arr)); printf("%d\n", strlen(arr[1])); printf("%d\n", strlen(&arr)); printf("%d\n", strlen(&arr+1)); printf("%d\n", strlen(&arr[0]+1));
- arr是首元素的地址,计算的是strlen遇到\0之前元素的个数,结果是
6
printf("%d\n", strlen(arr));
- arr+1 也是首元素的地址,结果就是
6
printf("%d\n", strlen(arr+0));
- 这里结果是
报错,会非法访问
printf("%d\n", strlen(*arr));
- 这里也会形成
非法访问~~
printf("%d\n", strlen(arr[1]));
- &arr是数组的地址,但是这个地址也是指向数组的起始位置的,strlen就从起始位置开始向后找\0,结果是
6
printf("%d\n", strlen(&arr));
- &arr+1是跳过整个数组后的地址,从这里开始向后找\0,就是
随机值
printf("%d\n", strlen(&arr+1));
- arr[0] + 1 是第二个元素的地址,长度是
5
printf("%d\n", strlen(&arr[0]+1));
- 我们来看一下结果~~

- 我们这里指针变量
p存放的是这个字符串a的地址
char *p = "abcdef"; printf("%d\n", sizeof(p)); printf("%d\n", sizeof(p+1)); printf("%d\n", sizeof(*p)); printf("%d\n", sizeof(p[0])); printf("%d\n", sizeof(&p)); printf("%d\n", sizeof(&p+1)); printf("%d\n", sizeof(&p[0]+1));
- p是一个指针变量,大小是
4/8个字节
printf("%d\n", sizeof(p));
- p+1是‘b’的地址,是地址就是
4/8个字节
printf("%d\n", sizeof(p+1));
*p是首字符,大小是1字节
printf("%d\n", sizeof(*p));
- p[0] === *(p+0),其实就是字符串中的首字符,大小是1字节
printf("%d\n", sizeof(p[0]));
- &p是p的地址,也是地址,地址大小就是4/8个字节
printf("%d\n", sizeof(&p));
- &p + 1也是地址,&p1+1是跳过p变量后的地址
printf("%d\n", sizeof(&p+1));
- 4/8 – &p[0] + 1是b的地址
printf("%d\n", sizeof(&p[0]+1));
32位下

64位下

char *p = "abcdef"; printf("%d\n", strlen(p)); printf("%d\n", strlen(p+1)); printf("%d\n", strlen(*p)); printf("%d\n", strlen(p[0])); printf("%d\n", strlen(&p)); printf("%d\n", strlen(&p+1)); printf("%d\n", strlen(&p[0]+1));
- p指向这个字符串的首元素地址,字符串中有\0,从a的地址开始向后访问,结果就是
6
printf("%d\n", strlen(p));
- p的类型是
char*,+1跳过的就是一个char类型的数据,所以就来到了字符'b'的地址处,向后找\0的话就最后的结果即为 5
printf("%d\n", strlen(p+1));
*p取到的就是字符'a',strlen就会把字符a的ascll码值当地址传过去了,会产生非法访问,结果是err
printf("%d\n", strlen(*p));
- 这个和上一个一样,也是会产生非法访问,就相当于
*p == *(p+0) == p[0]
printf("%d\n", strlen(p[0]));
- 这个结果就是随机值,&p是p的地址,类型是
char*从p所占空间的起始位置开始查找的,它不知道什么时候会遇到\0,所以就会是随机值
printf("%d\n", strlen(&p));
- 这个代码在&取地址后它的类型就变成了
char**,+1会跳过一个char*类型的数据,它指向了字符串末尾的这个位置,从这里向后去进行找\0,也是不知道什么时候会遇到,所以最后的结果还是随机值
printf("%d\n", strlen(&p+1));
- 这里和第二个很相似,&和[]就相当于抵消了,+1就指向了
'b',结果也就是5
printf("%d\n", strlen(&p[0]+1));

最后我们再来看二维数组,也是比较难的一部分
二维数组
int a[3][4] = {0}; printf("%d\n",sizeof(a)); printf("%d\n",sizeof(a[0][0])); printf("%d\n",sizeof(a[0])); printf("%d\n",sizeof(a[0]+1)); printf("%d\n",sizeof(*(a[0]+1))); printf("%d\n",sizeof(a+1)); printf("%d\n",sizeof(*(a+1))); printf("%d\n",sizeof(&a[0]+1)); printf("%d\n",sizeof(*(&a[0]+1))); printf("%d\n",sizeof(*a)); printf("%d\n",sizeof(a[3]));
- sizeof(数组名),计算的就是整个数组的大小,这是一个二维数组,数组是三行四列的,总共十二个元素,每个元素的类型是int,为4个字节,那么总的大小就是
48
printf("%d\n", sizeof(a));
- a[0][0]代表的是数组第一行第一列的元素,所以每个元素都是
4个字节
printf("%d\n", sizeof(a[0][0]));
a[0]为第一行的数组名,而且它是单独放在sizeof()内部的,计算的是第一行这一整行的大小,里面有4个元素,每个元素都是4个字节,那么结果即为16
printf("%d\n", sizeof(a[0]));
- a[0]是第一行这个数组的数组名,但是数组名并非单独放在sizeof内部,所以数组名表示数组首元素的地址,也就是a[0][0]的地址,a[0]+1是第一行第二个元素
a[0][1]的地址,地址的大小是4/8个字节
printf("%d\n", sizeof(a[0] + 1));
a[0] + 1是第一行第二个元素a[0][1]的地址,*(a[0] + 1)就是第一行第二个元素,大小是4个字节
printf("%d\n", sizeof(*(a[0] + 1)));
a没有单独放在sizeof内部,没有&,数组名a就是数组首元素的地址,也就是第一行的地址,a+1,就是第二行的地址,也就是等价于a -- int(*)[4]---->a+1 -- int(*)[4]
printf("%d\n", sizeof(a + 1));
- 下面这个也就是对这一行解引用,那么也就得到了第二行这一整行,此时计算是这一整行的大小,结果为
16
printf("%d\n", sizeof(*(a + 1)));
- 这个和上一个一样,只是换了一种写法,等价于
*(a + 1),计算的是第二行的元素大小,结果是16
printf("%d\n", sizeof(a[1]));
- a[0]为第一行的数组名,对它进行取地址就取到了这一整行的地址,它的类型也为一个数组指针int (*)[4],那
+1的话也会跳过整个数组,此时也就来到了第二行,那么取到的便是第二行的地址,地址的大小即为4/8个字节
printf("%d\n", sizeof(&a[0] + 1));
- 这里和上面那个相似,第二行解引用,算的是第二行元素的大小,结果是
16
printf("%d\n", sizeof(*(&a[0] + 1)));
- 数组名a就是数组首元素的地址,也就是第一行的地址,
*a就是一行的 等价于*(a+0) == a[0]
printf("%d\n", sizeof(*a));
- 这个二维数组不是只有三行吗,第三行的数组名为a[2],那a[3]不是越界了吗?
- 要知道,对于任何一个表达式来说具有2个属性,一个是【值属性】,一个是【类型属性】
- 例如3 + 5 = 8,它的值属性就是数字8,类型属性即为int但对于【sizeof()】来说,它在计算的时候只需要知道【类型属性】就可以了,类似我们之前写过的sizeof(int)、sizeof(char)等等,对这些内置类型就可以计算出它的大小,并没有去实际地创造出空间
- 那么对于下面这个a[3]来说,虽然看上去存在越界,但是sizeof()并不关心你有没有越界,而是知道你的类型即可,那么a[3]便是二维数组的第四行,虽然没有第四行,但是类型是确定的,那么大小就是确定的,计算sizeof(数组名)计算的是整个数组的大小,结果便是16
printf("%d\n", sizeof(a[3]));
- 我们来看一下运行结果~~

