openGauss向量化执行引擎的Merge Join
1 什么是semi join
Semi join语义:对于外表一行值,只要内表有一行与之相等,即满足join条件,就输出外表值。这里需要注意,仅输出外表值,而不和对应内表值合并输出。
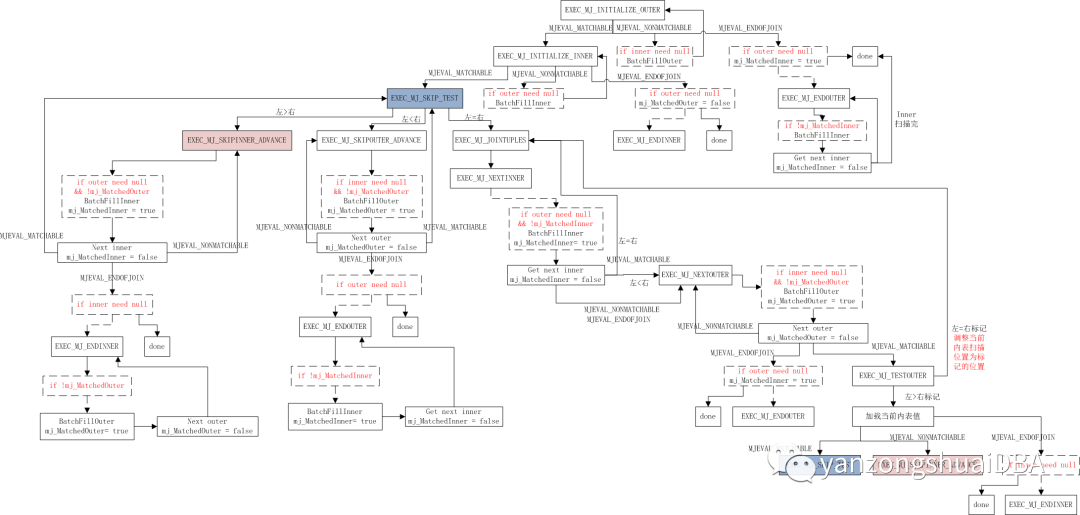
2 openGauss VecMergeJoin状态机
VecMergeJoin状态机如下图所示:
下面我们以一个例子为例,解释各个join的执行情况。
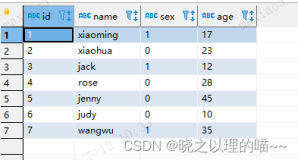
表t30和t31的结构及数据如下:
postgres=# select * from t30 id1 | id2 ----|---- 1 | 1 2 | 3 2 | 3 (3 rows) postgres=# select * from t31 id1 | id2 ----|---- 1 | 1 5 | 5 2 | 3 (3 rows)
t30作为外表,t31作为内表,join条件为t30.id1=t31.id1。
3 semi join
SEMI JOIN的状态转换和INNER JOIN相同,参考上篇:
这里不再赘述。不同之处在于JOIN结果Produce的过程。即ProduceResultBatchT函数完成的功能,这里针对ProduceResultBatchT函数说明semi join最后的处理过程。
在执行ProduceResultBatchT函数前,m_pInnerMatch和m_pOuterMatch的值分别为:
m_pInnerMatch m_pOuterMatch 1 1 2 2 2 2
需要对上面的值进行处理:
1)更新m_pInnerMatch和m_pOuterMatch每列的行值为m_pInnerMatch的m_rows。因为对于NULL,他没有更新对应列行数
2)pSelection[]数组都置为true,表示:上面两个batch选取哪行,哪行就为true。这里先置为true,方便下面计算
3)针对每一行,都需要判断当前一行和下一行匹配的值是否在同一个位置,也就是源batch的第几行。如果在同一个位置,就表示后面的一个需要取消,即置为false。
4)假设一个batch仅能容纳2行,下图的例子,红线上面:外表的4和内表2个4匹配,需要join,此时第2个匹配的根据SEMI JOIN语义需要去掉,即将对应的pSelect[]数组值置为false。

5)红线上面的输出后,需要循环再次进入ExecVecMergeJoinT函数接着EXEC_MJ_NEXTINNER状态进行处理。此时已经跨了batch,则需要另外一个条件来判断是否重复。
4)和5)的条件为:

第一个if针对跨batch的,第二个for循环的条件针对同一个batch的。这里详细解释下第一个条件:
当跨batch时输出时,m_prevOuterOffset为外表当前扫描位置。再次循环进来比较时外表值是clause->ldatum,他的位置仍然保持是m_prevOuterOffset的位置,所以此时使用第一个条件即可更新pSelect[]数组。
那么为什么同样使用第2个条件呢?因为如上图例子,第二次进来后处理第一个值是需要和上一个batch的最后一个记录比较,而不是本次的下一个比较(当然本次也没有下一个值)。
以上即使SEMI JOIN向量化机制。比较晦涩,希望能够给大家抛砖引玉,带来方便。