在阅读本文之前,强烈建议先阅读《PolarDB-X源码解读系列:SQL的一生》,能够了解一条SQL的执行流程,也能知道polardbx-sql(CN)的各个组件,然后再阅读本文,了解Insert的具体实现过程,加深各个组件的理解。Insert类的SQL语句的流程可初略分为:解析、校验、优化器、执行器、物理执行(polardbx-engine执行)。本文将以一条简单的Insert语句通过调试的方式进行解读。建表语句:
#一个简单的PolarDB-X中的分库分表sbtest CREATE TABLE `sbtest` ( `id` int(11) NOT NULL AUTO_INCREMENT, `k` int(11) NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`) )dbpartition by hash(`id`) tbpartition by hash(`id`) tbpartitions 2; #调试语句 insert into sbtest(id) values(100);
一、解析
连接上PolarDB-X后,执行一条Insert语句insert into sbtest(id) values(100);PolarDB-X接收到该字符串语句后,开始执行该SQL,可见TConnection#executeSQL:

准备执行该SQL语句,ExecutionContext会保留该Sql执行的参数、配置、等上下文信息,该变量会一直陪伴该Sql经过解析、校验、优化器、执行器,直到下发给polardbx-engine(DN)。PolarDB-X执行该SQL时,需要先获取执行计划,可见代码TConnection#executeQuery:
ExecutionPlan plan=Planner.getInstance().plan(sql, executionContext);
为了避免执行同一条SQL每次都要解析、校验、优化器等操作,PolarDB-X内置了PlanCache,会在PlanCache中获取该SQL的执行计划,当然,并不是根据纯字符串SQL来进行缓存,而是生成SqlParameterized,如下图所示(Planner#plan),真正缓存的是sql模板,该类中的sql变量:INSERT INTO sbtest(id)\nVALUES (?),可适用于类似的语句,?代表可填入的值,不同的值都是同一类SQL语句。

如果PlanCache找不到的话,需要生成新的执行计划,具体代码见PlanCache#getFromCache:
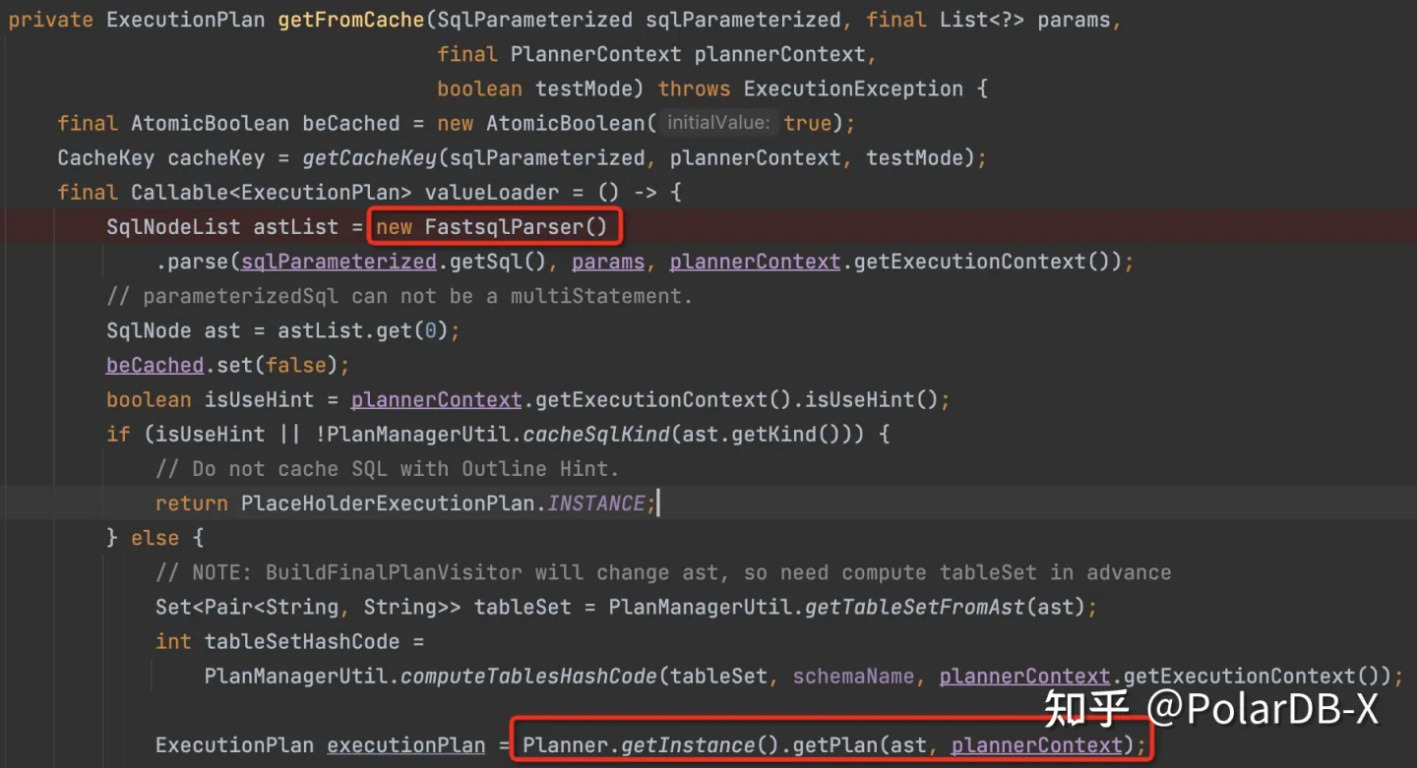
先将字符串通过FastsqlParser解析成抽象语法树,检查有没有语法错误等,生成SqlNode,本条SQL是Insert语句,解析成SqlInsert类,然后继续根据抽象语法树获取执行计划,具体SqlInsert内容为:

简单解释几个变量:
keywords:关键字,例如:Insert Ignore语句会加Ignore关键字,代表该语句特征。
source:数据来源,插入数据的来源,这里是values,如果是 Insert ... Select语句,则是select语句。
updateList:修改信息,例如:Insert ... ON DUPLICATE KEY 语句会把修改信息保存在该变量。
至此,完成了字符串SQL语句到SqlNode的转变,即完成了解析部分。
二、校验
校验过程即检查SqlNode的语义是否正确,例如表是否存在、列是否存在、类型是否正确等等,具体入口在Planner#getPlan函数中:
SqlNode validatedNode = converter.validate(ast);
便是验证该SQL的有效性,PolarDB-X沿用了Apache Calcite框架,validate的实现也是类似的大框架,包含Scope和Namespace两个概念,在此基础上进行验证,SqlInsert类型的验证入口在SqlValidatorImpl#validateInsert(SqlInsert insert)中:
... final SqlValidatorNamespace targetNamespace = getNamespace(insert); validateNamespace(targetNamespace, unknownType); ... final SqlNode source = insert.getSource(); if (source instanceof SqlSelect) { final SqlSelect sqlSelect = (SqlSelect) source; validateSelect(sqlSelect, targetRowType); } else { final SqlValidatorScope scope = scopes.get(source); validateQuery(source, scope, targetRowType); } ...
大体流程检查两个部分:首先,检查insert into sbtest语句是否正确;然后检查SqlInsert.source部分是否有效。本条SQL是Values,所以检查Values是否有效,如果是Insert...Select语句,source是SqlSelect,需要检查Select语句是否有效。没有报错,则说明SQL语句语义没有错误,校验通过,可以发现还是SqlInsert:

三、优化器
在经过优化器之前,还需要将SqlNode(SqlInsert)转成RelNode,大体含义就是将sql语法树转成关系表达式,入口在Planner#getPlan:
RelNode relNode = converter.toRel(validatedNode, plannerContext);
具体转换过程在SqlConverter#toRel:
... final SqlToRelConverter sqlToRelConverter = new TddlSqlToRelConverter(...); RelRoot root = sqlToRelConverter.convertQuery(validatedNode, false, true); ...
TddlSqlToRelConverter类是PolarDB-X的转换器,继承Calcite的SqlToRelConverter类,转换SqlInsert的执行过程在TddlSqlToRelConverter#convertInsert(SqlInsert call):
RelNode relNode = super.convertInsert(call); if (relNode instanceof TableModify) { ... }
可以发现,会调用SqlToRelConverter#convertInsert,在该方法中,会将SqlInsert转成LogicalTableModify,该类的内容如下:

可以注意到几个变量:operation:操作类型;input:输入来源,本条sql是values; PolarDB-X内部还有新的自己的RelNode,所以还会把RelNode再转成自己定义的RelNode,入口在Planner#getPlan:
ToDrdsRelVisitor toDrdsRelVisitor = new ToDrdsRelVisitor(validatedNode, plannerContext); RelNode drdsRelNode = relNode.accept(toDrdsRelVisitor);
转换过程在ToDrdsRelVisitor#visit(RelNode other):
if ((other instanceof LogicalTableModify)) { ... if (operation == TableModify.Operation.INSERT || ...) { LogicalInsert logicalInsert = new LogicalInsert(modify); ... } }
Insert类型会转成LogicalInsert,就是PolarDB-X内部的RelNode,执行也是基于该类,LogicalInsert的内容如下(还有部分变量不在截图中):

大多数变量和LogicalTableModify一样,新增了像PolarDB-X特有的gsi相关变量等等。然后便是经过优化器阶段,优化器执行过程代码在Planner#sqlRewriteAndPlanEnumerate:
private RelNode sqlRewriteAndPlanEnumerate(RelNode input, PlannerContext plannerContext) { CalcitePlanOptimizerTrace.getOptimizerTracer().get().addSnapshot("Start", input, plannerContext); //RBO优化 RelNode logicalOutput = optimizeBySqlWriter(input, plannerContext); CalcitePlanOptimizerTrace.getOptimizerTracer().get() .addSnapshot("PlanEnumerate", logicalOutput, plannerContext); //CBO优化 RelNode bestPlan = optimizeByPlanEnumerator(logicalOutput, plannerContext); // finally we should clear the planner to release memory bestPlan.getCluster().getPlanner().clear(); bestPlan.getCluster().invalidateMetadataQuery(); return bestPlan; }
Insert的优化器主要在RBO过程,定义了一些规则,CBO规则对Insert几乎没有改变。可以重点关注RBO的OptimizeLogicalInsertRule规则,会根据GMS(PolarDB-X的元数据管理)的信息来判断该SQL的执行计划,可能会将LogicalInsert转变成其它的RelNode去执行,方便区分不同的SQL执行方式,首先会确定该SQL的执行策略,主要分为三种:
public enum ExecutionStrategy { /** * Foreach row, exists only one target partition. * Pushdown origin statement, with function call not pushable (like sequence call) replaced by RexCallParam. * Typical for single table and partitioned table without gsi. */ PUSHDOWN, /** * Foreach row, might exists more than one target partition. * Pushdown origin statement, with nondeterministic function call replaced by RexCallParam. * Typical for broadcast table. */ DETERMINISTIC_PUSHDOWN, /** * Foreach row, might exists more than one target partition, and data in different target partitions might be different. * Select then execute, with all function call replaced by RexCallParam. * Typical for table with gsi or table are doing scale out. */ LOGICAL; };
由于本条SQL较为简单,策略是PUSHDOWN,处理过程也比较简单,然后生成InsertWriter,该类负责生成下发到DN的SQL语句,保存在LogicalInsert中,OptimizeLogicalInsertRule处理规则较为细节,感兴趣的可以自行查看onMatch方法。经过优化器后,还是LogicalInsert类的RelNode,至此,意味着优化器执行完毕。最终会生成执行计划,在PlanCache#getFromCache,见下图(图中非全部变量):

ExecutionPlan.plan就是执行计划,可以发现是LogicalInsert,对于简单的Insert,PolarDB-X还会改写执行计划,代码在PlanCache#getFromCache:
BuildFinalPlanVisitor visitor = new BuildFinalPlanVisitor(executionPlan.getAst(), plannerContext); executionPlan = executionPlan.copy(executionPlan.getPlan().accept(visitor)); insert into sbtest(id) values(100);
语句执行BuildFinalPlanVisitor#buildNewPlanForInsert(LogicalInsert logicalInsert,ExecutionContext ec),因为该Insert语句比较简单,只有一个values,包含拆分键和auto_increment列,只需要根据拆分键就能确定下发到DN的哪一个分片,在CN端无需更多操作,所以会简化执行计划,在BuildFinalPlanVisitor#buildSingleTableInsert转成SingleTableOperation,并保存了分库分表规则,最终的执行计划如下:
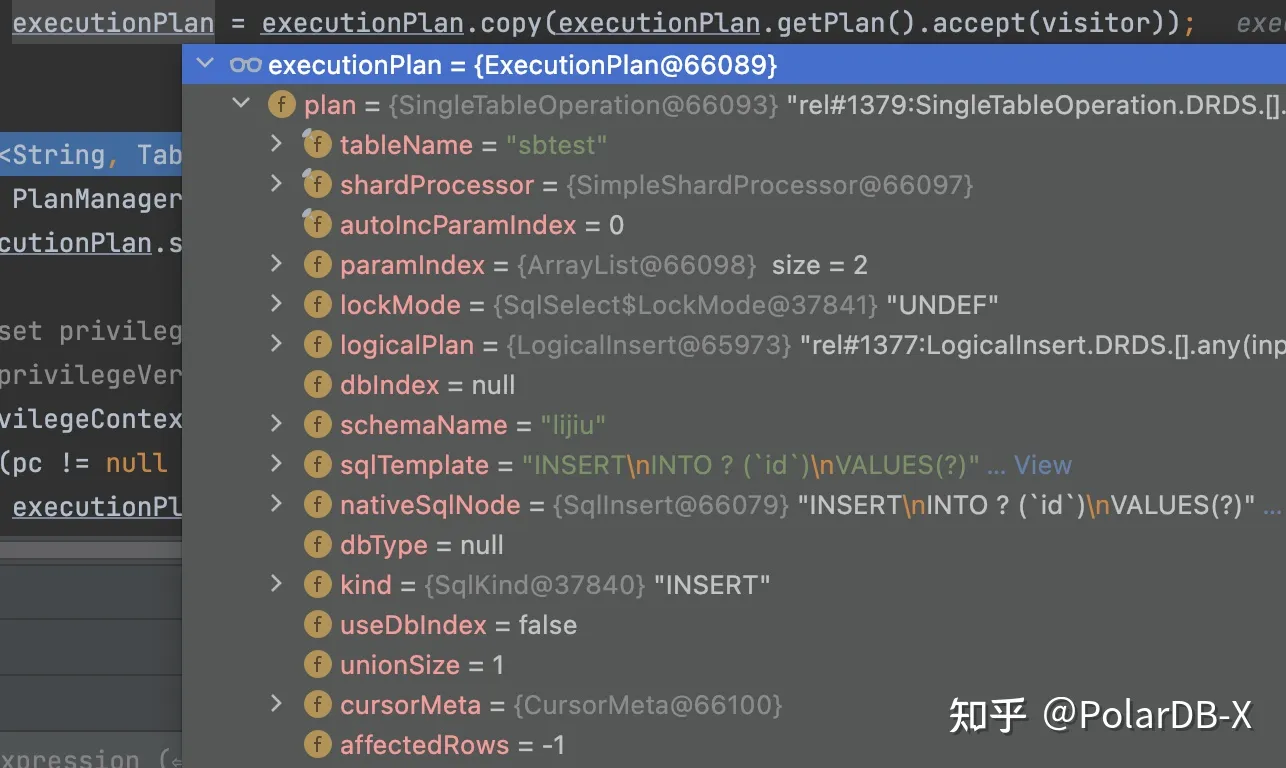
执行计划变成SingleTableOperation,至此,执行计划生成完毕。
四、执行器
SQL语句生成执行计划后,将由执行器进行执行,执行入口在TConnection#executeQuery:
ResultCursor resultCursor=executor.execute(plan,executionContext);
然后会由ExecutorHelper#execute方法执行ExecutionPlan.plan,也就是前面的SingleTableOperation,执行策略有CURSOR、TP_LOCAL、AP_LOCAL、MPP,Insert类型基本都是走CURSOR,接着根据执行计划拿对应的Handler进行处理,具体可查看CommandHandlerFactoryMyImp类,例如:SingleTableOperation是MySingleTableModifyHandler,LogicalInsert是LogicalInsertHandler。会在对应的Handler里面进行执行,一般会返回一个Cursor,Cursor里面会调用真正的执行过程,调用Cursor.next便会获取结果,Insert语句的结果是affect Rows,本条SQL会创建一个MyPhyTableModifyCursor,入口在MySingleTableModifyHandler#handleInner:
... MyPhyTableModifyCursor modifyCursor = (MyPhyTableModifyCursor) repo.getCursorFactory().repoCursor(executionContext, logicalPlan); ... affectRows = modifyCursor.batchUpdate(); ...
根据ExecutionContext和SingleTableOperation创建一个MyPhyTableModifyCursor,然后直接执行:
public int[] batchUpdate() { try { return handler.executeUpdate(this.plan); } catch (SQLException e) { throw GeneralUtil.nestedException(e); } }
这里的this.plan就是SingleTableOperation,handler是PolarDB-X的CN与DN间交互的MyJdbcHandler,可以认为是执行物理计划的handler,会根据plan生成真正的物理SQL,下发到DN执行。由于这条SQL较为简单,CN不需要过多处理,再举一例Insert语句:insert into sbtest(k) values(101),(102);经过优化器后,该语句的执行计划是LogicalInsert,如下图:

可以发现sqlTemplate为INSERT\nINTO ? (id,k)\nVALUES(?,?),表名可能要换成物理表名,同时增加了一列id,因为该列是auto_increment,会有一个全局的sequence表来记录该列的值,才能保证全局唯一,插入的values的参数保留在ExecutionContext的params中,如下图:

id列的值会在真正生成物理执行计划的时候才会去获取,LogicalInsert计划适用LogicalInsertHandler来执行,执行过程:
public Cursor handle(RelNode logicalPlan, ExecutionContext executionContext){ ... LogicalInsert logicalInsert = (LogicalInsert) logicalPlan; ... if (!logicalInsert.isSourceSelect()) { affectRows = doExecute(logicalInsert, executionContext, handlerParams); } else { affectRows = selectForInsert(logicalInsert, executionContext, handlerParams); } ... }
会根据来源是否是Select语句选择不同的执行方式,具体执行过程在LogicalInsertHandler#executeInsert,如下:
... //生成主表的物理执行计划 final InsertWriter primaryWriter = logicalInsert.getPrimaryInsertWriter(); List<RelNode> inputs = primaryWriter.getInput(executionContext); ... //如果有GSI,生成GSI表的物理执行计划 final List<InsertWriter> gsiWriters = logicalInsert.getGsiInsertWriters(); gsiWriters.stream().map(gsiWriter -> gsiWriter.getInput(executionContext))...; ... //执行所有物理执行计划 final int totalAffectRows = executePhysicalPlan(allPhyPlan, executionContext, schemaName, isBroadcast); ...
主表生成物理执行计划过程中,会先获取id的值,由于id也是拆分键,所以两个values会根据拆分键定位到不同的物理分库分表上,会生成有两个物理执行计划,如下:


其中dbIndex是物理库名,tableNames是物理表名,param保存了这条slqTemplate的参数值,填充上就是完整的SQL,然后执行所有物理执行计划,就完成了该SQL的执行。
五、物理执行
PolarDB-X中CN与DN的交互都在MyJdbcHandler中,以SingleTableOperation为例,看看具体交互过程:
public int[] executeUpdate(BaseQueryOperation phyTableModify) throws SQLException { ... //获取物理执行计划的库名和参数 Pair<String, Map<Integer, ParameterContext>> dbIndexAndParam = phyTableModify.getDbIndexAndParam(executionContext.getParams() == null ? null : executionContext.getParams() .getCurrentParameter(), executionContext); ... //根据库名获取连接 connection = getPhyConnection(transaction, rw, groupName); ... //根据参数组成字符串SQL String sql = buildSql(sqlAndParam.sql, executionContext); ... //根据连接创建prepareStatement ps = prepareStatement(sql, connection, executionContext, isInsert, false); ... //设置参数 ParameterMethod.setParameters(ps, sqlAndParam.param); ... //执行 affectRow = ((PreparedStatement) ps).executeUpdate(); ... }
将物理执行计划发送到DN执行,执行完成后,根据affectRow返回到执行器,最终会把结果返回给用户,至此,一条完整SQL就执行完成。
六、小结
本文通过调试简单的Insert语句,介绍了PolarDB-X在解析、校验、优化器、执行器对Insert语句的处理,当然,Insert语句也有很多特殊的用法,本文并没有一一概述,感兴趣的同学可以在相应代码处进行查看。



