本篇将对Binlog的产生,以及如何通过系统处理并最终生成Global Binlog的过程进行分析。
一、概述
Global Binlog的一生是指从原始Binlog产生,到最终Global Binlog生成期间产生的故事,本文会详细介绍Binlog拉取,数据整形合并,以及最终生成Global Binlog期间经过的关键流程。Global Binlog涉及到Task和Dumper组件,分别针对Binlog整形合并以及落盘过程,下面会介绍这两个组件对binlog处理的相关代码。

二、Task组件
当用户向PolarDB-X写入数据时,最终数据会落盘到底层DN上,DN会产生原始binlog,task组件会拉取到原始binlog,整形合并成Global Binlog后,发送给下游Dumper组件,下面我们通过查看Task的核心代码来了解一下整个原始Binlog的处理流程。

我们可以以代码com.aliyun.polardbx.binlog.canal.core.BinlogEventProcessor(github地址:https://github.com/polardb/polardbx-cdc)为入口来查看整个binlog的关键入口class,查看binlog是如何拉取并投递到下游handler中。

在handler中,会通过一些列的filter,对binlog进行处理。在com.aliyun.polardbx.binlog.canal.core.handle.DefaultBinlogEventHandle代码中,我们可以看到如下逻辑

通过head对象的doNext方法,逐级遍历所有filter,最终对binlog event进行过滤和格式化处理,并输出逻辑event到下游。head对象为filter链表,初始化逻辑见下面代码。
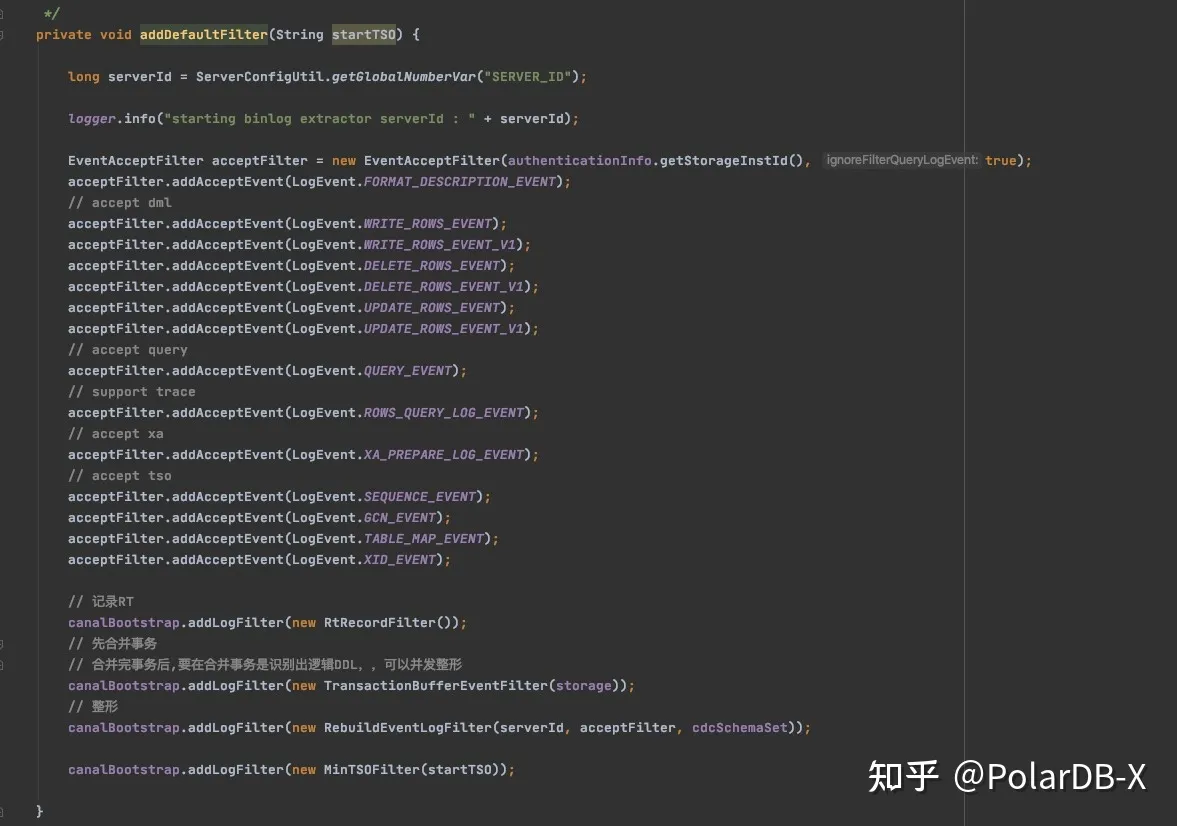
Extractor中的filter chain如图:

在BinlogExtractor初始化时,会将一些列Filter加入到列表中,binlog event会按顺序逐个经过这些filter。
com.aliyun.polardbx.binlog.extractor.filter.RtRecordFilter:会记录当前event下游逻辑处理的rt。
com.aliyun.polardbx.binlog.extractor.filter.TransactionBufferEventFilter:处理事务相关event,并标记出tso事件。

当收到commit event时,会尝试执行tryDoNext。
 、、
、、
事务的推送算法可以在
com.aliyun.polardbx.binlog.extractor.filter.TransactionStorage类中查看。com.aliyun.polardbx.binlog.extractor.filter.RebuildEventLogFilter负责binlog event过滤和整形流程,具体逻辑可以查看handle方法。整形的关键代码可以查看reformat方法。

Global binlog中,我们只关心QueryEvent、RowEvent(Insert/Update/Delete)和TableMapEvent,所以这里我们只处理了这些event的数据。
com.aliyun.polardbx.binlog.extractor.filter.MinTSOFilter会对事务进行初步过滤。数据最终会通过
com.aliyun.polardbx.binlog.extractor.DefaultOutputMergeSourceHandler推送给下游事务合并代码com.aliyun.polardbx.binlog.merge.MergeSource中,sourceId唯一标记了当前数据流id,queue保存事务索引txnKey。

com.aliyun.polardbx.binlog.merge.LogEventMerger中,会将所有DN对应的MergeSource的queue遍历提取出来。

com.aliyun.polardbx.binlog.merge.MergeController会保存对应的sourceId和数据,确保每个sourceId只会收到一条数据,下游在拉取数据时,会将保存在优先队列的数据pop出来,push到com.aliyun.polardbx.binlog.collect.LogEventCollector中,最终通过ringBuffer提供给com.aliyun.polardbx.binlog.transmit.LogEventTransmitter来投递给下游Dumper组件。
三、Dumper组件
当Global Binlog系统启动时,优先启动Task组件,监听端口。Dumper组件会尝试连接Task。Dumper组件收到Task推送的Global Binlog后,会对binlog进行最后的细节处理,并且把处理好的结果写入磁盘。下面我们从Dumper组件消费Task推送数据的入口来分析,整个binlog处理核心流程。在com.aliyun.polardbx.binlog.dumper.dump.logfile.LogFileGenerator类的start方法中,该方法会启动grpc连接Task端口。

代码里实现了com.aliyun.polardbx.binlog.rpc.TxnMessageReceiver接口,该接口会消费上游推送过来的所有数据,并在consume方法中,处理相关Global Binlog position等相关信息,并最终通过com.aliyun.polardbx.binlog.dumper.dump.logfile.BinlogFile写入到磁盘中。
private void consume(TxnMessage message, MessageType processType) throws IOException, InterruptedException { ... switch (processType) { case BEGIN: ... break; case DATA: ... break; case END: ... break; case TAG: currentToken = message.getTxnTag().getTxnMergedToken(); if (currentToken.getType() == TxnType.META_DDL) { ... } else if (currentToken.getType() == TxnType.META_DDL_PRIVATE) { ... } else if (currentToken.getType() == TxnType.META_SCALE) { ... } else if (currentToken.getType() == TxnType.META_HEARTBEAT) { ... } else if (currentToken.getType() == TxnType.META_CONFIG_ENV_CHANGE) { ... } break; default: throw new PolardbxException("invalid message type for logfile generator: " + processType); } }
在consome方法中会逐个处理事务和数据相关的事件,如果事件打标了系统之间交互的tag,会针对相应的tag做一定的逻辑处理。
四、小结
本文对binlog的拉取、整形处理和最终落盘涉及到的关键流程进行了简单梳理,Global binlog的一生是从原始物理binlog到逻辑binlog的转变,代码中的原理可以参考全局Binlog解读之理论篇(https://zhuanlan.zhihu.com/p/462995079)。


![[版本更新] PolarDB-X V2.4 列存引擎开源正式发布](https://ucc.alicdn.com/pic/developer-ecology/nmwxanvmfezte_85c4d30b1404479b982cc86614e8edfb.png?x-oss-process=image/resize,h_160,m_lfit)