一、概述
本文将主要解读PolarDB-X中事务部分的相关代码,着重解读事务的一生在计算节点(CN)中的关键代码:从开始、执行、到最后提交这一整个生命周期。
在阅读本文前,强烈推荐先阅读与PolarDB-X事务系统相关的文章:
PolarDB-X 强一致分布式事务原理。
PolarDB-X 分布式事务的实现(一)
PolarDB-X 分布式事务的实现(二)InnoDB CTS 扩展
PolarDB-X 分布式事务的实现(四):跨地域事务 *
无处不在的 MySQL XA 事务
PolarDB-X SQL 的一生
二、事务与连接
在PolarDB-X的CN层,与事务关系密切的是连接。这是因为数据节点(DN)也具备单个DN内的事务能力,CN则通过与DN的连接来管理DN上的事务,从而实现强一致的分布式事务能力。其中涉及到的连接大致如下图所示:
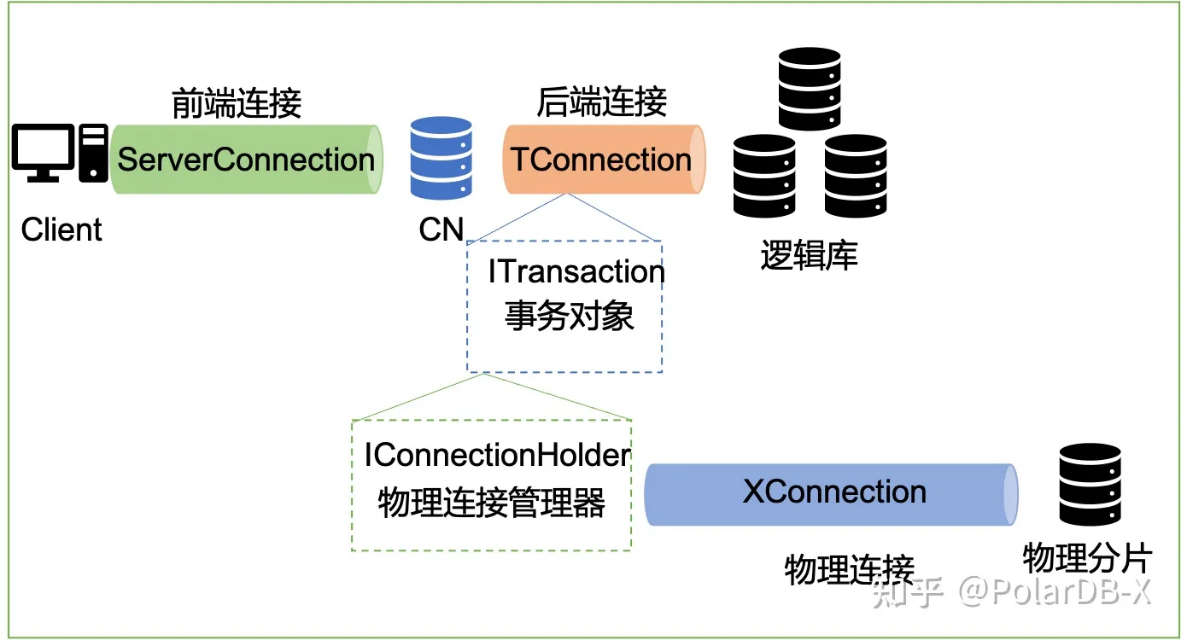
事务与连接
先简单说一下这里面涉及的一些连接。ServerConnection类似于前端连接,大部分的SQL语句执行的入口都是ServerConnection#innerExecute。TConnection中的executeSQL方法负责SQL语句的真正执行,也负责创建新的事务对象。TConnection会一直引用着这个事务对象,直到事务提交或回滚。事务对象里有一个TransactionConnectionHolder,负责管理该事务用到的所有物理连接(CN连接DN的私有协议连接)。值得一提的是,ExecutionContext作为一条逻辑SQL执行的上下文,也会引用这个事务对象。这样,后续执行器需要使用物理连接与DN通信时,就可以通过ExecutionContext拿到事务对象,再通过事务对象的TransactionConnectionHolder拿到合适的物理连接。
以上的各种连接,都会在下文继续讨论。
三、两个例子
接下来,我们以两个简单的例子,来说明事务的一生在CN的代码中是如何体现的。
测试用表:
CREATE TABLE `tb1` ( `id` int PRIMARY KEY, `a` int ) DBPARTITION BY HASH(`id`)
先在里面插入几条数据:
INSERT INTO tb1 VALUES (0, 0), (1, 1), (2, 2), (3, 3);
测试使用的两个例子:
-- Transaction 1: BEGIN; SELECT * FROM tb1 WHERE id = 0; UPDATE tb1 SET a = 100 WHERE id = 1; COMMIT; -- Transaction 2: BEGIN; SELECT * FROM tb1 WHERE id = 0; UPDATE tb1 SET a = 101 WHERE id = 1; UPDATE tb1 SET a = 101 WHERE id = 0; COMMIT;
注意到事务2只比事务1多修改了id=0的数据。测试表是按id拆分的,因此id=0和id=1的记录会落在不同的物理分片上(假设分别为分片0和分片1)。事务1读了分片0,写了分片1,然后提交了事务,这将会触发我们对单分片写的“一阶段提交优化”。事务2读了分片0,随后写了分片1和分片0,然后提交了事务,这将会进行完整的分布式事务提交流程。这两个事务还会触发“只读连接优化”,即只有在第一次写的时候才真正开启分布式事务。
在接下来的讨论中,我们默认使用TSO事务策略和RR的隔离级别。
四、事务1的一生
1.BEGIN
与MySQL类似,要开启一个事务,一般有两种方式。
第一种方式是显式地执行BEGIN或START TRANSACTION [transaction_characteristic],执行这两种语句,会调用ServerConnection中的begin(boolean, IsolationLevel)方法。
第二种方式是执行SET autocommit=0,当前session会隐式开启事务,这种方式会调用ServerConnection中的setAutocommit(boolean, boolean)方法。
两种方式都会调用TConnection的setAutoCommit方法。这些方法都只是简单地记录了一些变量(比如transaction_characteristic中设定的事务相关变量),同时标记这个连接开启了事务。此时,事务对象也还没创建出来,也没有与后端连接进行任何交互。
2.读分片0
在开启事务后,执行SELECT * FROM tb1 WHERE id = 0时,才会真正创建事务对象。根据事务与连接中的讨论,在TConnection中这条逻辑SQL的执行入口为executeSQL,里面会真正创建事务对象,主要执行逻辑为(代码出自PolarDB-X 5.4.13 release版本,为了方便说明,有删减及改动,下同):
// TConnection#executeSQL(ByteString, Parameters, TStatement, ExecutionContext) public ResultSet executeSQL(ByteString sql, Parameters params, TStatement stmt, ExecutionContext executionContext) throws SQLException { if (this.trx == null || this.trx.isClosed()) { // 开启事务后,直到执行第一条语句,才会创建事务对象。 beginTransaction(); } // 让 executionContext 引用 trx 对象,方便后续执行器通过 trx 对象拿物理连接。 executionContext.setTransaction(this.trx); resultCursor = executeQuery(sql, executionContext, trxPolicyModified); } // TConnection#beginTransaction(boolean) private void beginTransaction(boolean autoCommit) { // 根据一些默认的或用户设定的事务变量,选择合适的事务策略,比如 TSO/XA 等。 trxPolicy = loadTrxPolicy(executionContext); TransactionClass trxConfig = trxPolicy.getTransactionType(autoCommit, readOnly); // 根据事务策略,创建出对应的事务对象。 this.trx = transactionManager.createTransaction(trxConfig, executionContext); } 在我们的例子中,如果在上述代码打个断点,可以看到创建出来的是TsoTransaction,其中一些值得关注的变量为: trx = {TsoTransaction} // 此时还没有获取任何时间戳。 snapshotTimestamp = -1 commitTimestamp = -1 // 事务写的第一个物理分片(下称主分片),事务日志将会写在这个分片上。 primaryGroup = null // 该事务是否跨分片,如果是单分片事务,会优化为一阶段提交。 isCrossGroup = false // 事务日志管理器,负责写事务日志。 globalTxLogManager = {GlobalTxLogManager} // 分布式事务的 connectionHolder 都是 TransactionConnectionHolder, // 里面分别存储了读写连接,读连接和写连接在提交时行为会有所不同。 connectionHolder = {TransactionConnectionHolder} // 物理分片到对应写连接的映射。 groupHeldWriteConn = {HashMap} // 物理分片到对应读连接集合到映射。在 ShareReadView 优化开启时, // 可以同时存在多个读连接和一个写连接,因此这里读写连接需要分开管理。 // 该优化不在本文展开。 groupHeldReadConns = {HashMap}
在执行器阶段,会选择给分片0下发一条SELECT语句,此时需要获取分片0的物理连接,代码入口是MyJdbcHandler中的getPhyConnection(ITransaction,ITransaction.RW,String,DataSource)方法。其中的事务对象Transaction则是从ExecutionContext里拿到。该方法最后会调用AbstractTransaction(这是所有分布式事务类的基类)中的getConnection方法。
通过事务拿物理连接的代码AbstractTransaction#getConnection如下:
// AbstractTransaction#getConnection(String, String, IDataSource, RW, ExecutionContext) public IConnection getConnection(String schema, String group, IDataSource ds, RW rw, ExecutionContext ec) { if (/* 是事务的第一个写请求 */) { // 把这个分片作为主分片,事务日志将写在这个分片上。 this.primaryGroup = group; // 该分片还用于生成 XA 事务的 xid。 this.primaryGroupUid = IServerConfigManager.getGroupUniqueId(schema, group); } // 通过 connectionHolder 拿到物理连接。 IConnection conn = connectionHolder.getConnection(schema, group, ds, rw); if (/* 是写请求 */ && !isCrossGroup && !this.primaryGroup.equals(group)) { // 事务涉及了多个分片。 this.isCrossGroup = true; } return conn; }
在我们的例子中,上述参数group是物理分片0,rw是READ,说明需要物理分片0上的读连接,ds则主要用于生成物理连接。由于我们只是读请求,因此分片0不会作为主分片,会直接返回connectionHolder.getConnection(schema,group,ds,rw)的结果。
通过连接管理器拿物理连接的代码TransactionConnectionHolder#getConnection如下:
// TransactionConnectionHolder#getConnection(String, String, IDataSource, RW) public IConnection getConnection(String schema, String group, IDataSource ds, RW rw) { // 尝试获取该分片上的写连接,如果有,直接返回这个写连接。 HeldConnection groupWriteConn = groupHeldWriteConn.get(group); if (groupWriteConn != null) { return groupWriteConn.connection; } HeldConnection freeReadConn = /* 尝试找到读连接 */; if (freeReadConn != null) { if (/* 当前需要写连接 */) { // 设置当前连接为写连接,participated = true 意味着该连接是写连接。 freeReadConn.participated = true; this.groupHeldWriteConn.put(group, freeReadConn); // 由于原本是读连接,这里才真正开启分布式事务。 this.trx.commitNonParticipant(group, freeReadConn.connection); this.trx.begin(schema, freeReadConn.group, freeReadConn.connection); } return freeReadConn.connection; } // 当前分片没有任何连接,创建一个新的连接。还会根据读写类型, // 设置好写连接 groupHeldWriteConn 或读连接集合 groupHeldReadConns。 IConnection conn = new DeferredConnection(/* 这里会获取并封装该分片的私有协议连接 */); if (/* 需要写连接 */) { // 开启正常的分布式事务。 this.trx.begin(schema, group, conn); } else { // 优化为只读事务。 this.trx.beginNonParticipant(group, conn); } return conn; }
在我们的例子中,由于是第一条语句,该分片上还没有任何连接,因此会先生成一个连接该分片的私有协议连接,包装成DeferredConnection,然后因为是读请求,会调用beginNonParticipant。
TsoTransaction的beginNonParticipant方法如下:
// TsoTransaction#beginNonParticipant(String, IConnection) protected void beginNonParticipant(String group, IConnection conn) throws SQLException { if (snapshotTimestamp < 0) { // 该事务从未拿过时间戳,则在这里获取。 snapshotTimestamp = nextTimestamp(); } // 使用私有协议的流水线执行机制执行 BEGIN。 conn.executeLater("BEGIN"); // 在 BEGIN 后发送时间戳。 sendSnapshotSeq(conn); }
在我们的例子中,私有协议连接会流水线执行BEGIN语句(非阻塞,不等结果返回),且在稍后执行物理SQL时才发送时间戳。至此,连接上的一些初始化操作已经完成,可以向执行器返回并执行读分片0的物理SQL。
3.写分片1
随后,我们执行UPDATE tb1 SET a = 100 WHERE id = 1。在执行器阶段,需要给分片1下发一条UPDATE语句,此时需要获取分片1的物理连接,因此又会调用AbstractTransaction#getConnection方法,通过事务对象拿物理连接。通过前面贴出的代码,我们发现由于是事务的第一个写请求,因此分片1会视作主分片,用于生成xid和稍后记录事务日志。
在获取物理连接时,又会调用TransactionConnectionHolder#getConnection方法,通过连接管理器拿物理连接。通过前面贴出的代码,我们发现由于分片1没有任何连接,因此会生成一个私有协议连接,包装成DeferredConnection。与读分片0不同,由于是写请求,会执行TsoTransaction的begin方法。
TsoTransaction的begin方法如下:
// TsoTransaction#begin(String, String, IConnection) protected void begin(String schema, String group, IConnection conn) throws SQLException { if (snapshotTimestamp < 0) { // 该事务从未拿过时间戳,则在这里获取。 snapshotTimestamp = nextTimestamp(); } // 获取 xid。 String xid = getXid(group); // 触发私有协议流水线执行 XA START。 conn.executeLater("XA START " + xid); // 在 XA START 后发送时间戳。 sendSnapshotSeq(conn); }
简单来说,和此前beginNonParticipant方法唯一的区别在于,使用了XA START开启事务。根据MySQL关于XA事务的说明,xid由gtrid[,bqual[,formatID]]组成,这里的gtrid是“drds-事务id @主分片Uid”,这样保证了同一个事务在不同分片上执行XA START,会使用相同的gtrid。bqual设置当前连接的分片,用于在事务恢复时确定分支事务所在的分片。在我们的例子中,xid为:'drds-13e101d74e400000@5ae6c3b5be613cd1','DB1_000001_GROUP',其中13e101d74e400000是事务id,5ae6c3b5be613cd1是分片1的Uid,DB1_000001_GROUP是分片1的具体分片名称。值得注意的是,这里会把之前的时间戳发送到分片1。至此,连接上的一些初始化操作已经完成,可以向执行器返回并执行写分片1的物理SQL。
4.COMMIT
最后,执行COMMIT提交事务。处理COMMIT的代码入口为ServerConnection#commit(),其主要调用了TConnection#commit方法,代码如下:
// TConnection#commit() public void commit() throws SQLException { try { // 触发事务的提交流程。 this.trx.commit(); } finally { // 大部分情况下,如果事务提交成功,或出现异常后正确处理了, // 所有连接会被关闭并释放,trx.close() 相当于什么也不做。 // 但如果事务提交失败且没有处理,这里会回滚事务并释放所有物理连接。 this.trx.close(); // 去掉对这个事务对象的引用,意味着当前连接里这个事务一生的结束。 this.trx = null; } }
我们重点关注一下事务的提交流程,上述this.trx.commit()调用时,会调用ShareReadViewTransaction(该类继承了AbstractTransaction,基于XA事务实现了共享readview的功能,XATransaction和TsoTransaction都会继承这个类,在这里可以简单理解为XA事务的基类)的commit方法,代码如下:
// ShareReadViewTransaction#commit() public void commit() { if (!isCrossGroup) { // 如果只涉及了单个分片的写,进行一阶段提交优化。 commitOneShardTrx(); } else { // 正常的多分片分布式事务提交流程。 commitMultiShardTrx(); } }
在我们的例子中,由于只写了分片1,所以进入一阶段提交优化,代码如下:
// ShareReadViewTransaction#commitOneShardTrx() protected void commitOneShardTrx() { // 对持有的所有物理连接执行以下流程,以提交每个物理连接开启的事务。 forEachHeldConnection((group, conn, participated) -> { if (!participated) { // 只读连接是 BEGIN 开启事务的,且只有读操作,执行 ROLLBACK 即可。 conn.execute("ROLLBACK"); } else { // 获取 xid。 String xid = getXid(group); // 写连接是 XA START 开启事务的,执行 XA END 和 XA COMMIT ONE PHASE 提交事务。 conn.execute("XA END " + xid + "; XA COMMIT " + xid + " ONE PHASE"); } }); // 所有连接都提交了分支事务,释放并清空这些物理连接。 connectionHolder.closeAllConnections(); }
我们一共持有了2个物理连接。对于分片0的只读连接,会直接执行ROLLBACK;对于分片1的写连接,则执行XA END和XA COMMIT ONE PHASE提交事务。注意到我们并没有获取commit timestamp,因为在一阶段提交优化里,commit timestamp会由InnoDB计算生成:
*具体的计算规则是:COMMIT_TS = MAX_SEQUENCE+1,其中MAX_SEQUENCE为InnoDB本地维护的历史最大的snapshot_ts。
如果提交失败了,会调用事务的close方法,代码如下:
// AbstractTransaction#close() public void close() { // 回滚所有物理连接上的事务。 cleanupAllConnections(); // 释放并清空这些物理连接。 connectionHolder.closeAllConnections(); }
值得一提的是,cleanupAllConnections()也是ROLLBACK语句主要调用的方法。因此为了同时了解ROLLBACK语句执行流程,我们也看一下cleanupAllConnections方法的代码:
// AbstractTransaction#cleanupAllConnections() protected final void cleanupAllConnections() { // 对持有的所有物理连接执行以下流程,以回滚每个物理连接开启的事务。 forEachHeldConnection((group, conn, participated) -> { if (conn.isClosed()) { return; } if (!participated) { // 只读连接是 BEGIN 开启事务的,且只有读操作,执行 ROLLBACK 即可。 conn.execute("ROLLBACK"); } else { // 获取 xid。 String xid = getXid(group); // 写连接是 XA START 开启事务的,执行 XA END 和 XA ROLLBACK 回滚事务。 conn.execute("XA END " + xid + "; XA ROLLBACK " + xid); } }); }
可以看到,回滚的逻辑是看情况执行ROLLBACK或XA ROLLBACK来回滚事务的。
至此,我们看到了事务1的一生。接下来看一下多分片写的事务流程。
五、事务2的一生
1.写分片0
事务2中,从开启事务到执行UPDATE tb1 SET a = 101 WHERE id = 1走的流程和事务1一样,直到执行UPDATE tb1 SET a = 101 WHERE id = 0时,才有所不同。具体而言,事务在之前就获取了分片0的只读连接,当执行到TransactionConnectionHolder#getConnection时,会先提交只读连接上的事务(实际执行了ROLLBACK),然后在这条连接上用XA START开启XA事务,设置好时间戳,就可以把这个物理连接返回给执行器,最终执行物理SQL。由于这是第二个写连接,因此还会设置事务为跨分片事务,以触发正常的两阶段提交流程。
2.COMMIT
事务2的重点在于写了2个分片,因此COMMIT时会调用commitMultiShardTrx()走多分片的分布式提交流程。方法commitMultiShardTrx代码如下:
// TsoTransaction#commitMultiShardTrx() protected void commitMultiShardTrx() { // 事务日志的提交状态,一共有 3 种:FAILURE,UNKNODWN,SUCCESS。 TransactionCommitState commitState = TransactionCommitState.FAILURE; try { // 对所有连接执行 XA prepare。 prepareConnections(); // 拿 commit 时间戳。 commitTimestamp = nextTimestamp(); Connection logConn = /* 获取主分片上的连接 */; // 所有分支事务 prepare 成功,在写事务日志前,状态设置为 UNKNOWN,其作用见后续代码说明。 commitState = TransactionCommitState.UNKNOWN; // 写事务日志。 writeCommitLog(logConn); // 写事务日志成功,状态置为 SUCCESS。 commitState = TransactionCommitState.SUCCESS; } catch (RuntimeException ex) { exception = ex; } if (commitState == TransactionCommitState.FAILURE) { // 写事务日志前失败了,回滚所有连接。 rollbackConnections(); } else if (commitState == TransactionCommitState.SUCCESS) { // 写事务日志成功了,提交所有连接。 commitConnections(); } else { // 所有连接都 prepare 成功了,但无法确定是否写入了事务日志, // 将由事务恢复的逻辑来决定是 COMMIT 还是 ROLLBACK。这里先丢弃所有连接。 discardConnections(); } // 释放并清空这些物理连接。 connectionHolder.closeAllConnections(); // prepare 或 commit 阶段抛出的异常,这里重新抛出。 if (exception != null) { throw exception; } }
上述代码正是两阶段提交的流程。
在prepare阶段,调用prepareConnections(),其中对只读连接只是简单执行ROLLBACK语句;对于写连接,执行XA END {xid}和XA PREPARE {xid}语句。
如果所有连接都prepare成功了,在commit阶段,调用writeCommitLog(logConn),用主分片(在我们的例子中,是分片1)的连接,写下事务日志,主要包括了事务的id和commit时间戳,事务日志主要用于后续的事务恢复。
如果事务日志写成功了,就意味着commit成功了,会调用commitConnections()对所有连接进行提交,这一步只用对写连接设置commit时间戳SET innodb_commit_seq = {commitTimestamp}和执行XA COMMIT {xid}语句。
如果在写事务日志前失败了,会调用rollbackConnections()对所有连接进行回滚,主要会对写连接执行XA ROLLBACK {xid}回滚。
如果无法确定是否成功写入了事务日志,事务的状态会是UNKNOWN。此时,我们能确定所有分支事务都成功prepare了,如果事务日志写入成功了,则要进行XA COMMIT;如果事务日志没有写入,则要进行XA ROLLBACK。由于不确定是要提交还是回滚,我们会丢弃所有物理连接,使这些连接后续不再可用。至于事务最终是提交还是回滚,则交给事务恢复线程来处理,接下来我们会解读事务恢复相关的代码。
3.事务恢复
一个分布式事务在提交的时候,可能遇到各种情况导致提交失败。例如,所有分支事务都prepare成功了,事务日志也写入成功了,但XA COMMIT失败了。对于这种情况,事务恢复时需要正确提交所有分支事务。另一种情况是,部分分支事务prepare成功了,另外一些失败了,或事务日志没有写入成功。对于这种情况,事务恢复需要回滚掉已prepare的分支事务。
事务恢复主要由XARecoverTask负责。其主体代码为recoverInstance方法,该方法检查一个DN下的所有prepare过的事务,并根据事务状态提交或回滚这些事务,代码如下:
// XARecoverTask#recoverInstance(IDataSource, Set<String>) // dataSource 用户获取 DN 的连接,groups 是当前逻辑库的所有物理分片 private void recoverInstance(IDataSource dataSource, Set<String> groups) { // 执行 XA RECOVER 获取该 DN 上所有 prepare 的事务。 // 此处省略了从 dataSource 获取连接和生成 statement 的代码。 ResultSet rs = stmt.executeQuery("XA RECOVER"); while (rs.next()) { // 对每一条记录,生成对象 PreparedXATrans, // 主要包括 xid,事务id,分支事务所在的分片,主分片等信息。 PreparedXATrans trans = /* 从 rs 中获取一行数据生成 */; if (/* trans 所在分片是当前逻辑库的一个物理分片 && trans 在上一次 recover 任务时也出现过, 即较长时间都未被提交或回滚*/) { // 介入处理这个分支事务:回滚或提交。 rollBackOrForward(trans, stmt); } } }
该任务每5秒到每个DN上执行一次XA RECOVER,得到所有prepare过的事务,如果看到一个事务在上一次任务中也出现过,即至少过去5秒都没有提交或回滚,则会选择对这个事务进行回滚或提交。相关逻辑代码为rollBackOrForward,代码如下:
// XARecoverTask#rollBackOrForward(PreparedXATrans, Statement) private boolean rollBackOrForward(PreparedXATrans trans, Statement stmt) throws SQLException { String primaryGroup = /* 从 trans 里解析出主分片,详见前文关于 xid 的生成 */; // 尝试从主分片的事务日志中找到相关的事务日志。 GlobalTxLog tx = GlobalTxLogManager.get(primaryGroup, trans.transId); if (tx != null) { // 确实存在事务日志,根据事务日志状态判断回滚或提交。 if (tx.getState() == TransactionState.ABORTED) { // ABORTED 状态的事务需要回滚。 return tryRollback(stmt, trans); } else { // SUCCESS 状态的事务需要提交。 return tryCommitTSO(stmt, trans, tx.getCommitTimestamp()); } } else { // 没有找到事务日志,尝试回滚,先开启事务,写下事务日志,标记事务为 ABORTED。 try (Connection conn2 = /* 获取主分片上的另一个连接 */;) { conn2.setAutocommit(false); // 尝试回滚,如果因为别的线程正在处理这个事务 //(比如该事务只是提交得慢,连接仍未断开,还在提交流程) // 而报错,就回滚上一条写事务日志的语句。 txLog.append(transInfo.transId, TransactionType.XA, TransactionState.ABORTED, new ConnectionContext(), conn2); stmt.execute("XA ROLLBACK " + trans.toXid()); conn2.commit(); return true; } catch (Exception e) { /* 根据异常判断是否要回滚写事务日志的操作 */ } } }
该方法主要有3段逻辑。
一是如果存在对应的事务日志,且事务状态是ABORTED,那就执行tryRollback方法回滚,该方法主要执行了XA ROLLBACK {xid}。
二是如果事务状态是SUCCESS,那就执行tryCommitTSO方法回滚,该方法会设置commit时间戳,然后执行XA COMMIT {xid}。
三是如果没找到事务日志,此时一般有两种可能:
事务提交失败了,且没写下事务日志,此时需要回滚。
事务还在两阶段提交的流程中,只是prepare较慢,还没开始写事务日志,此时不需要做任何操作。
在MySQL中,如果发起XA START的连接没有关闭,其他连接是无法通过XA ROLLBACK或XA COMMIT来回滚或提交这个分支事务的。我们利用这一特性,首先在事务日志插入一条ABORTED记录,表明这个分布式事务需要回滚,然后尝试执行XA ROLLBACK回滚这个分支事务。
如果遇到2)的情况,则会收到特定的报错,此时再回滚掉插入ABORTED事务日志的操作。在我们插入ABORTED事务日志后,原本正在提交事务的线程在插入SUCCESS事务日志时会被阻塞,而在我们回滚掉插入ABORTED事务日志的操作后,事务提交流程就会继续进行下去。
六、小结
本文主要解读了PolarDB-X中CN端的事务相关的代码,以TSO事务为主,使用两个例子,一步步地展示了事务的开启、执行、提交、恢复等流程。希望大家阅读本文后,能更加了解PolarDB-X的事务系统。



