我们在爬虫作业的时候,经常会遇到HTTP返回错误代码,那这些错误代码代表了什么意思呢?爬虫作业的时候又该如何避免这些问题,高效完成我们的项目?
1.403 Forbidden
这个状态码表示服务器理解客户端的请求,但是拒绝提供服务。这通常是因为服务器已经检测到了恶意爬虫,并已经禁止了其访问。
2.404 未找到
这个状态码表示服务器无法找到客户端请求的资源。虽然这通常不是针对爬虫的禁止,但它可能是由于爬虫访问了一个不存在的页面或被网站管理员删除的页面。
3.418 I'm a teapot
虽然这个状态码实际上是作为一个玩笑而出现的,但它也被用来表示服务器拒绝提供服务。这可能是因为服务器检测到了恶意爬虫或其他异常访问。
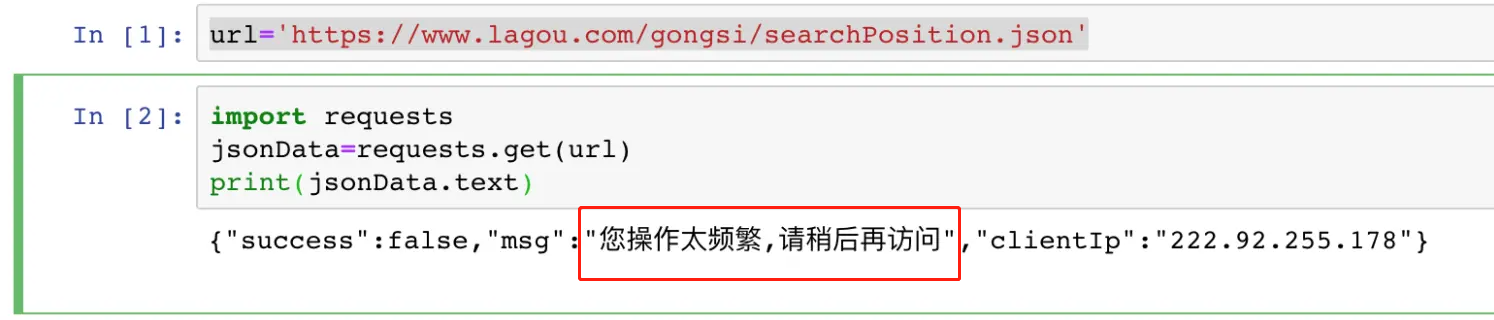
4.429 太多的请求
这个状态码表示客户端发送的请求太频繁了。这通常是因为服务器已经检测到了过度使用的爬虫,并已经限制了其访问速率。
5.503 Service Unavailable
这个状态码表示服务器目前无法处理客户端的请求。这可能是由于服务器过载、维护或其他原因导致的,但也可能是服务器禁止了爬虫的访问。
那我们在爬虫作业的时候,要提前准备什么,来让我们的项目进展顺利呢?
1.robots.txt文件
在进行网站爬取之前,我们需要了解目标网站是否允许爬虫访问,以避免违反网站协议。每个网站都有一个robots.txt文件,用于告诉搜索引擎和其他爬虫哪些页面可以访问,哪些页面不能访问。因此,在开始爬取网站之前,我们需要检查这部分的文件,确保自己需要的数据在可访问的范围呢。
2.User-Agent
在爬虫中设置 User-Agent 可以模拟不同的浏览器来访问网站,以避免被网站识别为爬虫并阻止访问。通常情况下,User-Agent可以设置为任何一个浏览器的标识字符串,我们需要在请求头中添加 User-Agent 字段,方法如下:
Pythonrequestsku:importrequestsheaders= { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'} response=requests.get(url, headers=headers)
在上面的代码中,User-Agent 的值设置为 Chrome 浏览器的标识字符串。也可以根据需要更改它以模拟其他浏览器。
3.模拟行为
网站管理员通常会监视网站上的异常活动,如高速连续访问,所以我们需要尽可能地模拟正常用户的访问。为此,我们可以使用随机等待时间和随机的点击行为,可以随机地在网站上浏览不同的页面,或者在请求之间随机地停留一段时间,以模拟用户的行为。
4.适合自己的爬虫工具
磨刀不误砍柴工,在进行网站爬取之前,我们需要选择一个适合自己的爬虫工具。一些常用的爬虫工具包括Python中的Beautiful Soup和Scrapy,Node.js中的Cheerio和Puppeteer,Java中的Jsoup和Webmagic等。举个例子,如果我们需要一个非常灵活的爬虫工具,可以考虑使用Scrapy。如果需要一个简单而功能强大的HTML解析器,可以使用Beautiful Soup。如果需要使用JavaScript进行网站爬取,可以考虑使用Puppeteer。
5.使用多线程
使用多线程可以大大提高网站爬取的效率。在进行网站爬取时,我们可以使用多个线程同时发送请求,这样可以更快地获取所需的数据。然而,在使用多线程时,我们需要注意线程数量的控制,避免过多的线程导致服务器负载过高而影响正常的网站服务。另外,在多线程爬取时,我们还需要注意线程之间的同步和数据共享问题,以确保数据的准确性和完整性。
6.使用代理
有些网站可能会对来自同一地址的高频请求进行限制,因此我们可以使用HTTP代理来分散请求。但,问题来了,又的HTTP代理提供的节点可选范围很小,或者为了介于成本,提供的节点只在某一些特定的偏远地区,或者干脆可用率极低,使用起来非常不方便,我们要如何在一众厂商中挑选到适合我们的呢?
这里我会比较推荐青果网络的HTTP代理。无论是从结果来看:

(并发)

(隧道成功率)
而且他们家的产品价格也很实诚,不像有的厂商价格高到离谱:

近期看他们还开发了企业池,看介绍是由日去重达到220+W。
这时候,就有人要说啦,哎呀我看人家都是说千万IP的。怎么说呢,也看看咱自己的业务体量对吧,不是越大越好,羊毛总是出在羊身上。

