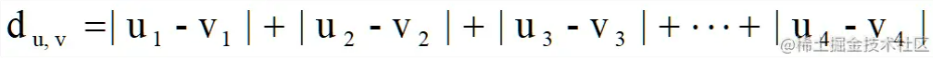许多算法,无论是监督或非监督,都使用距离度量。这些度量,如欧几里得距离或余弦相似度,经常可以在k-NN、UMAP、HDBSCAN等算法中找到。
理解距离测量域比你可能意识到的更重要。以k-NN为例,这是一种经常用于监督学习的技术。作为默认值,它通常使用欧几里得距离。它本身就是一个很大的距离。
但是,如果您的数据是高维的呢?那么欧几里得距离还有效吗?或者,如果您的数据包含地理空间信息呢?也许haversine 距离是更好的选择!
知道何时使用哪种距离量度可以帮助您从分类不正确的模型转变为准确的模型。
在本文中,我们将研究许多距离度量方法,并探讨如何以及何时最佳地使用它们。最重要的是,我将谈论它们的缺点,以便您可以识别何时避开某些措施。
注意:对于大多数距离度量,可以并且已经针对其用例,优点和缺点编写了详尽的论文。我会尽量覆盖,但可能会有所欠缺!因此,请将本文视为这些方法的概述。
欧氏距离 Euclidean Distance

我们从最常见的距离度量开始,即欧几里得距离。最好将距离量度解释为连接两个点的线段的长度。
该公式非常简单,因为使用勾股定理从这些点的笛卡尔坐标计算距离。

缺点
尽管这是一种常用的距离度量,但欧几里德距离并不是比例不变的,这意味着所计算的距离可能会根据要素的单位而发生偏斜。通常,在使用此距离度量之前,需要对数据进行标准化。
此外,随着数据维数的增加,欧氏距离的用处也就越小。这与维数的诅咒有关,维数的诅咒与高维空间不能像期望的二维或3维空间那样起作用。
用例
当您拥有低维数据并且向量的大小非常重要时,欧几里得距离的效果非常好。如果在低维数据上使用欧几里得距离,则kNN和HDBSCAN之类的方法将显示出出色的结果。
尽管已开发出许多其他措施来解决欧几里得距离的缺点,但出于充分的原因,它仍然是最常用的距离之一。它使用起来非常直观,易于实现,并且在许多用例中都显示出了极好的效果。
余弦相似度Cosine Similarity

余弦相似度经常被用作解决高维数欧几里德距离问题的方法。余弦相似度就是两个向量夹角的余弦。如果将向量归一化为长度均为1,则向量的内积也相同。
两个方向完全相同的向量的余弦相似度为1,而两个彼此相对的向量的相似度为-1。注意,它们的大小并不重要,因为这是方向的度量。

缺点
余弦相似度的一个主要缺点是没有考虑向量的大小,而只考虑它们的方向。在实践中,这意味着没有充分考虑价值的差异。以一个推荐系统为例,余弦相似度没有考虑到不同用户之间评分尺度的差异。
用例
当我们对拥有的高维数据向量的大小不关注时,通常会使用余弦相似度。对于文本分析,当数据由字数表示时,此度量非常常用。例如,当一个单词在一个文档中比另一个单词更频繁出现时,这并不一定意味着一个文档与该单词更相关。可能是文件长度不均匀,计数的重要性不太重要。然后,我们最好使用忽略幅度的余弦相似度。。
汉明距离 Hamming Distance

汉明距离是两个向量之间不同值的个数。它通常用于比较两个相同长度的二进制字符串。它还可以用于字符串,通过计算不同字符的数量来比较它们之间的相似程度。
缺点
如您所料,当两个向量的长度不相等时,很难使用汉明距离。为了了解哪些位置不匹配,您可能希望比较相同长度的向量。
此外,只要它们不同或相等,就不会考虑实际值。因此,当幅度是重要指标时,建议不要使用此距离指标。
用例
典型的用例包括数据通过计算机网络传输时的错误纠正/检测。它可以用来确定二进制字中失真的数目,作为估计误差的一种方法。
此外,您还可以使用汉明距离来度量分类变量之间的距离。
曼哈顿距离 Manhattan Distance

曼哈顿距离,通常称为出租车距离或城市街区距离,计算实值向量之间的距离。想象描述均匀网格(如棋盘)上物体的向量。曼哈顿距离是指两个矢量之间的距离,如果它们只能移动直角。在计算距离时不涉及对角线移动。

缺点
尽管曼哈顿距离在高维数据中似乎可以工作,但它比欧几里得距离更不直观,尤其是在高维数据中使用时。
此外,由于它不是可能的最短路径,它比欧几里得距离更有可能给出一个更高的距离值。虽然这并不一定会带来问题,但这是你应该考虑的。
用例
当数据集具有离散和/或二进制属性时,Manhattan似乎工作得很好,因为它考虑了在这些属性的值中实际可以采用的路径。以欧几里得距离为例,它会在两个向量之间形成一条直线,但实际上这是不可能的。
切比雪夫距离 Chebyshev Distance

切比雪夫距离定义为两个向量在任意坐标维度上的最大差值。换句话说,它就是沿着一个轴的最大距离。由于其本质,它通常被称为棋盘距离,因为国际象棋的国王从一个方格到另一个方格的最小步数等于切比雪夫距离。

缺点
切比雪夫通常用于非常特定的用例,这使得它很难像欧氏距离或余弦相似度那样作通用的距离度量,因此,建议您只在绝对确定它适合您的用例时才使用它。
用例
如前所述,切比雪夫距离可用于提取从一个正方形移动到另一个正方形所需的最小移动次数。此外,在允许无限制八向移动的游戏中,这可能是有用的方法。
在实践中,切比雪夫距离经常用于仓库物流,因为它非常类似于起重机移动一个物体的时间。