开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop框架搭建)第四阶段:数据预处理-历史爬虫判断-实现代码及效果】学习笔记,与课程紧密联系,让用户快速学习知识。
课程地址:https://developer.aliyun.com/learning/course/672/detail/11666
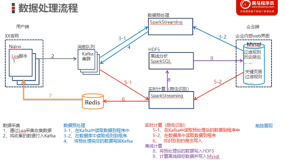
数据预处理-历史爬虫判断-实现代码及效果
历史爬虫判断
一步一步实现过程,首先第一步读取数据库中历史出现过的黑名单到程序中,依然到程序初始化阶段,前面都是从数据库里读数据,在数据初始化阶段读,现在要读取历史出现过的黑名单数据也一样。
1、判断是否在历史爬虫出现过(高频 ip)
//读取黑名单-高频 IP 的数据
var blackIPList=AnalyzeRuleDB.getBiacklpDB()
@volatile var broadcastBlackIPList=sc.broadcast(blackIPList)
来实现读取黑名单的数据
//1读取数据库内历史出现过的黑名单数据到预处理程序中
AnalyzeRuleDB.getBiackIpDB()
数据方法现在没有,直接自动来创建,括号里面自动补全粘贴到最后面。

读取字段可以借用上面的思路,给一个 sql,给一个字段,然后接收一下就可以。
} catch {
case e: Exception => e.printstackTrace()
} finally{
c3poutil.close(conn,ps, rs)
}
analyzeRuleList.toList
}
//实现历史出现过的黑名单读取到程序
//拿数据库中一个字段读取
def getBiackIpDB():Unit ={
//读取黑名单的 sql
val sql="select ip name from itcast ip blacklist'
//接受数据的字段
val field="ip name"
//调用 QueryDB 读取数招
val blackIpList=QueryDB.queryData(sqlfield
//返回过滤数据
blackIpList
}
}
到 process 里面:
////1读取数据库内的数据解析规则到预处理程序(将表内的所有查询规则数据全部读取到程序内)
//数据解析规则--查询类
var queryRule=AnalyzeRuleDB.queryRule(behaviorType=0)
//2将规则加载到广播变量
@volatile var broadcastOueryRules=scbroadcast(queryRule)
//数据解析规则-- 预定类
var bookRule=AnalyzeRuleDB.queryRule(behaviorType=1)@volatile var broadcastBookRules=scbroadcast(bookRule
//1读取数据库内历史出现过的黑名单数据到预处理程序中
var blackIpList=AnalyzeRuleDB.qetBiackIpDB()
//2将历史爬虫添加到广播变量、并循环判断是否需要更新(内含多个步骤,此处省略)
@volatile varbroadcastBlackIpList= sc.broadcast(blackIplist)
//4、读取kafka内的数据ssc,kafkaParamstopics)
val kafkaData=KafkaUtils.createDirectstream[string,string,stringDecoder,stringDecoder](ssc,kafkaParams,topics)
//真正的数据
val kafkaValue=kafkaData.map(_._2)
//5、消费数据
kafkaValue.foreachDD(rdd=>{//迭代运行(每2秒运行一次)
//到 redis 读取是否需要更新的标记
val NeedUpDateFilterRule=redis.get("NeedUpDateFilterRule")
//判断是否需要更新若数据不为空并且数期转成 Boolean 为 true表示需要更新
if(!NeedUpDateFilterRule.isEmpty&&NeedUpDateFilterRuletoBoolean){
//若需要更新,那么在数据库中重新读取新的过滤规则到程序中 filterRuleList=AnalyzeRuleDB.queryFilterRule()
//将广播变量清空
broadcastFilterRuleList.unpersist()
//将新的规则重新加载到广播变量
broadcastFilterRuleList=scbroadcast(filterRuleList)
//将 redis 内是否需要更新规则的标识改为“false”
redis.set("NeedUpDateFilterRule","false")}
//到 redis 读取是否需要更新的标记
val NeedUpDateClassifyRule=redis.get("NeedUpDateclassify Rule")
//判断是否需要更新 若数据不为空并目数据转成 Booleantrue 表示需要更新
if(lNeedUpDateClassifyRule.isEmpty &&NeedUpDateClassifyRu letoBoolean){
//若需要更新,那么在数据库中重新读取新的四种业务规则到程序中 RuleMaps=AnalyzeRuleDB.queryRuleMap()
//将广播变量清空
broadcastRuleMaps.unpersist()
//将新的分类规则重新加载到广播变量
broadcastRuleMaps=scbroadcast(RuleMaps)
//将redis内是否需要更新规则的标识改为“false” redis.set("NeedUpDateClassifyRule","false")
//环判断是否需要更新(内含多个步弹,此处省略)
val needUpDataAnalyzeRule=redis.get("NeedUpDataAnalyze Rule")
//如果获取的数据是非空的,并且这个们是true,那么就进行数据的更新操作(在数据库中重新读取数据加载到Redis)
if(!needUpDataAnalyzeRule.isEmpty&&needUpDataAnalyzeRule.toBoolean)
//重新读取mysql的数据
queryRule=AnalyzeRuleDB.queryRule(behaviorType=0) bookRule=AnalyzeRuleDB.queryRule(behaviorType=1)
//清空广播变最中的数据
broadcastQueryRules.unpersist(() broadcastBookRules.unpersist()
//重新载入新的过滤数据
broadcastQueryRules=sc.broadcast(queryRule) broadcastBookRules=scbroadcast(bookRule)
//更新完毕后,将 Redis 中的 true 改成 false
redis.set("NeedUpDataAnalyzeRule","false")
}
//判断是否需要更新历史黑名单数据
val NeedUpDateBlackIPList=redis.get("NeedUpDateBlackIPList ")
if(!NeedUpDateBlackIPList.isEmpty &&NeedUpDateBlackIPListt oBoolean){
blackIpList=AnalyzeRuleDB.getBiackIpDB() broadcastBlackIpList.unpersist()
broadcastBlackIpList=scbroadcast(blackIpList) redis.set("NeedUpDateBlackIPList","false")
}
添加 Key:

添加成功:

//1链路统计功能
LinkCount.linkCount(rdd)
//2 数据清洗功能
//定义方法,参数为一条数据和广播变量
val filteredData=rdd.filter(message=>URLFilter.filterURL(mess age,broadcastFilterRuleList.value))
//filteredData.foreach(println)
//数据预处理
//数据脱敏建立在数据清洗之后
val DataProcess=filteredData.map(message=>{
//3数据脱敏功能
//3-1手机号码脱敏
val encryptedPhone=EncryptedData.encryptedPhone(messag e)
//3-2 身份证号码脱敏
val encryptedId=EncryptedData.encryptedId(encryptedphone)
//encryptedId
//4数据拆分功能(一劳永逸)
val(requesturl,requestMethod,contentTyperequestBodyhttpReferrer,remoteAddr,httpUserAgent,timeIso8601, serverAddr.cookiesStr.cookieValue JSESSIONIDcookieValue US ERID)=DataSplit.dataSplit(encrvptedid)
//requestMethod
//5数据分类功能(打标签)
//5-1 飞行类型与操作类型
//操作类型:0查询1预订航班类型:0国内1国际
//0 0 国内查询
//0 0 国际查询
//1 0 国内预定
//1 1 因际预定
//定义方法,参数为经过拆分后的 URL 和分类的广播变量
val requestType: RequestType=RequestTypeclassifier.classifyb yrequest(requesturlbroadcastRuleMaps.value)
//requestType
//5-2 单程/往返
val travelType:TravelTypeEnum=TravelTypeClassifier.classifyByRefererAndRequestBody(httpReferrer)
//travelType
//6 数据的解析
//6-1 查询类数据的解析
//1前面
//2前面
//3对数据进行解析(在多种解析规则的情况下,确定最终使用哪一个规则进行解析)
val queryRequestData =AnalyzeRequest.analyzeQueryRequest (requestType,requestMethod,contentType
requesturl,requestBody,travelTypebroadcastQueryRulesvalue)
val data=queryRequestData match{
case Some(datas)=> datas.flightDate
data
//6-2 预定类数据的解析
val bookRequestData =AnalyzeBookRequest.analyzeBokReq uest(requestType,requestMethod,
contentType,requestUrlrequestBody,travelType,broadcastBookRules.value)
//7 历史爬虫判断
//1
//2
//3将数据中的 ip 与历史出现过的黑名单 IP 数据进行对比,判断是否相等
Ipoperation.isFreIP(remoteAddr,broadcastBlackIpList.value)
//4若有任意一个是相等的返回 true,反之返回 false
//8 数据结构化
})
DataProcess.foreach(println)
Operation 创建一下 dataprocess-businessprocess 新建 Scala 的 object

package com.air.antispider.stream.dataprocess.businessproc ess
//用于实现数据是否在历史黑多单出现过
object Ipoperation {
//判断数据是否在历史黑名单出现边
def isFreIP(remoteAddr: String,blackIpList:ArrayBuffer[strin g]):Boolean={
//4若有任意一个是相等的返回 true,反之返回 false
//实例变量表示数据是否在历史黑名单出现过
var isFreIP=false
//遍历每一个历史出现过的 IP
for(blackIp<-blackIpList){
//表示出现过
if(remoteAddr.equals(blackip)){
isFreIP=true
}
}
isFreIP
}
}
历史黑名单数据处理完,前面接收:
//7 历史爬虫判断
//1
//2
//3将数据中的 ip 与历史出现过的黑善单 IP 数据进行对比,判断是否相等
val isFreIP=IpOperation.isFreIP(remoteAddrbroadcastBlackIpLi st.value) isFreip
//8 数据结构化
})
DataProcess.foreach(println)
运行程序:

没有报错
运行爬虫:

黑名单数据没有192、168,没有历史出现过,数据现在是服务器的IP 或者用户的 IP 段是192.168.100网段,没有会返回 false,

所以肯定没有返回 false。看到 false 爬虫是否在历史爬虫中出现过的功能就做完了,也已经看到效果。

2、总结
目标:结合历史出现过的爬虫数据,判断当前批次的每一条数据是否在历史爬虫中出现过。若出现过,返回 True 反之返回 False
思路与关键代码:
(1)读取数据库内历史出现过的里名单数据到预处理程序中
var b1ackIpList=AnalyzeRuleDB.getBiackIpDB()
(2)将历史爬虫添加到广播变量、并循环判断是否需要更新(内含多个步骤,此处省略)
@volatile var broadcastBlackIpList=scbroadcast(blackIpList)
va1 NeedUpDateBlackIPList=redis.get("NeedUpDateBlackIPList ")
if(!NeedUpDateBlackIPList.isEmpty&& NeedUpDateBlackIPListtoBoolean){
blackIpList=AnalyzeRuleDB.aetBiackIpDBO broadcastBlackIpList.unpersist
broadcastBlackIpList=scbroadcast(blackIpList) redis.set("NeedUpDateBlackIPList","false")
}
(3)将数据中的 ip 与历史出现过的黑名单 IP 数据进行对比,判断是否相等
va1 isFreIP=IpOperation.isFreIP(remoteAddrbroadcastBlackIpL ist.value)
(4)若有任意一个是相等的返回 true,反之返回 false
var isFreIP=false
//遍历每一个历史出现过的 IP
for(blackIp<-blackIpList){
//表示出现过
if(remoteAddr.equa1s(b1ackIp)){
isFreIP=true
}
}